| 3.3.7 인덱스 스킵 스캔 활용 3.3.8 in 조건은 = 인가 3.3.9 BETWEEN 과 LIKE 스캔 범위 비교 3.3.10 범위 검색 조건을 남용할 때 생기는 비효율 3.3.11 다양한 옵션 조건 처리 방식의 장단점 비교 3.3.12 함수호출부하 해소를 위한 인덱스 구성 3.4 인덱스 설계 3.4.1 인덱스 설계가 어려운 이유 3.4.2 가장 중요한 두 가지 선택 기준 3.4.3 스캔 효율성 이외의 판단 기준 3.4.4 공식을 초월한 전략적 설계 3.4.5 소트 연산을 생략하기 위한 컬럼 추가 3.4.6 결합 인덱스 선택도 3.4.7 중복 인덱스 제거 3.4.8 인덱스 설계도 작성 |
3.3.7 인덱스 스킵 스캔 활용
3.3.8 in 조건은 = 인가
3.3.9 BETWEEN 과 LIKE 스캔 범위 비교
3.3.10 범위 검색 조건을 남용할 때 생기는 비효율
3.3.11 다양한 옵션 조건 처리 방식의 장단점 비교
3.3.12 함수호출부하 해소를 위한 인덱스 구성
3.4 인덱스 설계
온라인 트랜잭션을 처리하는 시스템에서 인덱스의 설계는 중요하다
1) 인덱스 원리
2) 인덱스 이론
3) 시행착오
3.4.1 인덱스 설계가 어려운 이유
최적화된 인덱스를 마음껏 생성할 수 있다면 설계는 개 쉬워진다.
인덱스가 많이 생성하면
1) 테이블마다 인덱스가 수십 개씩 달린다
2) 관리 비용 증가
3) 시스템 부하 증가
데이터 사이즈가 커지는 만큼
백업, 복제, 재구성 등을 위한 운영 비용이 상승한다.
인덱스가 많으면 문제 발생
1) DML* 성능 저하(TPS* 저하)
2) 데이터베이스 사이즈 증가(디스크 공간 낭비)
3) 데이터베이스 관리, 운영 비용 상승
DML(데이터 조작어) Data Manipulation Language
SELECT, INSERT, UPDATE, DELETE
데이터베이스에 들어 있는 데이터를 조회하거나 검색
데이터에 변형을 가하는 종류의 명령어
TPS(티피에스) Transaction per Second
1초당 처리할 수 있는 트랜잭션의 개수를 의미한다.
100만 TPS는 1초당 100만 건의 트랜잭션을 처리할 수 있는 속도를 말한다. 중앙화를 통해 TPS를 높일 수 있으나, 그 경우 블록체인의 원래 목적인 탈중앙화라는 취지가 훼손된다. 컨센시스(ConsenSys)의 창업자인 조셉 루빈(Joseph Lubin)은 TPS에 탈중앙화 지수(DQ; Decentralization Quotient)를 곱하여, DTPS라는 개념을 만들었다. DTPS란 탈중앙화 TPS 지수인 셈이다
테이블에 여섯개의 인덱스가 있다고 가정하자.
1) 신규 데이터 입력
여섯 개 인덱스에도 데이터를 입력해야 한다.
인덱스는 정렬 상태를 유지하므로
수직적 탐색을 통해 입력할 블록을 찾는다. 찾은 블록에 여유 공간이 없으면 인덱스 분할도 발생한다.
2) 테이블 삭제
여섯 개 인덱스에서 레코드를 일일이 찾아 지운다.
핵심 트랜잭션이 참조하는 테이블에 대한 DML(데이터 명령 조작어) 성능 저하, 트랜잭션 개수 저하
그러니까 인덱스 많으면 별로야
인덱스 개수를 최소화 --> DML 부하를 줄여라.
튜닝은 어렵다 < OLTP* 환경에서 더 어렵다
* OLTP (Online Transaction Processing)
OLTP 란 온라인 트랜잭션 처리를 말하며, 네트워크 상의 온라인 사용자들의 Database 에 대한 일괄 트랜잭션 처리를 의미한다.
3.4.2 가장 중요한 두 가지 선택 기준
결합 인덱스를 구성할 때의 기준
1. 컬럼을 선정하라
1) 조건절을 항상 사용된다
2) 자주 사용하는 컬럼을 선정하라
2. 선정한 컬럼 중에서 = 으로 자주 조회하는 컬럼을 앞쪽에 두어라
3.4.3 스캔 효율성 이외의 판단 기준
그 외 고려해야 할 판단 기준
1) 수행 빈도
2) 업무상 중요도
3) 클러스팅 팩터
4) 데이터량
5) DML 부하
6) 저장공간
7) 인덱스 관리 비용 등등
설계자의 성향 + 스타일에 따라 결과물이 달라진다.
수행 빈도가 매우 높은 SQL에는 최적의 인덱스를 구성해줘야 한다.
NL조인 인덱스
아웃터 : 비효율 있어도 됨. 인덱스 하든 말든 풀스캔을 하든 상관없다.
이너: 비효율 있으면 안 됨. 여기서 줄여야한다. 인덱스가 작동해야한다.
= 은 선두에
between은 뒤에
테이블 접근 없이 인덱스에서 필터링을 마치도록 구성해라.


3.4.4 공식을 초월한 전략적 설계
조건절 패턴이 10개면 패턴마다 인덱스를 만들면 안 됨.
1) 핵심 액세스 경로: 한두 개를 전략적으로 선택 -> 인덱스 설계
2) 나머지 액세스 경로: 성능을 만족하는 수준으로 인덱스 구성
예시: 가계약 테이블
6개 곱하기 4 =24개의 인덱스를 만들거임?? 아니야..
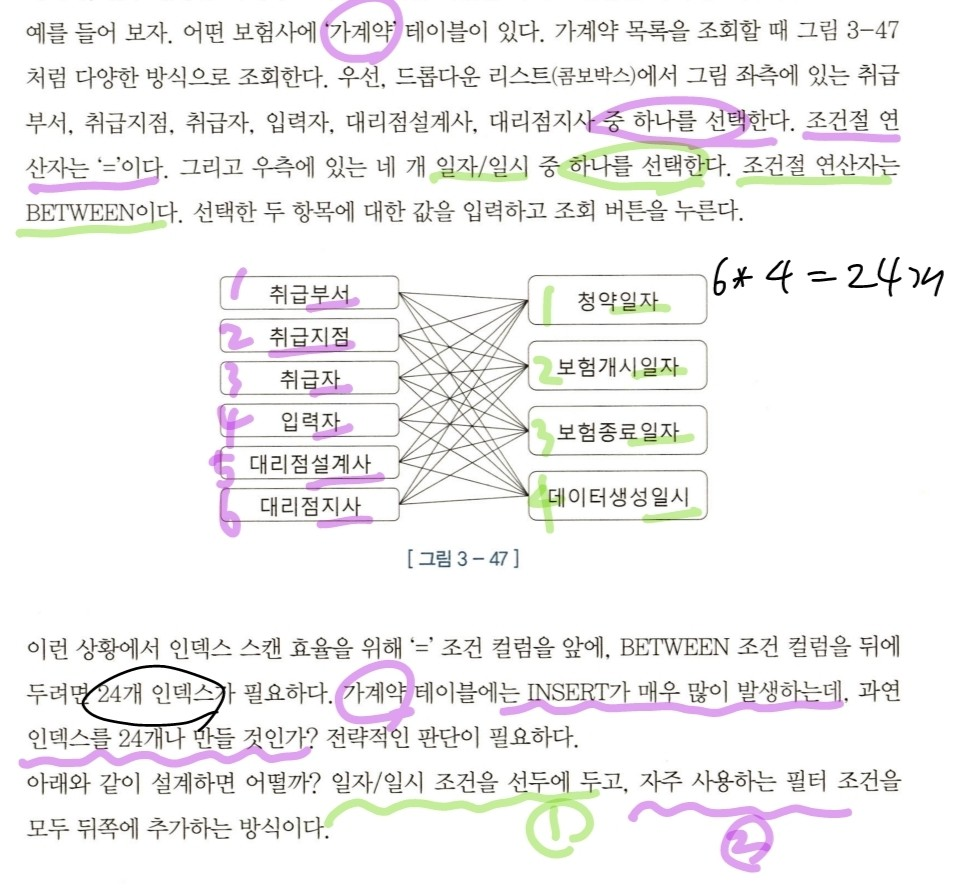
이렇게 튜닝해봐....
1) between 조건인 일자/일시를 선두
2) 자주 사용하는 필터 조건을 뒤쪽에 추가
결과
1) 일자 조회구간은 보통 3일이기때문에... 성능에 미치는 영향이 크지 않다.
2) 인덱스 스캔 효율 < 테이블 액세스가 더 큰 부하 요소다.

결과: 24개 -> 5개로 인덱스를 줄임
이렇게 인덱스 개수를 최소화 하면
사용빈도 높은, 중요한 액세스 경로가 새로 노출됐을 때
인덱스 추가 할 수 있다.
3.4.5 소트 연산을 생략하기 위한 컬럼 추가
인덱스는 항상 정렬 상태 유지하는거 알지..?
order by, group by를 인덱스는 생략할 수 있어... 이미 정렬이 되어있으니까..
소트 연산을 안하려면 인덱스에 추가 해.
그럼 성능이 개선될거야.
1) 소트연산 생략
예시: order by 뒤에 컬럼을 인덱스에 추가 -> 소트 연산 안함

결론: 청약일자, 입력자ID (order by)이렇게 인덱스 사용하셈
| = | 취급지점ID | order by아니여도 인덱스 추가 가능 |
| = 아님 | 입력일자, 계약상태코드 | order by 보다 인덱스 컬럼이 뒤에 있어야함 |
2) 성능 : I/O 최소화
1) = 연산자 사용한 조건절 컬럼 선정
2) order by 절에 기술한 컬럼 추가
3) = 연산자 아닌 조건절 컬럼은... 데이터 분포를 고려해.. 추가할까말까... 여부 결정

결론: 성능까지 챙기고 싶어?
취급지점 (=)
청약일자, 입력자ID (order by)
이렇게 인덱스 써라..
IN조건은 = 이 아니다
응 아니야.
인덱스 내부에서 뒤에 두렴.
혈액형에 집중해줘

이렇게 하면 A집단, O집단.. 나이 순서가 각각 오름차순임
소트연산 생략 못함.
혈액형처럼 IN을 사용한 애를 --> 소트 연산 생략하고 싶어?
=으로 바꾸던가
인덱스에서 뒤에 있거나

3.4.6 결합 인덱스 선택도
3.4.7 중복 인덱스 제거
3.4.8 인덱스 설계도 작성
'학습 기록 (Learning Logs) > 친절한 sql 튜닝' 카테고리의 다른 글
| [6주차] 소트 튜닝 (0) | 2022.04.24 |
|---|---|
| [5주차] 소트 머지 조인 (0) | 2022.04.17 |
| [3주차] 테이블 액세스 최소화 (0) | 2022.04.03 |
| 인덱스 (0) | 2022.03.28 |
| [2주차] 인덱스 2.1 (0) | 2022.03.27 |



