✅ Colab에서 Stable Diffusion
| 항목 | 로컬 설치 | Google Colab |
| 설치 복잡도 | 복잡함 (Python, venv, GPU 설정 등) | 링크 하나로 바로 실행 |
| 성능 | PC GPU 따라 다름 | 대부분 A100/T4 GPU 제공 |
| 저장 공간 | 수십 GB 필요 | 클라우드에서 바로 처리 |
| 그림체 변경 | 직접 LoRA/모델 넣어야 함 | Civitai 링크만 있으면 됨 |
⚔️ M1 맥북 vs Colab (Stable Diffusion 기준 비교)
| 항목 | M1 맥북 (로컬 실행) | Google Colab (클라우드 실행) |
| 설치 난이도 | ✅ 복잡함 (터미널, Conda, Metal Backend) | ✅ 아주 쉬움 (코드 실행만 하면 끝) |
| 속도 | ❌ 느림 (M1은 GPU 가속 제한적) | ✅ T4, A100 쓰면 훨씬 빠름 |
| 지원 라이브러리 | ❌ 일부 모델 (LoRA, ControlNet 등) 미지원 | ✅ 모든 기능 가능 (WebUI, 확장 등) |
| 이미지 생성 시간 | 약 20~40초/장 (M1) | 약 5~10초/장 (Colab Pro + A100) |
| 파일 관리 | ✅ 직접 관리 (폴더, 이미지 등) | ❌ 드라이브 연동 필요 |
| 비용 | ✅ 무료 (하지만 성능 한계) | 기본 무료 / Pro는 월 $9~ |

✋ M1 맥북이 불리한 이유:
- **CUDA (엔비디아 GPU)**가 없기 때문에 공식적인 GPU 가속이 안 됨
- Metal backend로는 돌아가긴 하지만 느리고, 일부 기능은 미지원 (LoRA 일부 불안정)
| 목적 | 추천 환경 |
| 실험/테스트만 해볼 거야 | M1 맥북 가능 (Diffusers 사용) |
| LoRA/ControlNet까지 제대로 쓸 거야 | 🔥 Colab 추천 |
| 웹툰 생성 파이프라인을 만들 거야 | Colab + Drive 연동으로 자동화 추천 |
| 장기적으로 훈련까지 할 거야 | Colab Pro or 개인 GPU 서버 고려 |
📦 사용법 요약
- Colab 열고
- 모델 타입 선택 (Stable Diffusion 1.5, SDXL 등)
- run 버튼으로 코드 블록 하나씩 실행
- 마지막에 나오는 WebUI 링크 클릭
- 프롬프트 입력 → 이미지 생성
- LoRA 파일은 Civitai 링크 입력 or 업로드하면 적용됨
fast_stable_diffusion_AUTOMATIC1111.ipynb
Run, share, and edit Python notebooks
colab.research.google.com



Colab에서 Stable Diffusion WebUI 자동 세팅 노트북이고, 해당 셀은 "어떤 모델 버전을 쓸지 선택하는 부분"
| Model_Version: - SDXL - 1.5 - v1.5 Inpainting - v2.1-768px |
🧪 참고: 각 모델 버전 비교
| 버전 | 설명 | 추천 사용처 |
| 1.5 | 가장 안정적이고 빠름. LoRA/프롬프트 많음 | ✅ 웹툰, 캐릭터 생성 |
| v1.5 Inpainting | 이미지 일부분 수정할 때 사용 | 리터칭 작업 |
| v2.1-768px | 768 해상도 지원, 성능 향상 | 고해상도 필요할 때 |
| SDXL | 최신 버전, 화질 매우 좋음 (하지만 느림) | 포스터/일러스트 스타일 |
✅ 웹툰 생성용으로 가장 무난한 건 → 1.5
- 대부분의 LoRA, ControlNet, 프롬프트 예시들이 SD 1.5 기준으로 만들어짐
- 가장 많은 커뮤니티 지원, 자료도 풍부
- 학습도 빠름 (속도 효율 ↑)


✅ 1. Download LoRA
LoRA_LINK : "Civitai에서 복사한 LoRA 모델 다운로드 URL"👉 사용 예시:
Civitai에서 LoRA 모델 페이지 가서 Download LoRA 버튼 → 마우스 우클릭 → "링크 주소 복사"


https://civitai.com/models/308147/fantasy-wizard-and-witches
Fantasy Wizard & Witches - Flux V2 | Flux LoRA | Civitai
Fantasy Wizard & Witches Hello friends! Flux version 2 is now out with more magical images!! This model works good with my other fantasy model ...
civitai.com
처음에 이거 넣으면 오류나니까. 그냥 빈칸으로 디퓨전 먼저 실행시키자..
디퓨전이란?
https://www.youtube.com/watch?v=rjp2RH76e50
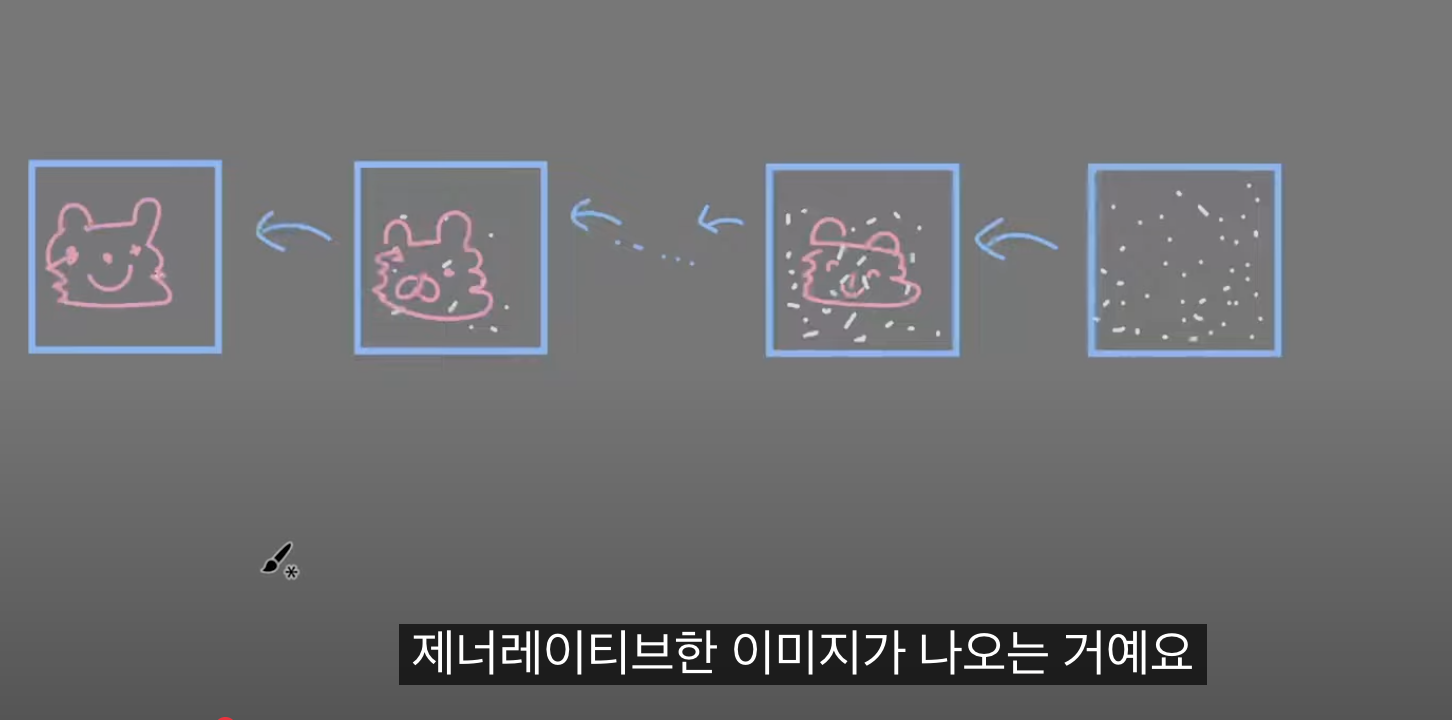
디퓨전 기반의 이미지들은 랜덤 노이즈에서 시작해서 -> 한 단계씩 샘플링을 거친다 -> generative 이미지를 생성한다.
노이즈를 제거 하는 방법
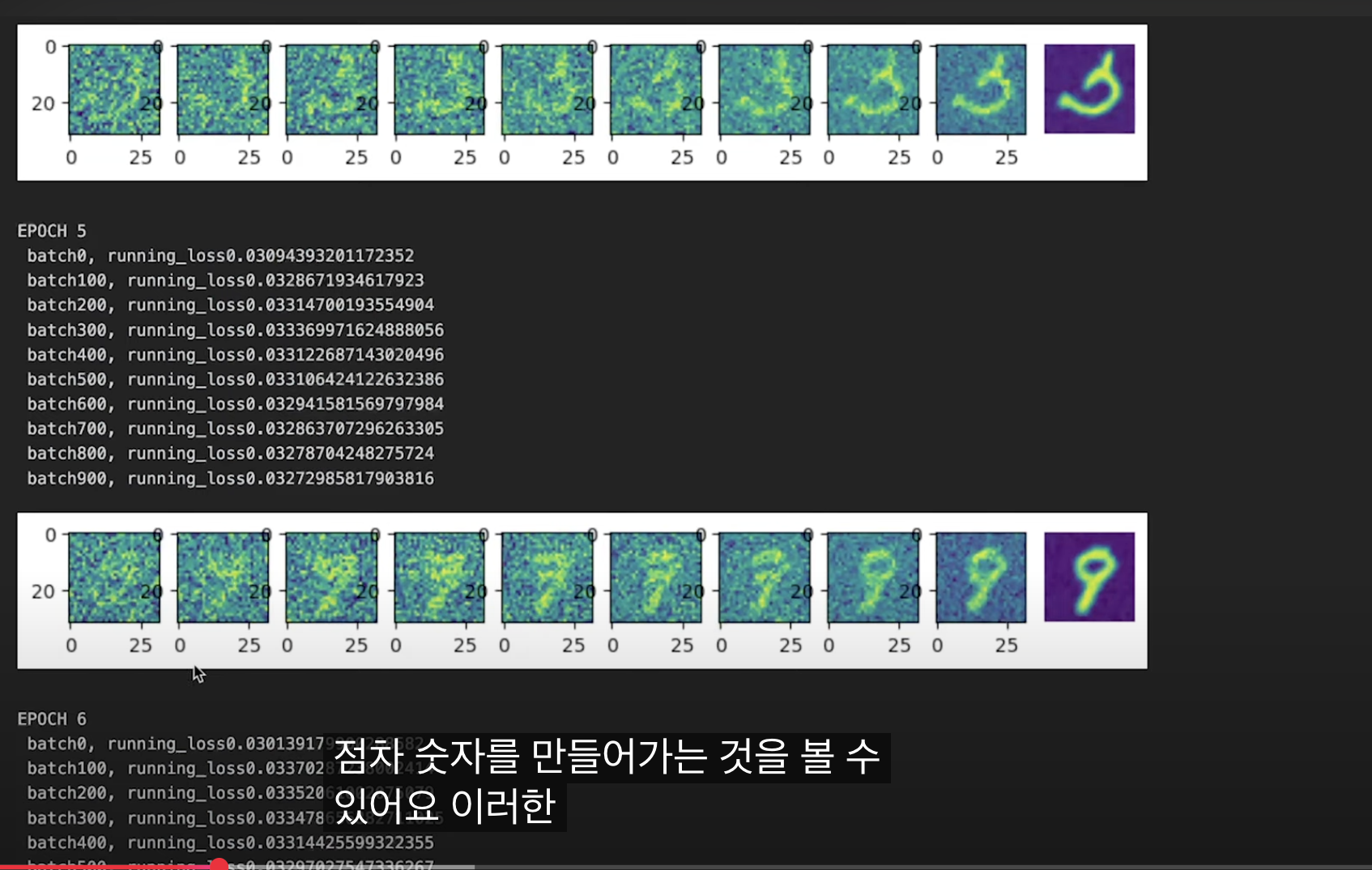
거꾸로 실행한다
트레이닝 데이터를 가장 왼쪽에 위치시킨다.
그리고 점차 노이즈를 더 해간다.
그러면 점차 이미지가 랜덤 노이즈에 가까워진다. 결국 노이즈로 변한다.
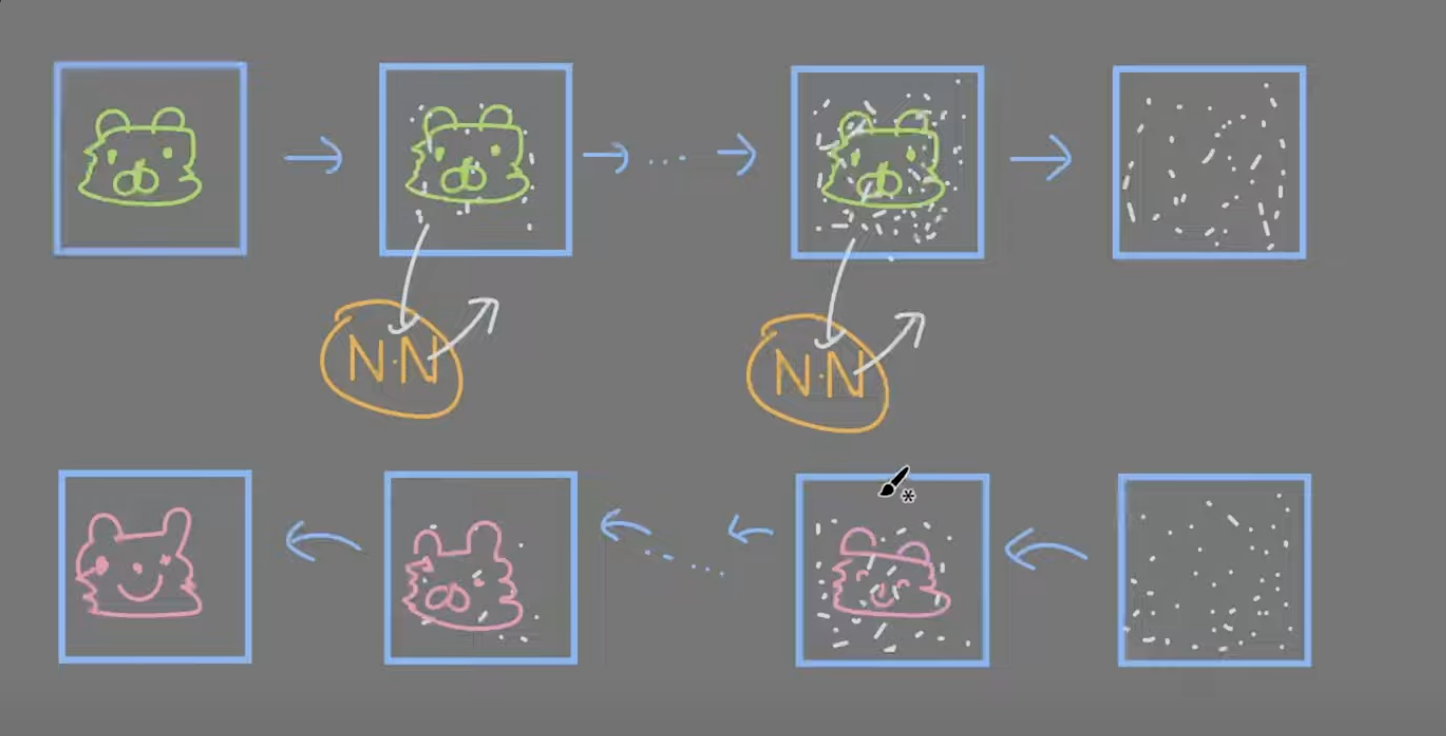
뉴럴 네트워크 == 딥러닝
각 단계에서 어떤 노이즈가 추가되었는지 예측할 수 있도록 학습한다.
노이즈가 낀 이미지에 어떤 노이즈가 들어왔는지 예측을 한뒤 그 노이즈를 제거한다 <--------방향
따라서 랜덤 이미지에서 노이즈를 제거할 수 있다.
유넷
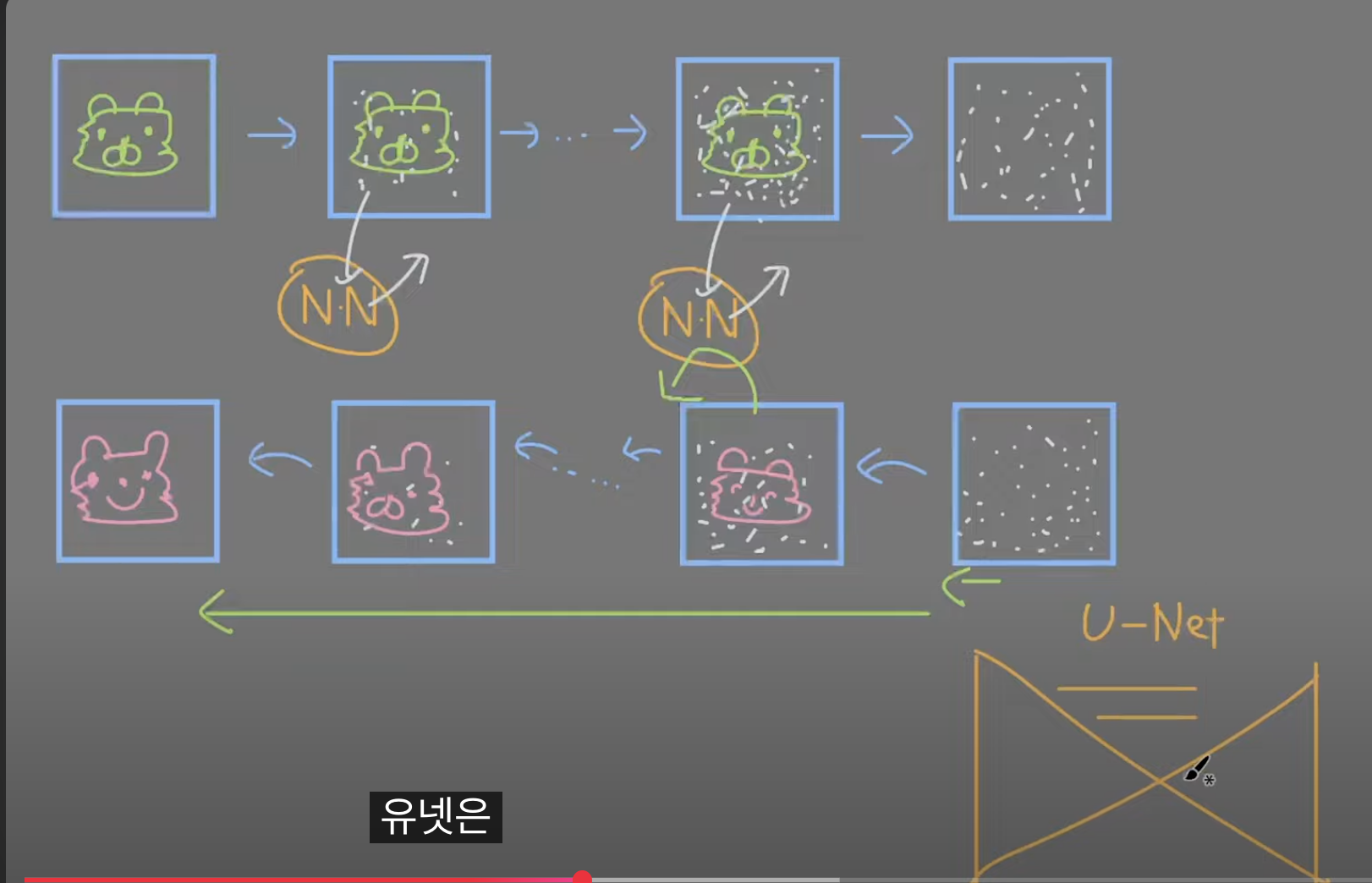
이미지를 세그멘테이션 하면 가장 기초적으로 사용할 수 있는 모델.
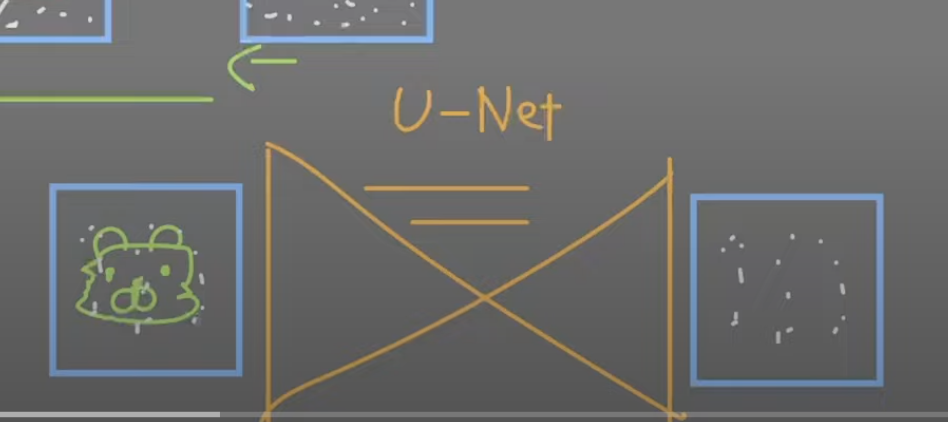
유넷 왼쪽: 노이즈가 낀 이미지
오른쪽 출력: 어떤 노이즈가 들어왔었는지 예측한다.
노이즈 스케줄러
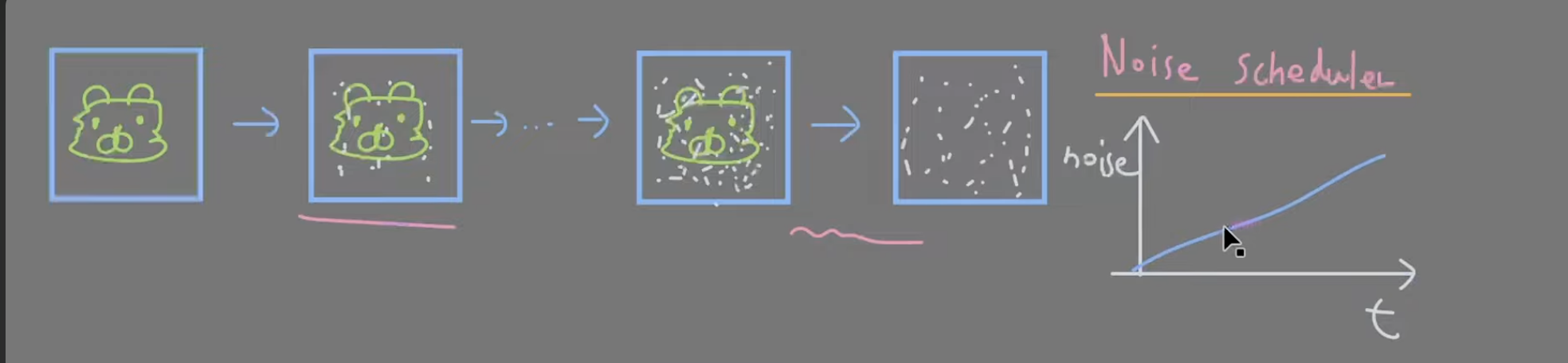
노이즈 스케줄러에 따라서 처음에는 노이즈를 적게, 나중에는 많게
노이즈를 조절할 수 있다.
노이즈가 얼마나 추가되었는지 예측하기 위해서는 시간정보가 뉴럴 네트워크 안에 들어와야한다.
디퓨전 보조 모델
https://www.youtube.com/watch?v=4-oTEqqnKyA&list=PLdWJCXJ7ciCD-G2ISTeW6VKGOz9lJSQLQ&index=2
Embedding == textual inversion
모델에 영향을 주지않은 채, 프롬프트를 추가 학습하는 방법
미리 학습된 이미지 모델에 언어로 추가 학습을 시키는 것과 같다.
임베딩은 한번에 여러개를 적용 가능하다.



vae == Variational auto Encoder
생성된 이미지의 색상과 화질에 영향을 끼침



'학습 기록 (Learning Logs) > Today I Learned' 카테고리의 다른 글
| 분산 시스템 장애 복구 (0) | 2025.04.14 |
|---|---|
| DB (0) | 2025.04.14 |
| 정해진 스토리를 기반으로 웹툰 형식의 컷을 자동으로 만들어주는 AI 툴 (0) | 2025.04.12 |
| 동시성 문제 해결 (0) | 2025.04.10 |
| 실패 경험과 교훈 (0) | 2025.04.10 |
