1) rest api 설명
블로그 글로 조사하고 공부하면 다들 복사해 오느냐고 정확하게 모르는거같다.
rest api 스러운 방법에 대한 글이 많다.
https://www.youtube.com/watch?v=Nxi8Ur89Akw
그런 점에서 정님은 저자의 블로그나 논문을 읽고 준비를 하다니...... 나처럼 블로그에 의존하면 잘못된 정보를 믿게 된다.











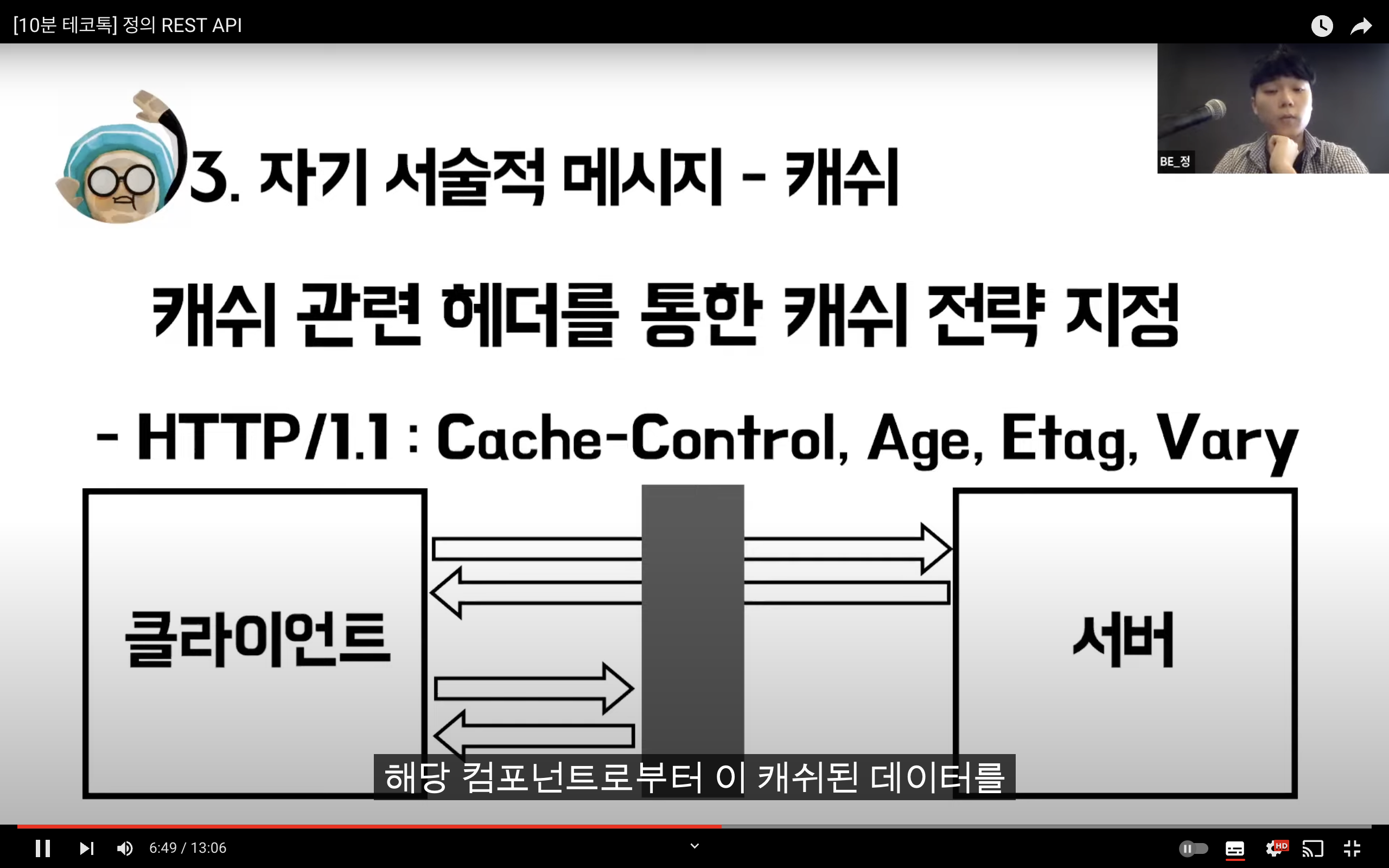
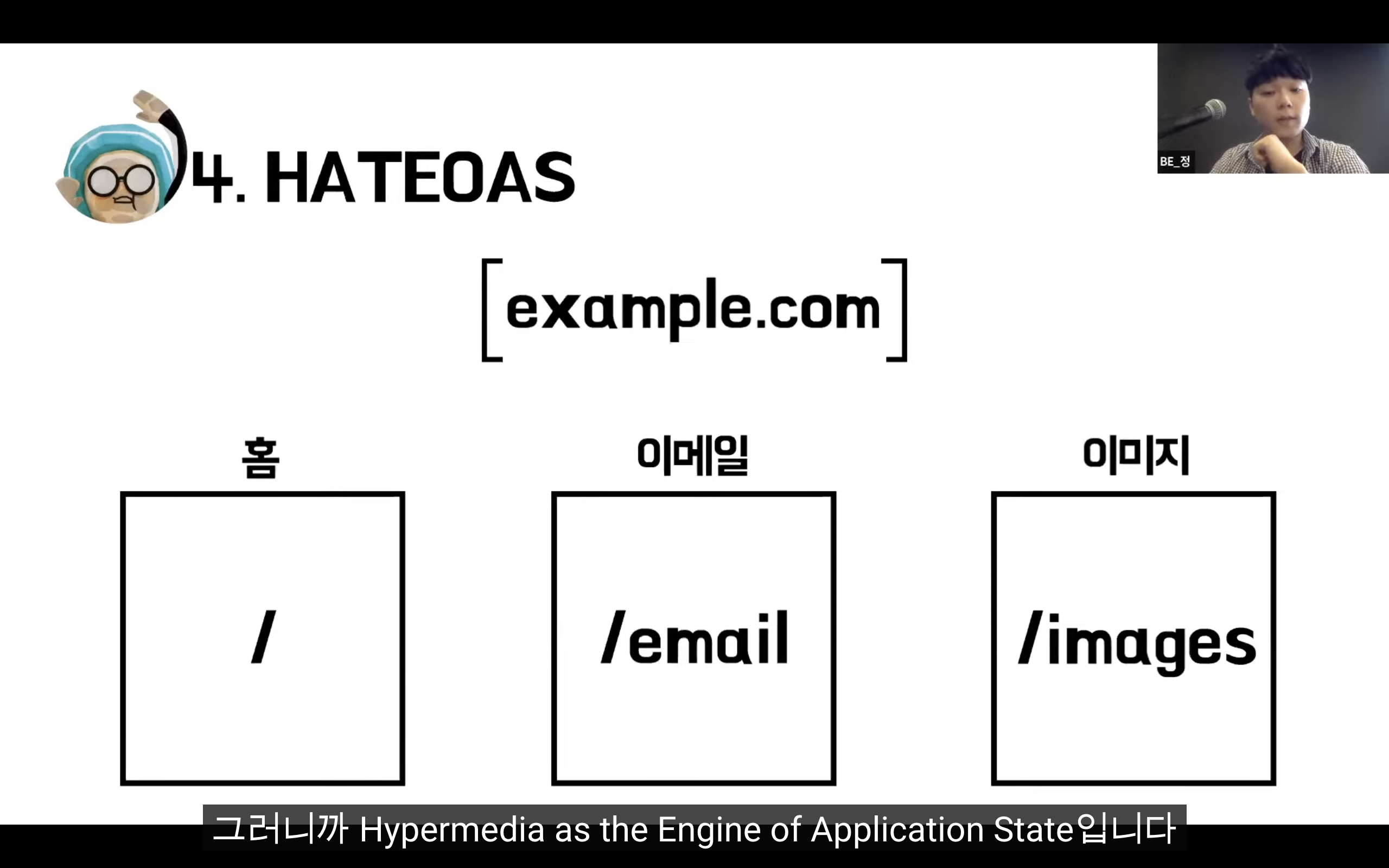
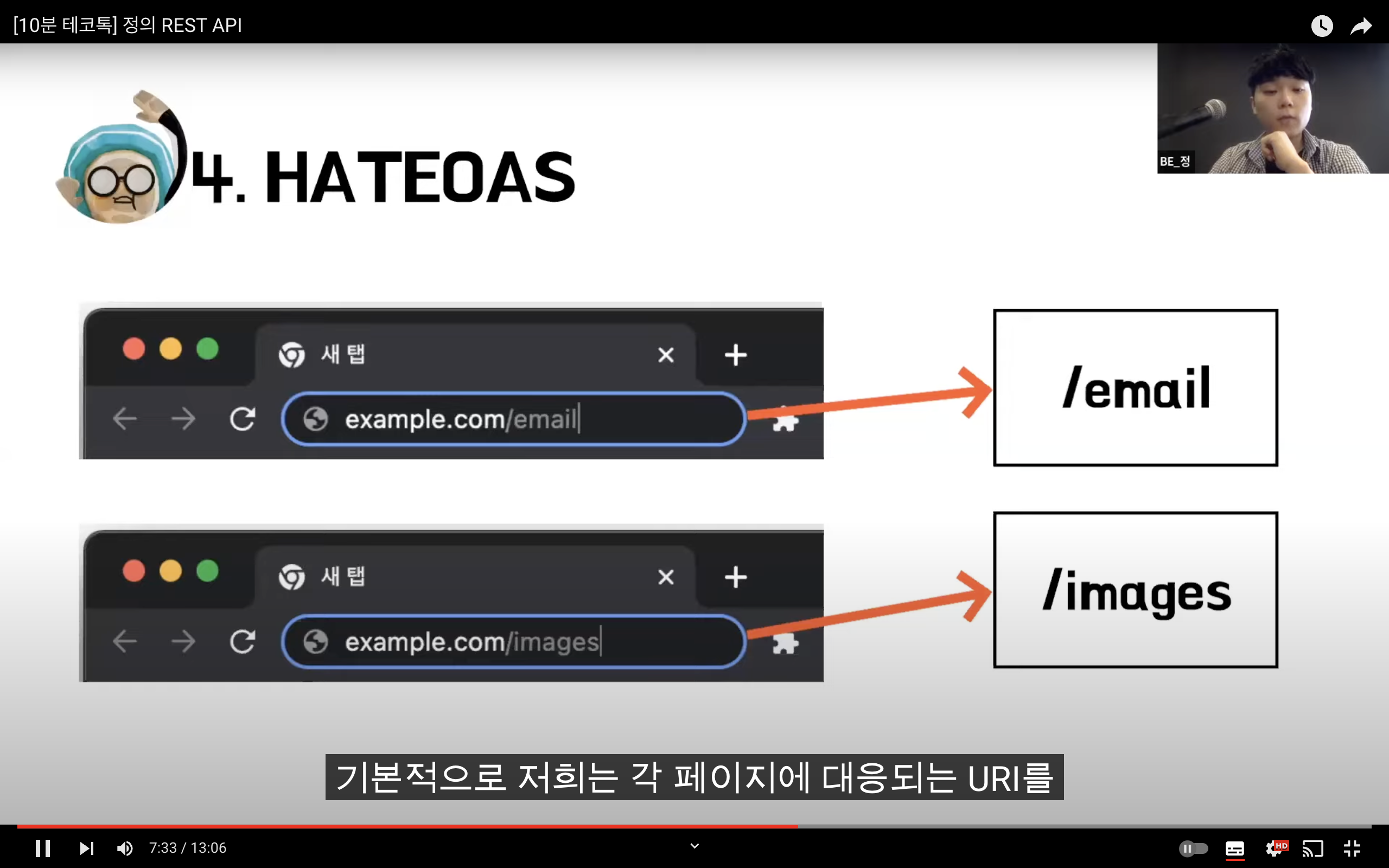

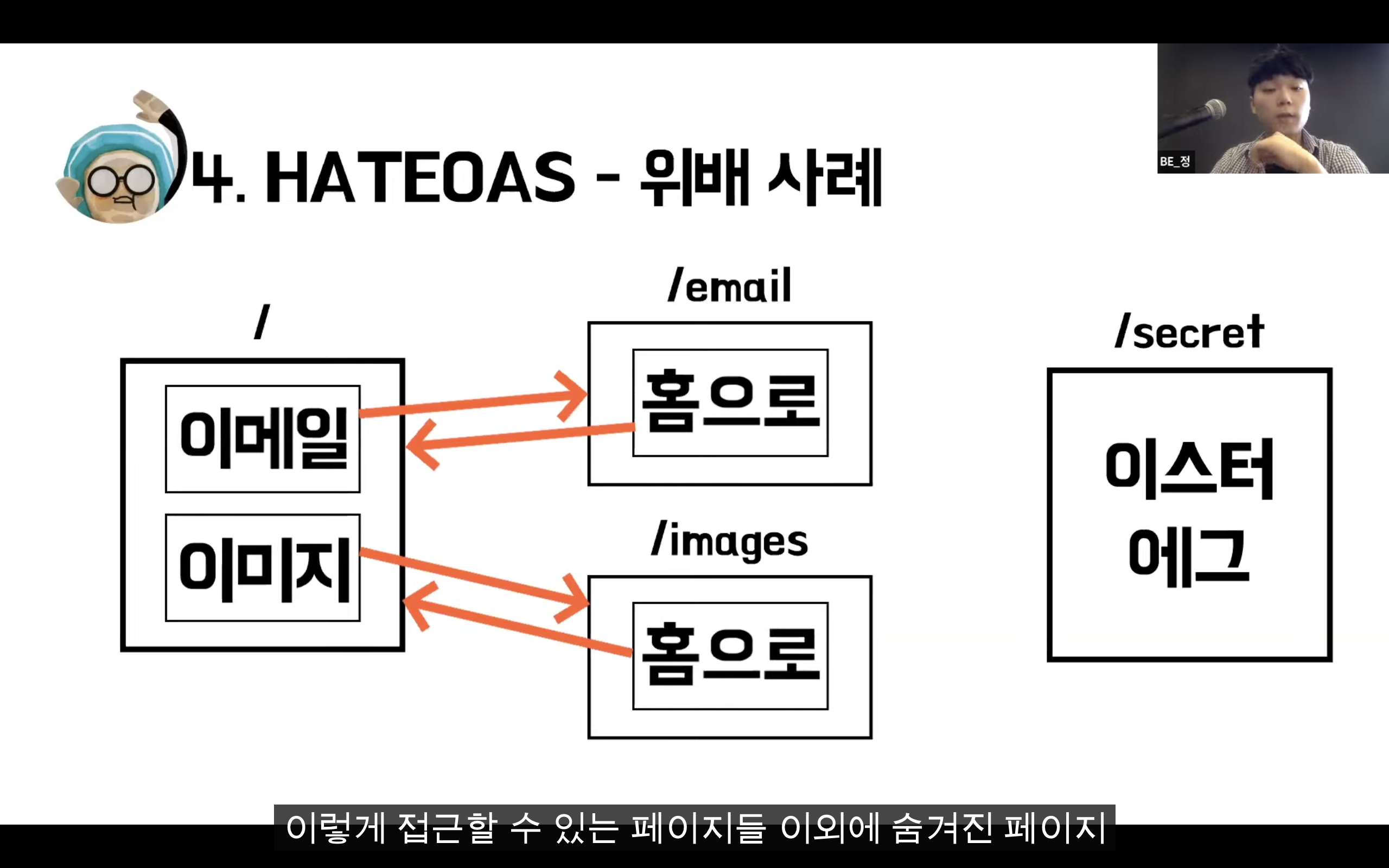
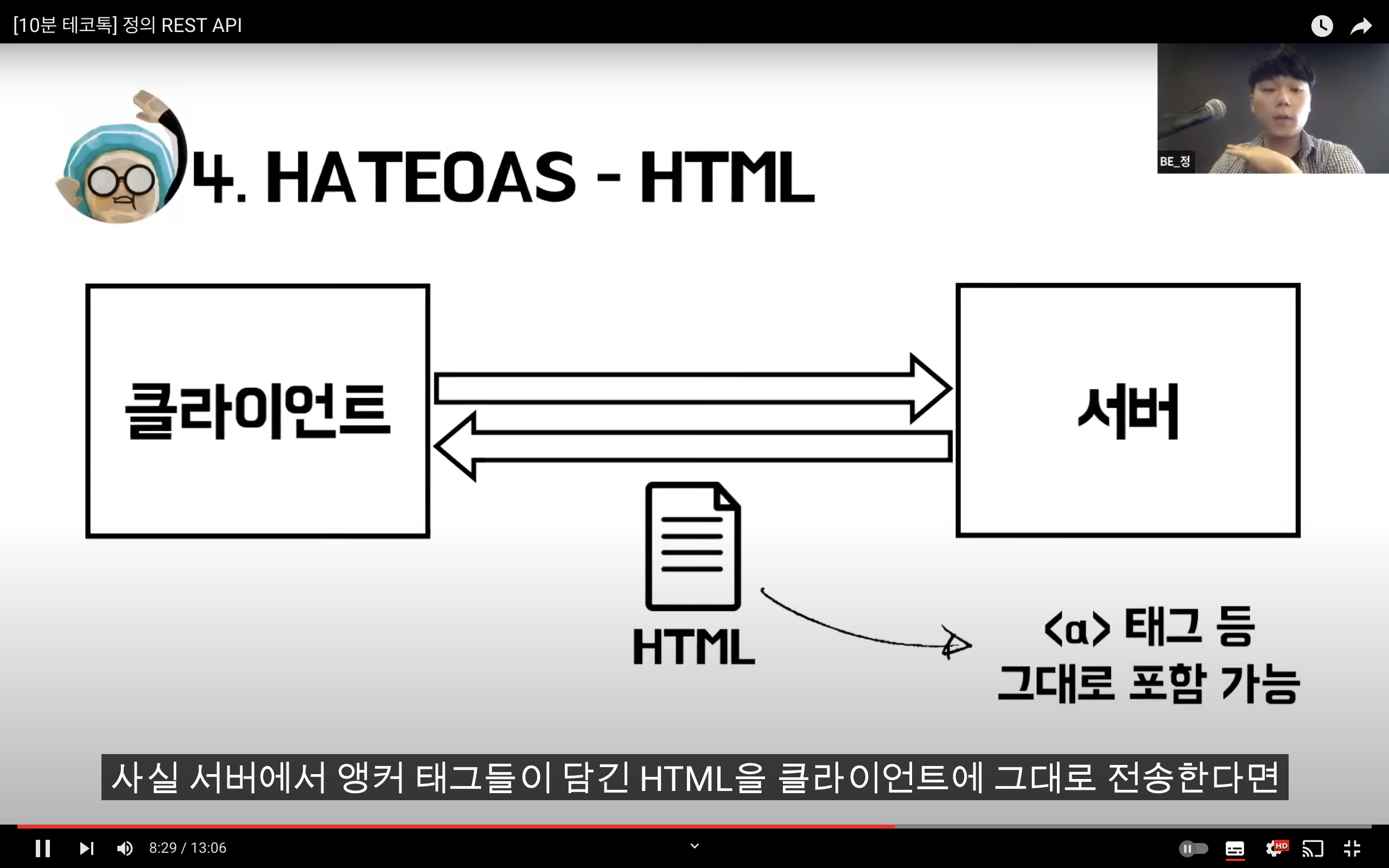
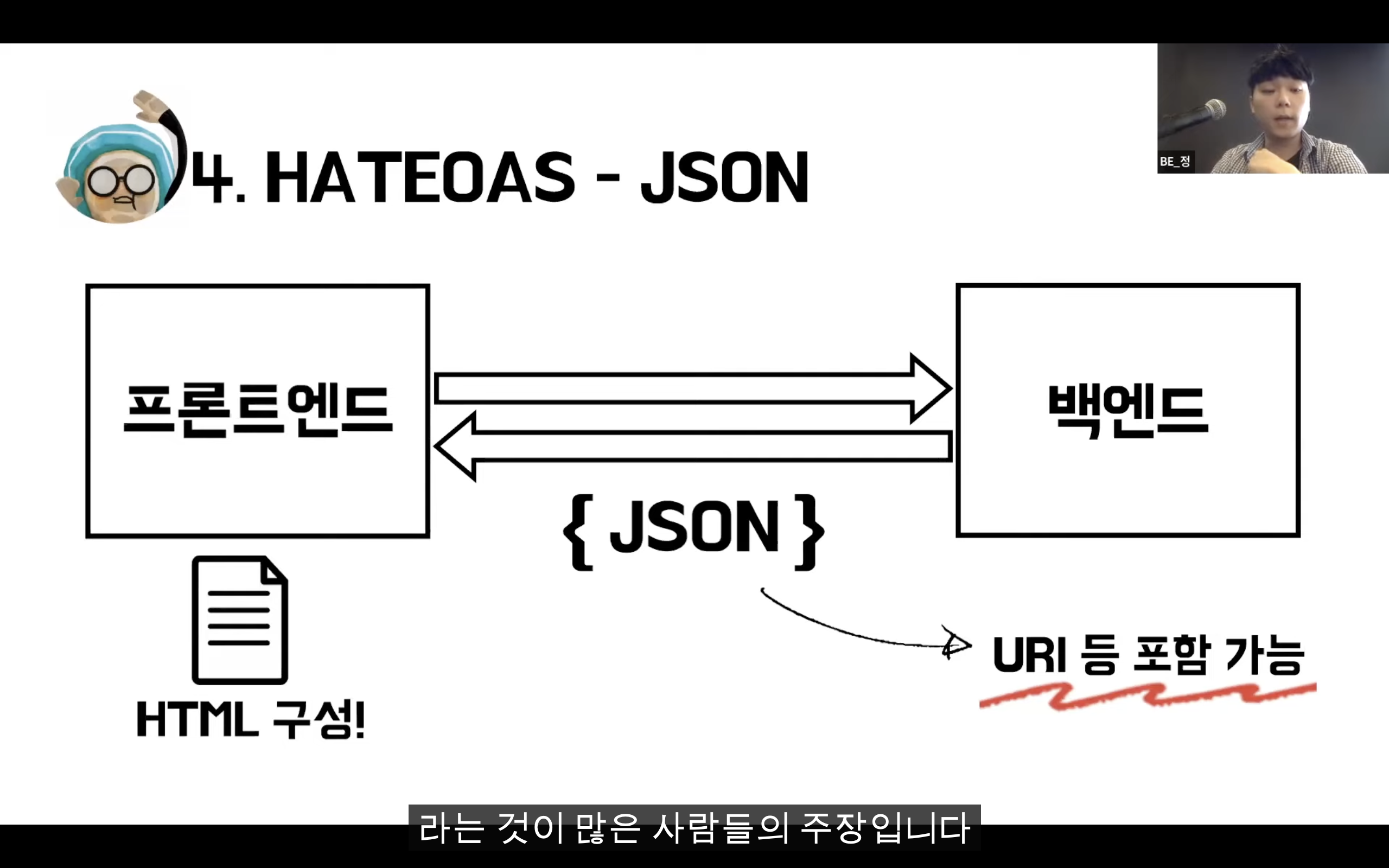
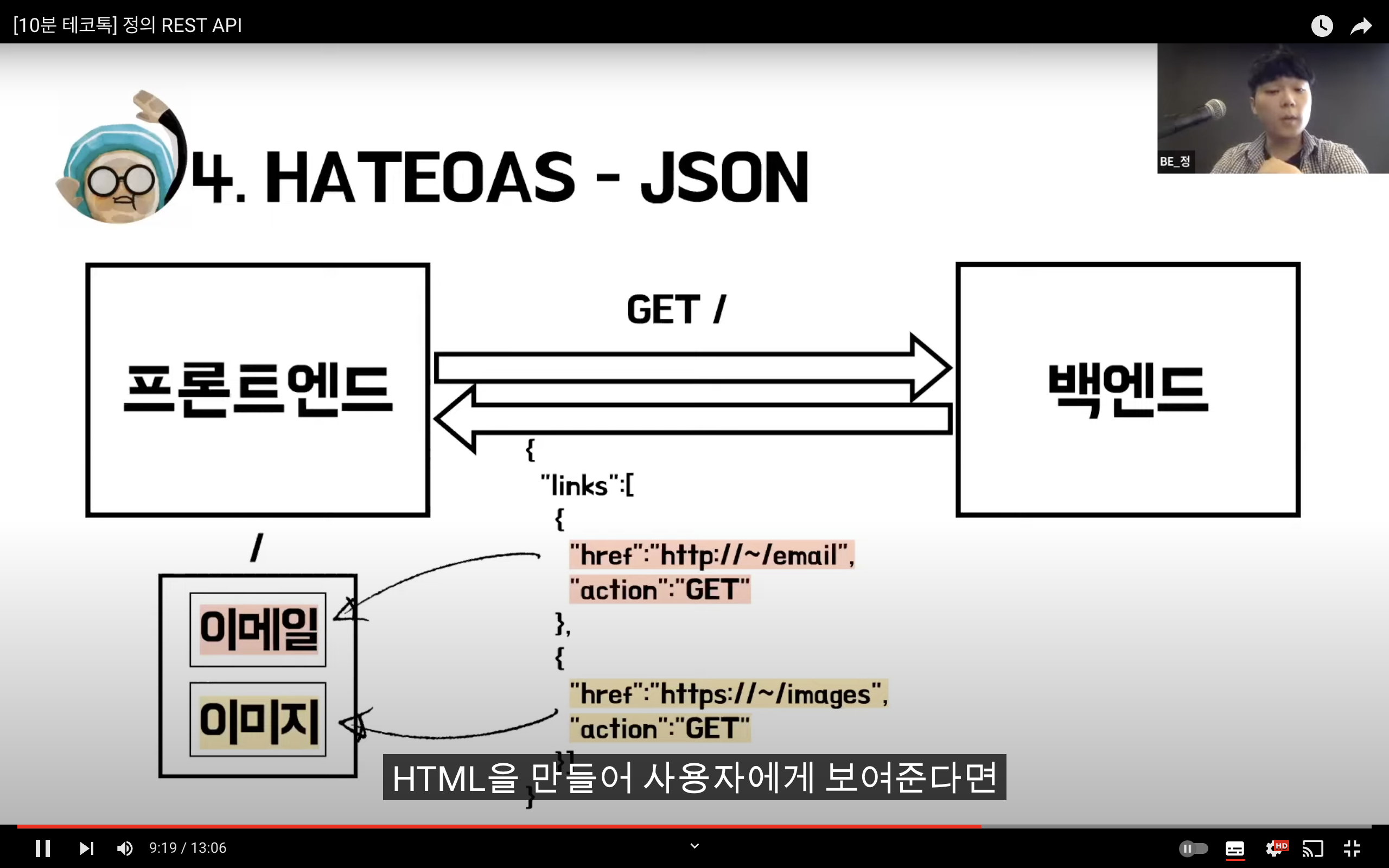





REST
Representational State Transfer
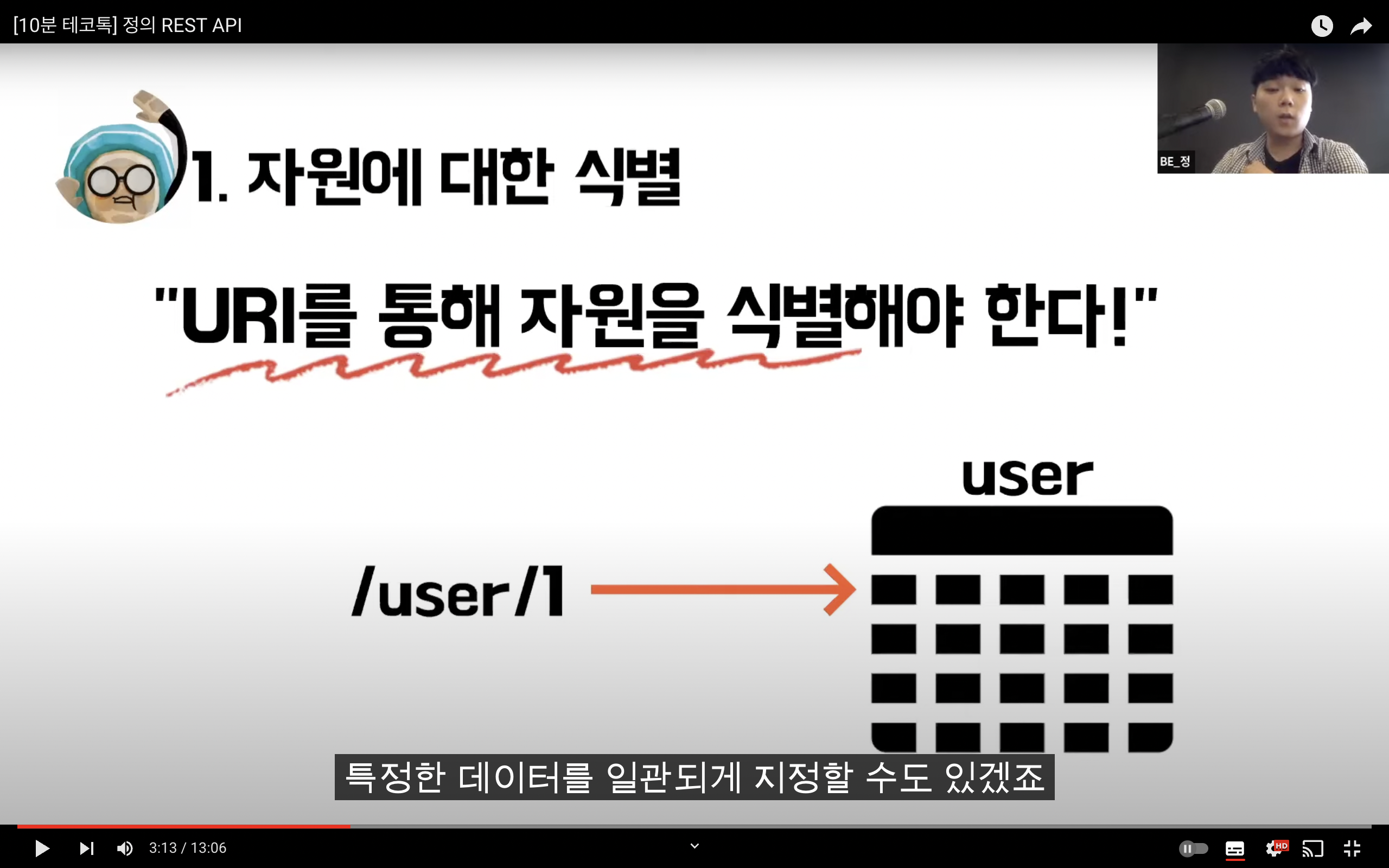
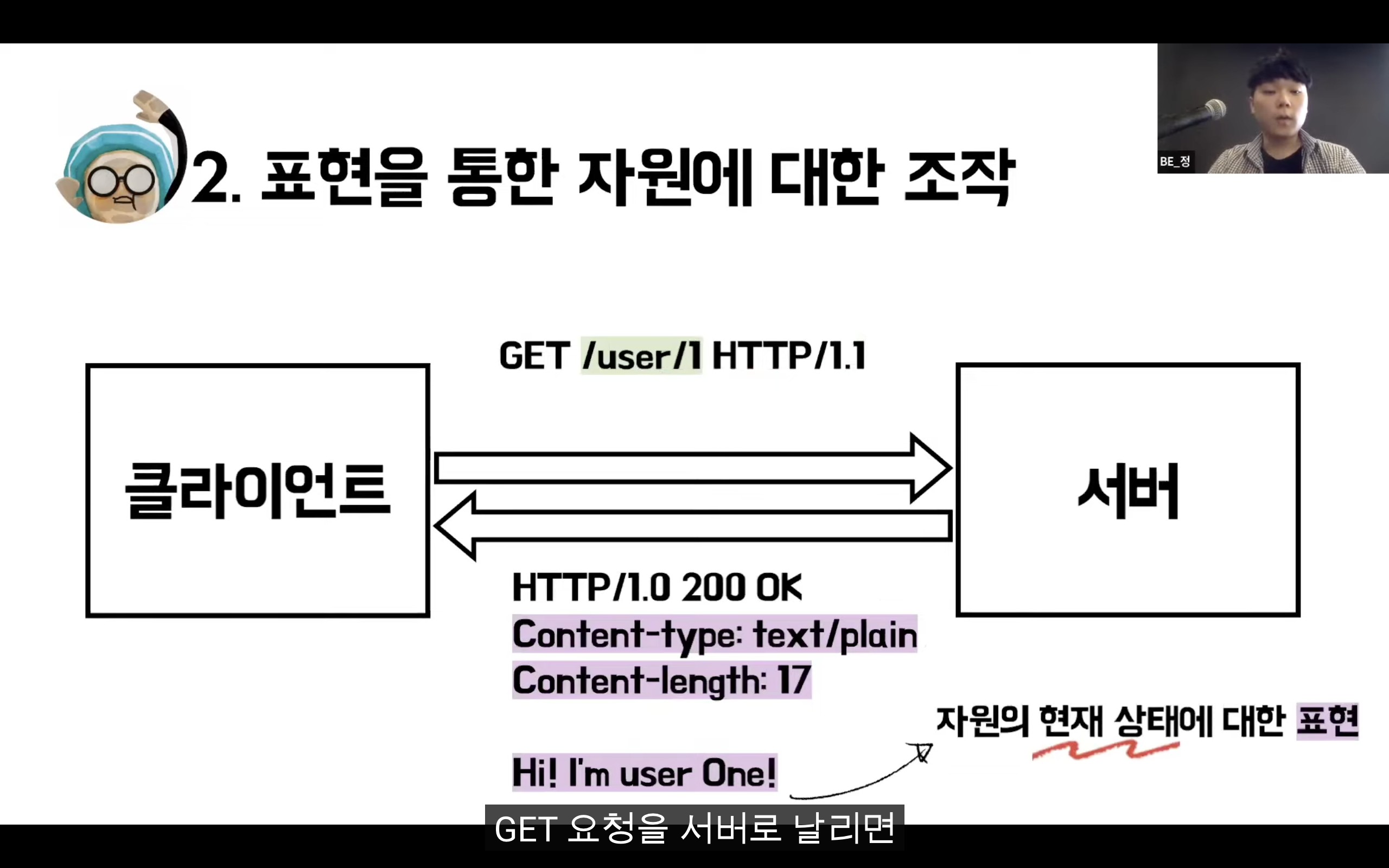
자원을 이름(자원의 표현)으로 구분하여 해당 자원의 상태(정보)를 주고 받는 모든 것을 의미한다.
자원 기반의 구조(ROA, Resource Oriented Architecture) 설계의 중심.
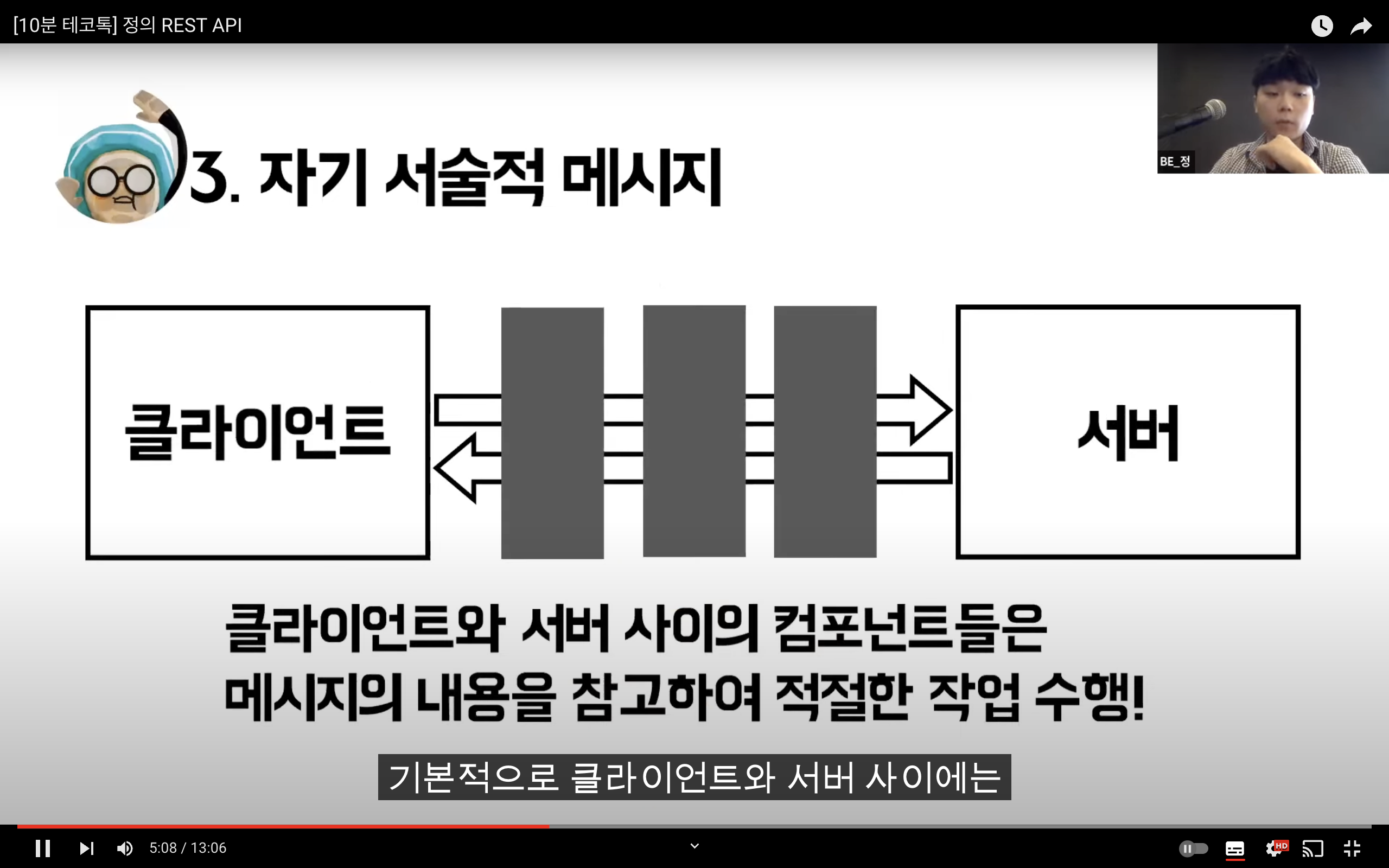
HTTP Method를 통해 Resource를 처리하도록 설계된 아키텍쳐
웹 사이트의 이미지, 텍스트, DB 내용 등의 모든 자원에 -----> 고유한 ID인 HTTP URI를 부여한다.
CRUD Operation
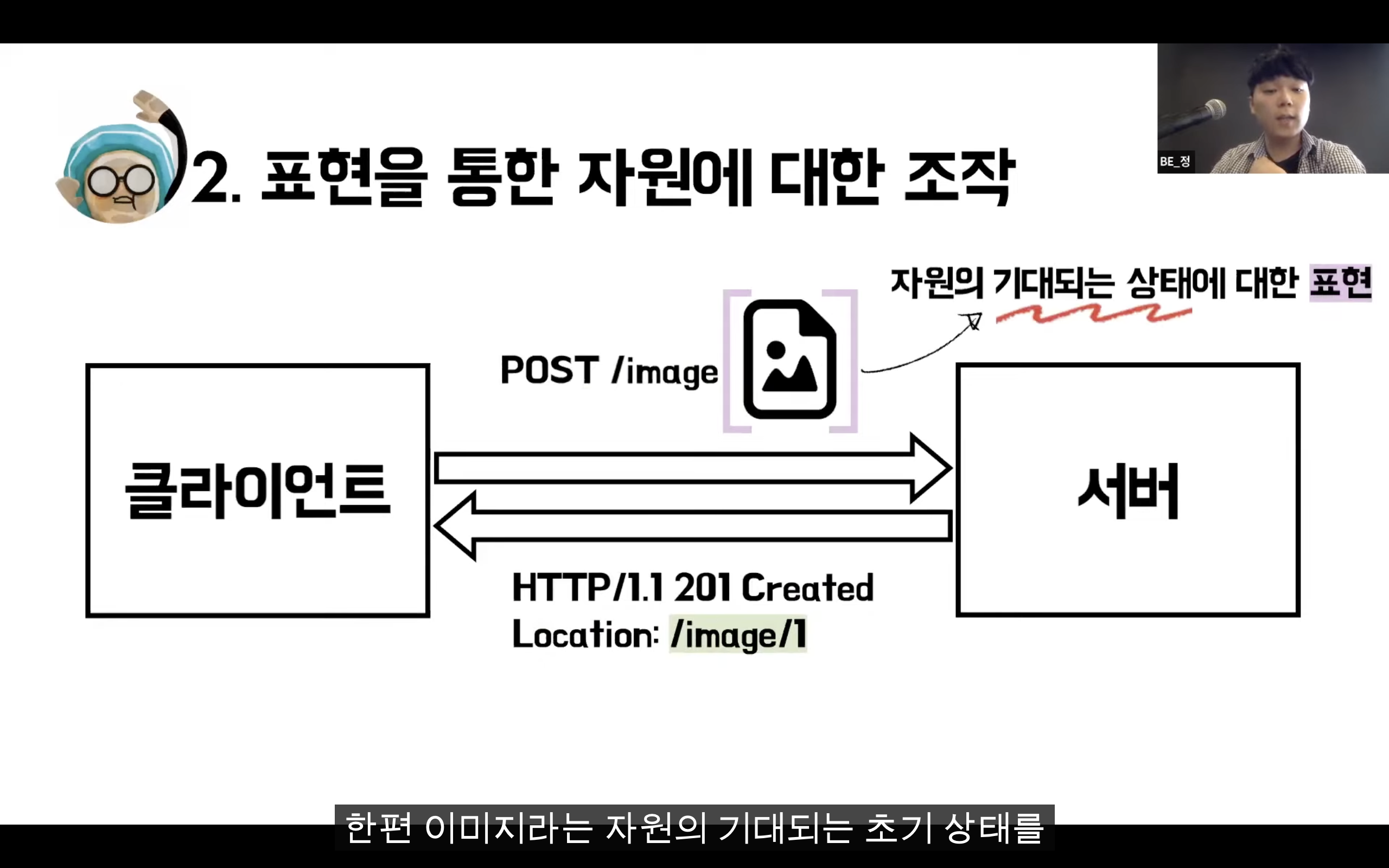
Create : 생성(POST)
Read : 조회(GET)
Update : 수정(PUT)
Delete : 삭제(DELETE)
HEAD: header 정보 조회(HEAD)
(rest 에서는 crud 없다고함)
API
Application Programming Interface
데이터와 기능의 집합을 제공하여 컴퓨터 프로그램간 상호작용을 촉진하며, 서로 정보를 교환가능 하도록 하는 것
REST API
도큐먼트 : 객체 인스턴스나 데이터베이스 레코드와 유사한 개념
컬렉션 : 서버에서 관리하는 디렉터리라는 리소스
스토어 : 클라이언트에서 관리하는 리소스 저장소
URI는 정보의 자원을 표현해야 한다.
1) resource는 동사보다는 명사를, 대문자보다는 소문자를 사용한다.
2) resource의 도큐먼트 이름으로는 단수 명사를 사용해야 한다.
3) resource의 컬렉션 이름으로는 복수 명사를 사용해야 한다.
4) resource의 스토어 이름으로는 복수 명사를 사용해야 한다.
Ex) GET /Member/1 -> GET /members/1
자원에 대한 행위는 HTTP Method(GET, PUT, POST, DELETE 등)로 표현한다.
1) URI에 HTTP Method가 들어가면 안된다.
Ex) GET /members/delete/1 -> DELETE /members/1
2) URI에 행위에 대한 동사 표현이 들어가면 안된다.(즉, CRUD 기능을 나타내는 것은 URI에 사용하지 않는다.)
Ex) GET /members/show/1 -> GET /members/1
Ex) GET /members/insert/2 -> POST /members/2
3) 경로 부분 중 변하는 부분은 유일한 값으로 대체한다.(즉, :id는 하나의 특정 resource를 나타내는 고유값이다.)
Ex) student를 생성하는 route: POST /students
Ex) id=12인 student를 삭제하는 route: DELETE /students/12
응답상태코드
1xx : 전송 프로토콜 수준의 정보 교환
2xx : 클라어인트 요청이 성공적으로 수행됨
3xx : 클라이언트는 요청을 완료하기 위해 추가적인 행동을 취해야 함
4xx : 클라이언트의 잘못된 요청
5xx : 서버쪽 오류로 인한 상태코드
1. URI는 동사보다는 명사를, 대문자보다는 소문자를 사용하여야 한다.
Bad Example http://khj93.com/Running/
Good Example http://khj93.com/run/
2. 마지막에 슬래시 (/)를 포함하지 않는다.
Bad Example http://khj93.com/test/
Good Example http://khj93.com/test
3. 언더바 대신 하이폰을 사용한다.
Bad Example http://khj93.com/test_blog
Good Example http://khj93.com/test-blog
4. 파일확장자는 URI에 포함하지 않는다.
Bad Example http://khj93.com/photo.jpg
Good Example http://khj93.com/photo
5. 행위를 포함하지 않는다.
Bad Example http://khj93.com/delete-post/1
Good Example http://khj93.com/post/1
RESTful API란 무엇인가요?
RESTful API는 두 컴퓨터 시스템이 인터넷을 통해 정보를 안전하게 교환하기 위해 사용하는 인터페이스입니다.
RESTful이란
RESTful은 일반적으로 REST라는 아키텍처를 구현하는 웹 서비스를 나타내기 위해 사용되는 용어이다.
‘REST API’를 제공하는 웹 서비스를 ‘RESTful’하다고 할 수 있다.
RESTful은 REST를 REST답게 쓰기 위한 방법으로, 누군가가 공식적으로 발표한 것이 아니다.
즉, REST 원리를 따르는 시스템은 RESTful이란 용어로 지칭된다.
RESTful의 목적
이해하기 쉽고 사용하기 쉬운 REST API를 만드는 것
RESTful한 API를 구현하는 근본적인 목적이 성능 향상에 있는 것이 아니라 일관적인 컨벤션을 통한 API의 이해도 및 호환성을 높이는 것이 주 동기이니, 성능이 중요한 상황에서는 굳이 RESTful한 API를 구현할 필요는 없다.
RESTful 하지 못한 경우
Ex1) CRUD 기능을 모두 POST로만 처리하는 API
Ex2) route에 resource, id 외의 정보가 들어가는 경우(/students/updateName)
2) 인덱스의 내부구조 클러스터형 DB vs Non클러스트형 DB
데이터베이스에서 클러스터
여러개의 서버가 하나의 데이터베이스를 나눠서 처리하는 형태
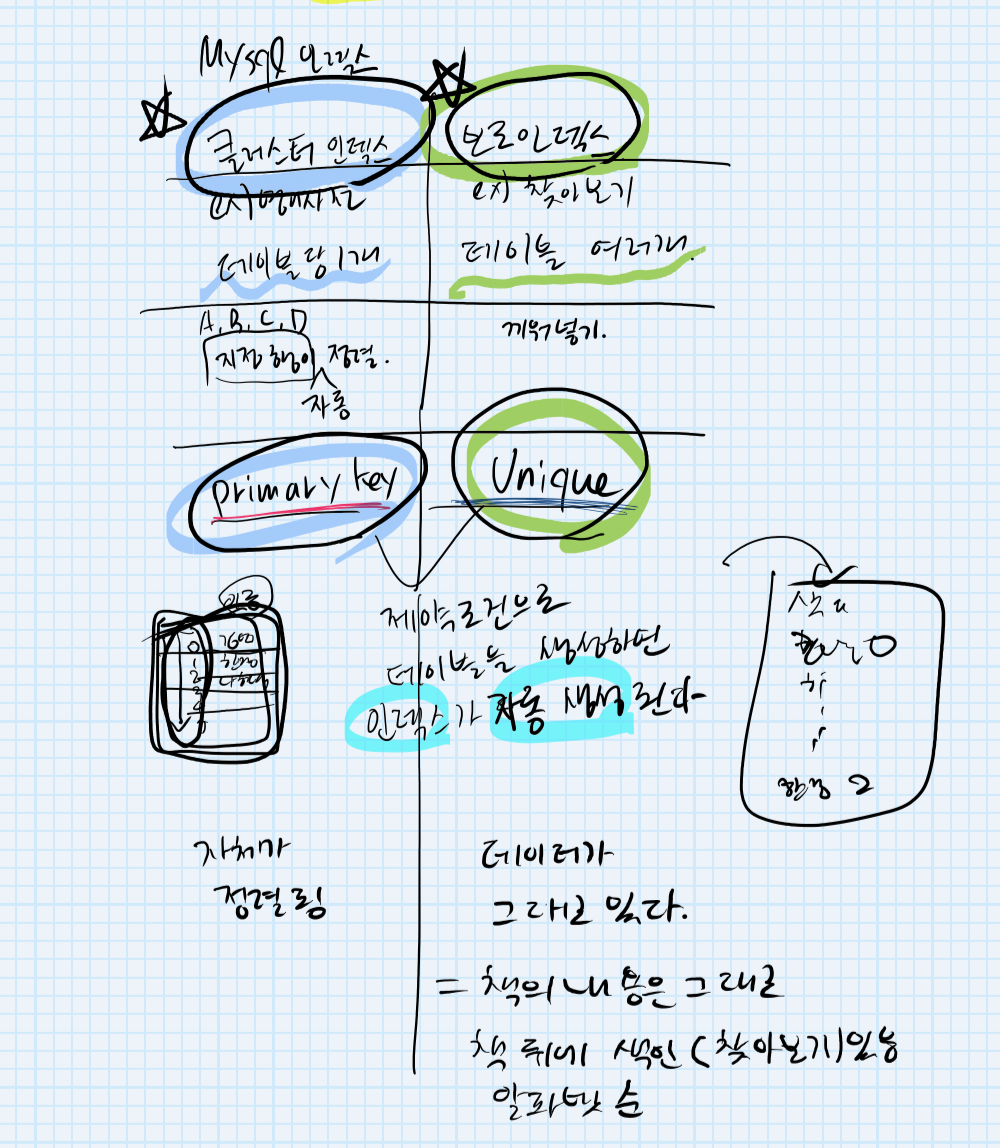
인덱스 클러스터
1. 테이블당 한 개만 생성 가능
ex) 영어사전 : 영어 순서대로 정렬(a-z)
2. 데이터를 인덱스로 지정한 컬럼에 맞춰서 데이터를 삽입, 삭제 시 자동 정렬한다.
ex) 영어사전에 단어를 추가할 때 이미 알파벳 순으로 단어(데이터)가 정렬 되어있음
3. 테이블 값이 정렬된 상태로 저장되어 있다.
비 인덱스 클러스터
1. 테이블당 여러 개 생성 가능.
ex) 보조 인덱스?
2. 찾아보기(색인)이 있는 책과 같다

인덱스
: 책 앞에 위치하는 목차, 또는 책 뒤쪽에 위치하는 색인, 찾아보기 또는 영어사전에 옆에 알파벳 순으로 파여져 있는 것.
: 조회 하려는 데이터가 어디에 위치하는지 빨리 찾을 수 있도록 하는 역할
인덱스 특징
1. 검색 속도 빠름
찾아보기가 없다면 영어사전에서 friend 단어를 처음부터 끝까지 읽느냐고 단어를 찾는데 오랜 시간이 걸린다.
2. 인덱스를 위한 추가 공간이 필요
목차, 찾아보기, 홈파여 있는 것 들 모두 다른 페이지에 적는 것처럼. 인덱스도 공간이 필요하다
3. 인덱스 생성 시간이 소요됨
4. insert, update, delete가 자주 발생한다면 성능이 많이 하락할 수 있다.
인덱스가 없다면 => Heap 구조
heap은 더미라는 뜻 == 순서 없이 데이터 쌓음 == 클러스트형 인덱스 없음
순서 없이 데이터를 마구 막 쌓음.

클러스터형 인덱스
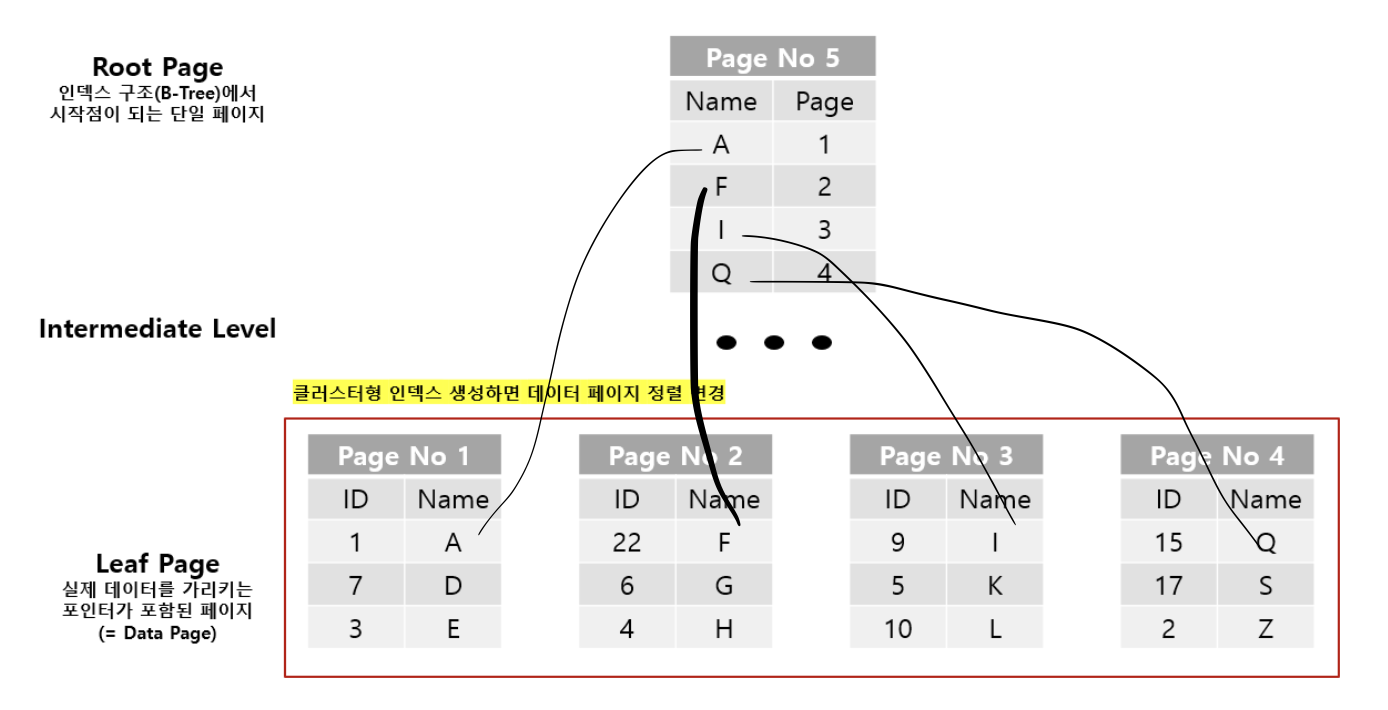
아무 기준 없이 데이터가 쌓이는 Heap과 달리, 테이블에 클러스터형 인덱스를 생성하게 되면 데이터의 정렬이 발생한다.
B-Tree 구조를 따르는 SQL Server의 인덱스 구조는
Root(최상위), Intermediate(중간), Leaf(최하위)의 총 3단계의 노드로 구성되며 각 노드에 페이지가 생성됩니다.
이 때, 클러스터형 인덱스는 Leaf Page에 실제 데이터가 정렬된 상태로 위치한다.
각 노드의 페이지에는 클러스터형 인덱스 키가 생성되어 다음 수준의 노드를 가리키는 일종의 포인터 역할을 합니다.
데이터가 조회될 때 이 포인터를 따라가서 빠르게 수행될 수 있게 되는 것이죠.
--클러스터형 인덱스 생성 쿼리
create clustered index cl_index
on mydb.dbo.tablename (index_col1, index_col2)
테이블을 생성할 때 PRIMARY KEY 조건을 사용하면
고유(Unique) 인덱스가 자동으로 생성되는데
기본적으로는 클러스터형 인덱스가 생성되며
비클러스터형 인덱스가 생성되도록 별도로 지정하는 것도 가능합니다.
프라이머리 키랑 유니크는 다른거 아닌가?
- Between, <, <= 등을 사용하는 범위 값을 반환하는 쿼리에 클러스터형 인덱스 사용하는 것이 좋습니다.
- JOIN 조건에 사용되는 경우 클러스터형 인덱스 키로 설정하는 것이 좋습니다.
- ORDER BY 혹은 GROUP BY에 사용하는 경우 클러스터형 인덱스 키로 사용하는 것이 좋습니다.
* ORDER BY / GROUP BY는 정렬 동작을 수행하는데
인덱스로 인해 이미 정렬되어 있는 경우에는 많은 리소스를 소모하는 정렬 동작이 발생하지 않습니다.
- 자주 변경되는 칼럼은 클러스터형 인덱스 키로 사용하지 않는 것이 좋습니다.
- 다수의 Key 칼럼을 사용하는 것은 좋지 않으므로 최대한 적은 수의 칼럼을 클러스터형 인덱스 키 칼럼으로 지정해서 사용합니다.
* 클러스터형 인덱스의 Key 칼럼은 다른 비클러스터형 인덱스의 lookup Key로 사용하기 때문에 클러스터형 인덱스에 많은 Key를 포함시키면 클러스터형 인덱스의 Key 칼럼을 포함하고 있는 비클러스터형의 인덱스 엔트리의 크기가 과도하게 증가할 수 있습니다.
출처: https://datalibrary.tistory.com/129
비 클러스터형 인덱스
|
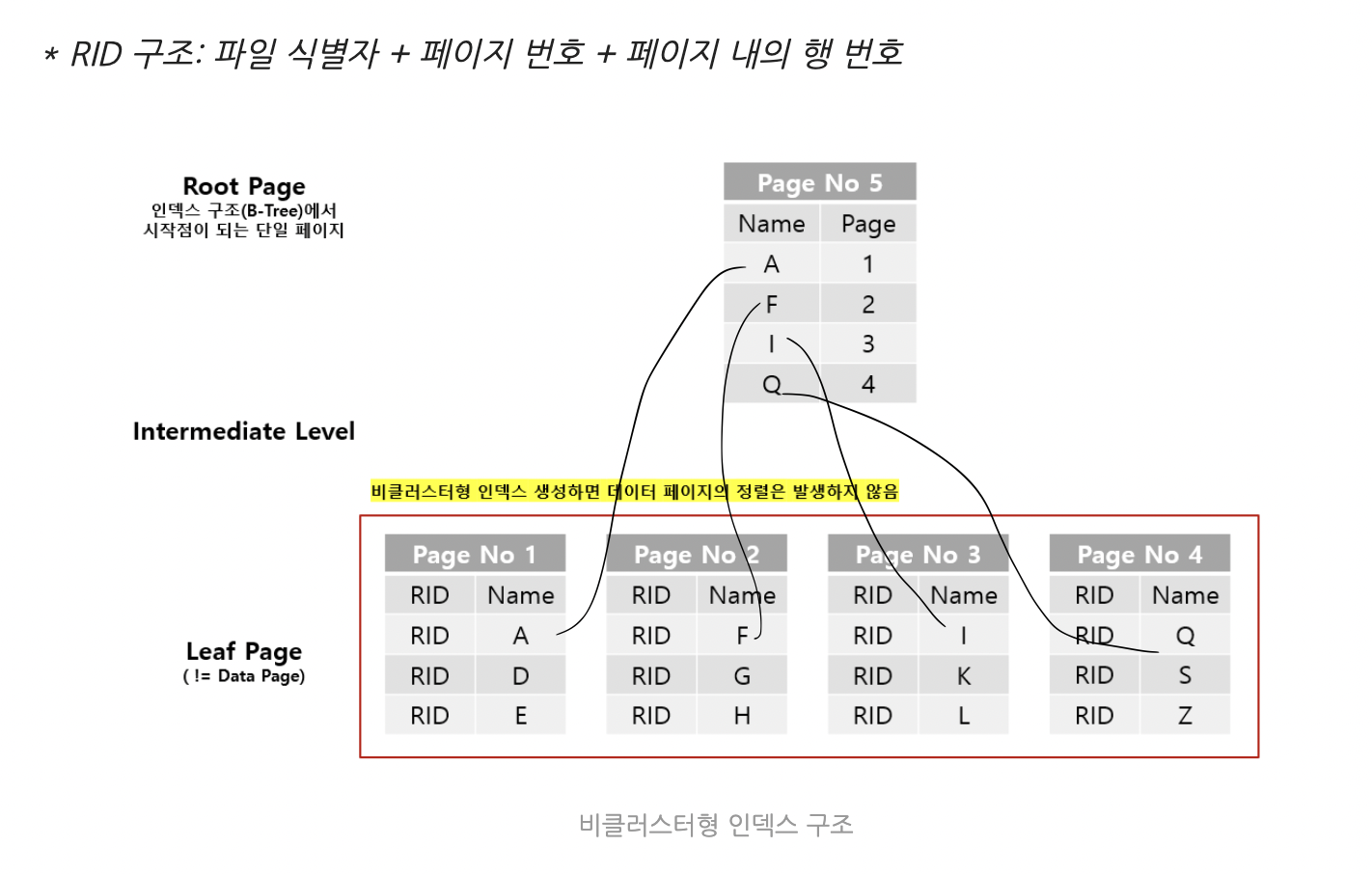 |
리프 페이지는 데이터 페이지가 아니다.
인덱스를 생성하더라도 실제 데이터의 정렬은 발생하지 않음.
각각의 행에 RID라고 하는 것이 존재하는 것을 볼 수 있는데,
Heap 구조의 경우에는 locator라는 '행 포인터'가 RID를 통해 데이터를 찾음
클러스터형 인덱스의 구조인 경우에는 클러스터형 인덱스 키를 통해 데이터를 찾게 됩니다.
--비클러스터형 인덱스 생성 쿼리
create index ncl_index
on mydb.dbo.tablename (index_col1, index_col2)- 업데이트가 자주 발생하지 않는 대용량 테이블에 인덱스를 생성하는 것이 좋습니다.
* 인덱스가 다수 존재하면 옵티마이저가 선택할 수 있는 인덱스가 많아짐.
데이터의 변경이 자주 일어나는 경우에는 데이터가 변경될 때
모든 인덱스에도 함께 변경사항이 적용되어야 하기 때문에
인덱스가 과도하게 많으면 오히려 데이터베이스의 성능이 저하될 수 있습니다.
- 필터링 된 인덱스를 사용하면 전체 테이블에 대한 인덱스를 사용하는 것보다 효율적인 성능을 기대할 수 있습니다.
- 조회하려고 하는 모든 칼럼이 인덱스에 포함되어 있는 경우에는 데이터 페이지까지 내려가지 않고 모든 데이터를 조회할 수 있기 때문에 성능 향상이 가능하므로 Included column을 사용하는 것도 고려해보는 것이 좋습니다.
* 클러스터형 인덱스에는 Included column을 설정할 수 없습니다.
- 인덱스 키로 사용되는 칼럼의 고유한 값이 수가 매우 적은 경우(동일한 데이터가 많은 경우)에는 인덱스를 사용하지 않고 테이블 스캔이 발생하는 것이 더 효율적일 수 있습니다.
* 데이터 페이지를 처음부터 찾으면 더 빠를텐데, 괜히 인덱스 페이지부터 시작해서 더 오래걸리는 경우 발생할 수도 있습니다.
3) 가비지콜렉터
자바에서는 jvm이 자동으로 가비지를 정리해줌
가비지 그대로 두면?
1. 필요없는(사용하지 않는) 메모리를 해제해주지 않으면 memory leak이 발생한다.
2. 사용 중이던 메모리를 해제해버리면 프로그램이 중단되고, 데이터가 손실될 수 있다.
프로그램을 개발 하다 보면 유효하지 않은 메모리인 가바지(Garbage)가 발생하게 된다.
C언어를 이용하면 free()라는 함수를 통해 직접 메모리를 해제해주어야 한다.
하지만 Java나 Kotlin을 이용해 개발을 하다 보면 개발자가 메모리를 직접 해제해주는 일이 없다.
그 이유는 JVM의 가비지 컬렉터가 불필요한 메모리를 알아서 정리해주기 때문이다.
대신 Java에서 명시적으로 불필요한 데이터를 표현하기 위해서 일반적으로 null을 선언해준다.
예를 들어 아래와 같은 코드가 있다고 가정하자.
Person person = new Person();
person.setName("Mang");
person = null;
// 가비지 발생
person = new Person();
person.setName("MangKyu");
기존의 Mang으로 생성된 person 객체는 더이상 참조를 하지 않고 사용이 되지 않아서 Garbage(가비지)가 되었다.
Java나 Kotlin에서는 이러한 메모리 누수를 방지하기 위해 가비지 컬렉터(Garbage Collector, GC)가
주기적으로 검사하여 메모리를 청소해준다.(물론 Java에서도 System.gc()를 이용해 호출할 수 있지만, 해당 메소드를 호출하는 것은 시스템의 성능에 매우 큰 영향을 미치므로 절대 호출해서는 안된다.)
[ Minor GC와 Major GC ]
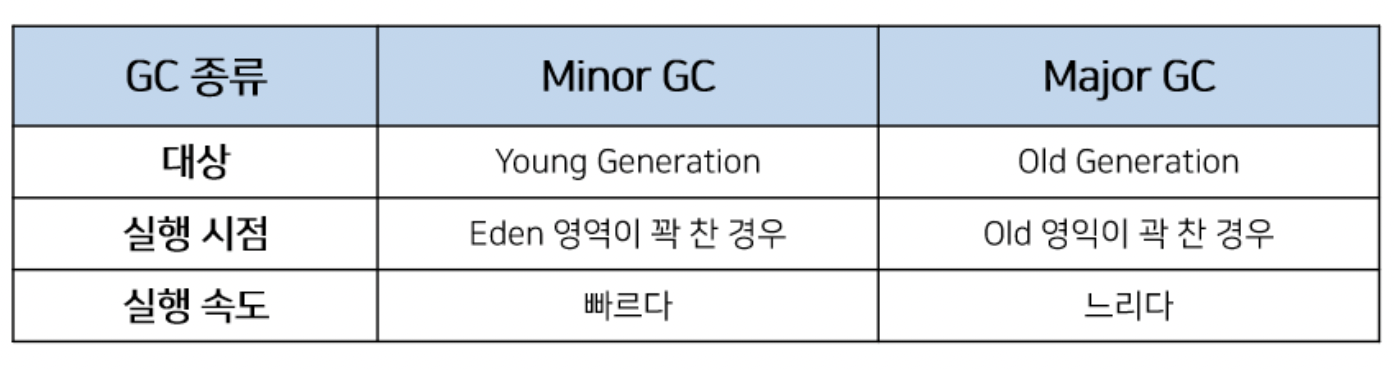
JVM의 Heap영역은 처음 설계될 때 다음의 2가지를 전제(Weak Generational Hypothesis)로 설계되었다.
- 대부분의 객체는 금방 접근 불가능한 상태(Unreachable)가 된다.
- 오래된 객체에서 새로운 객체로의 참조는 아주 적게 존재한다.
즉, 객체는 대부분 일회성되며, 메모리에 오랫동안 남아있는 경우는 드물다는 것이다. 그렇기 때문에 객체의 생존 기간에 따라 물리적인 Heap 영역을 나누게 되었고 Young, Old 총 2가지 영역으로 설계되었다. 초기에는 Perm 영역이 존재하였지만 Java8부터 제거되었다.
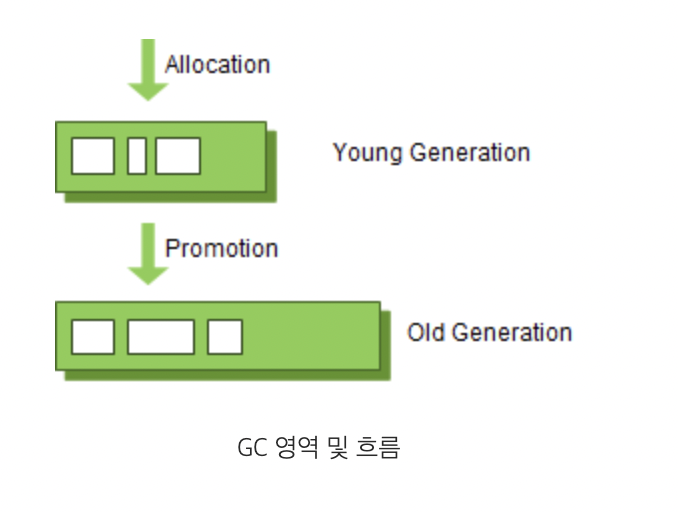
- Young 영역(Young Generation)
- 새롭게 생성된 객체가 할당(Allocation)되는 영역
- 대부분의 객체가 금방 Unreachable 상태가 되기 때문에, 많은 객체가 Young 영역에 생성되었다가 사라진다.
- Young 영역에 대한 가비지 컬렉션(Garbage Collection)을 Minor GC라고 부른다.
- Old 영역(Old Generation)
- Young영역에서 Reachable 상태를 유지하여 살아남은 객체가 복사되는 영역
- Young 영역보다 크게 할당되며, 영역의 크기가 큰 만큼 가비지는 적게 발생한다.
- Old 영역에 대한 가비지 컬렉션(Garbage Collection)을 Major GC 또는 Full GC라고 부른다.
출처: https://mangkyu.tistory.com/118 [MangKyu's Diary:티스토리]
파이썬에서 가비지
Python의 GC 동작 방식
Python의 Garbage Collecting은 다음 2 가지 방식으로 동작한다.
- Reference counting
- Generational garbage collection
1. Reference counting(레퍼런스 카운팅) -> 자동 수행
레퍼런스 카운팅 방식의 가비지 컬렉팅은, 어떤 객체가 참조되고있는 횟수를 카운팅하고 0이 될 경우 메모리에서 해제하는 방식이다.
python standard library의 sys모듈로 특정 객체의 reference counts를 확인할 수 있다.
>>> import sys
>>> a = 'hello'
>>> sys.getrefcount(a)
2위 코드에서, 'hello'는 힙에 할당되고 a는 지역변수라는 가정 하에 스택에 할당되어 'hello'가 위치한 힙의 주소를 갖고 있다.
이 상황에서 a의 레퍼런스 카운트는 2이다.
첫번째는 a가 위치한 스택의 주소가 콜스택에서 참조되고 있기 때문이며, 두번째는 getrefcount()에 전달될 때이다.
만약 콜스택에서 a가 위치한 레벨의 함수가 실행 완료되면, 콜스택에서 참조하고 있는 a가 사라지기에 reference count는 0이되고 gc에 의해 메모리에서 해제된다.
2. Generational garbage collection(제너레이셔널 가비지 콜렉션)
>>> l = []
>>> l.append(l)
>>> del l위 코드의 l과 같이, 만약 어떤 동적 객체가 서로를 참조(순환참조)하고 있다면 Reference counting 방식에서는 해당 객체들은 메모리에서 해제될 수 없다.
이러한 경우를 방지하기 위해, 파이썬에서는 Generational garbage collection이 순환 참조를 탐지하고 메모리에서 해제해준다.
출처: https://velog.io/@zihs0822/Python%EC%9D%98-GC%EC%99%80-GIL




{kind=link}