devWonny
2025. 5. 22. 22:10
Retrieval-Augmented Generation
검색 기반 생성
GPT 같은 언어 생성 모델(LM)이 외부 지식에 접근할 수 있게 해주는 아키텍처
🔄 작동 흐름
- 사용자 질문 입력
→ 예: "삼성전자 주가가 오늘 얼마야?" - 검색 (Retrieval)
→ 벡터 DB나 웹 검색 등에서 관련 문서를 찾아옴 (예: 최신 뉴스, 주가 데이터) - 문서 선택 및 요약
→ 검색된 결과 중 일부를 선별하고, 중요 문맥만 추출 - 생성 (Generation)
→ GPT 모델이 그 문서들을 바탕으로 자연어 응답을 생성
준비 단계

실행 단계

🔄 ChatGPT만 사용
 |
우리가 질문을 한다 프롬프트에 질문 내용이 전달된다 |
 |
프롬프터를 LLM에게 전달한다 |
 |
LLM이 생성한 답변 |
| 할루네이션이 존재함 제대로 된 답변이 안나옴 |
최신정보가 없기 때문이다. |
🔄 RAG 적용
 |
프롬프트에 실직적으로 들어가는 내용을 수정한다 |
 |
프롬프터가 바뀜 참고할 만한 정보를 제공함 내가 사전에 주는 정보에서 찾는다 알면 알고 모르면 모른다 |
 |
context에서 검색해서 답변을 한다 |
 |
최신 답변을 할 수 있음. 참고할 만한 정보를 제공함 |
🔧 RAG
기존의 GPT 모델은 훈련 시점까지의 지식만 가지고 답을 생성하지만,
RAG는 필요한 정보를 외부에서 검색해와서 그걸 바탕으로 답을 생성합니다.
🧪 대표 사용 사례
- 사내 문서 기반 Q&A 시스템
- PDF/노션/위키 문서 요약 + 검색
- 고객상담 챗봇에서 이전 대화 이력 반영
🧠 RAG 왜 쓰나?
- 최신 정보 반영 가능 (ex. 실시간 뉴스, 내부 문서 등)
- GPT의 "환각(hallucination)"을 줄일 수 있음
- 도메인 특화 지식 (사내 문서, 기술 매뉴얼 등)을 활용 가능
🧰 RAG 구성 요소
| 구성 요소 | 설명 |
| 사전 단계: Query Encoder | 질문을 벡터로 인코딩 |
| 사전 단계: Vector DB | 문서들을 벡터화해서 저장 (ex. FAISS, Weaviate) |
| 실행 단계: Retriever | 질문과 유사한 문서를 찾아줌 |
| Generator (GPT) | 문서를 참고해서 자연어 응답 생성 |
RAG 사전 단계, 필요성
 |
pdf 파일을 rag를 한다고하면 이 페이지가 23페이지다. 그러면 모든 글을 읽어야한다. gpt한테 이 모든 것에서 찾아서 내가 원하는 답변을 찾아달라고 하면 비효율적이다. |
| 굉장히 많은 비용이 잡힌다. | 우리가 질문을 할때마다 23페이지에 있는 글자 모두를 프롬프터에 들어가야한다. 그러면 입력은 다 비용과 관련되어있어서 비싸진다. 질문 하나당 비용이 비싸진다 |
| lost in the middle : 중간에 길을 잃어버린다. --> 관련성 있는 정보의 페이지만 제공한다 |
gpt가 이렇게 많은 정보를 주면, 내가 어디서 이 정보를 찾아야할지 모른다. -> 13페이지만 제공하면 한번에 필요한 정보를 찾을 수 있다. |
필요한 정보만 골라서 빼서 -> LLM에게 넣어주는 것이 가장 효율적
RAG 사전 단계


1. pdf 파일의 문자를 모두 읽어온다
2. 작은 단위로 글자를 나눈다
- chunk 로 만든다
3. Embedding 유사도 검사
- 66단락에서 유사도를 계산해서, 가장 높은 관련도 단락을 뽑아낸다.
 |
Embed특정한 것을 --> 벡터로 바꾸는 것(차원) |
 |
Embed0.7을 기준으로0.6이 가까울까? 1.9가 가까울까? |
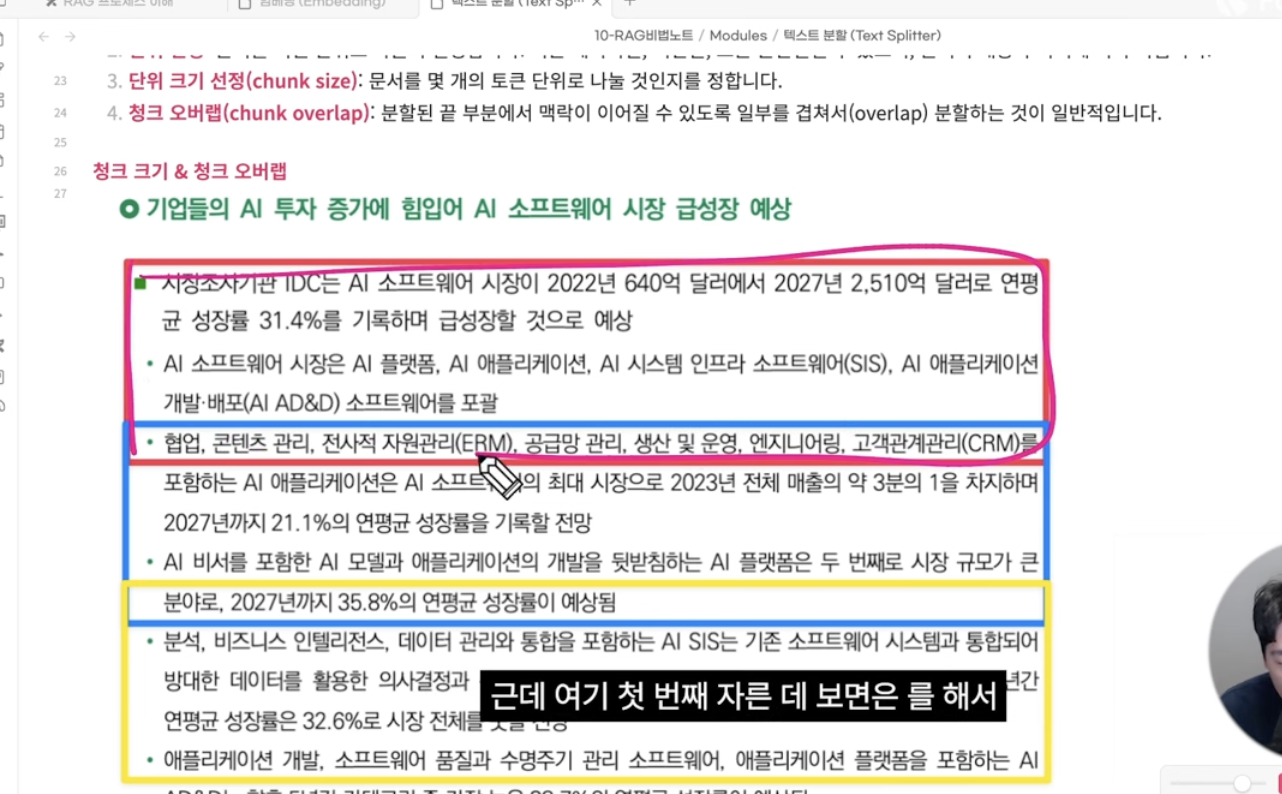 |
Splitchunk 1000 으로 하면겹쳐처 짤려진다 중간에 짤리는 글자 없이 하려고 겹치게 자른다 |
 |
Vector임베딩단락을 벡터로 바꾼다 |
 |
Vector Store벡터를 저장해야한다.embeding 할때마다 돈이 든다. 처음 한번만 한다. |
RAG 실행 단계

Retriever 검색기:
저장된 벡터 database에서 사용자의 질문과 관련된 문서를 검색하는 과정
사용자 질문에 가장 적합한 정보를 신속하게 찾아내는 것이 목표.
RAG 시스템의 전반적인 성능과 직결과는 매우 중요한 과정
Retriever 검색기 필요성:
1. 정확한 정보 제공
2. 응답 시간 단축
3. 최적화
 |
retriever 검색기retriever 검색기 한테 요청을 한다. 1) 유사도 검사 |
 |
유사도 검사질문을 embed 해서저장된 embed 중에서 가장 유사한 단락을 찾는다 상위 문서 선정 k=5 라면 유사한 단락 5개를 뽑는다. |
| 구분 | Sparse Retriever | Dense Retriever |
| 기준 | 단어 매칭 | 의미 매칭 (벡터 유사도) |
| 장점 | 빠르고 해석 쉬움 | 의미 기반, 유연성 높음 |
| 단점 | 단어가 안 맞으면 못 찾음 | 벡터화 비용, 학습 필요 |
| 예시 기술 | BM25, TF-IDF | DPR, OpenAI Embedding + FAISS |
1) 🧹 Sparse Retriever (keyword 검색)
- "단어 기반 검색"
- 네이버/구글에서 키워드로 검색하는 방식이랑 비슷해.
- 문서에서 단어가 정확히 포함돼 있어야 찾아짐.
🧠 예:
질문이 "삼성전자 주가"이면,
문서에도 '삼성전자', '주가'라는 단어가 있어야 검색돼.
🧰 대표 기술:
- TF-IDF
- BM25 (Lucene 검색 엔진에서 많이 씀)
2)💡 Dense Retriever (vector 공간 의미 기반 검색)
- "의미(embedding) 기반 검색"
- 질문과 문서 둘 다 벡터(숫자 배열)로 바꿔서,
의미적으로 비슷한지 비교함
🧠 예:
질문: "삼성전자 오늘 주식 얼마야?"
문서: "삼전의 금일 주가 정보는..."
→ 단어는 달라도, 의미가 비슷하니까 검색 가능!
🧰 대표 기술:
- DPR (Dense Passage Retrieval, Facebook)
- OpenAI embedding + FAISS


프롬프터: 콘텍스트가 추가된다.
RAG 실습

모듈 설치





