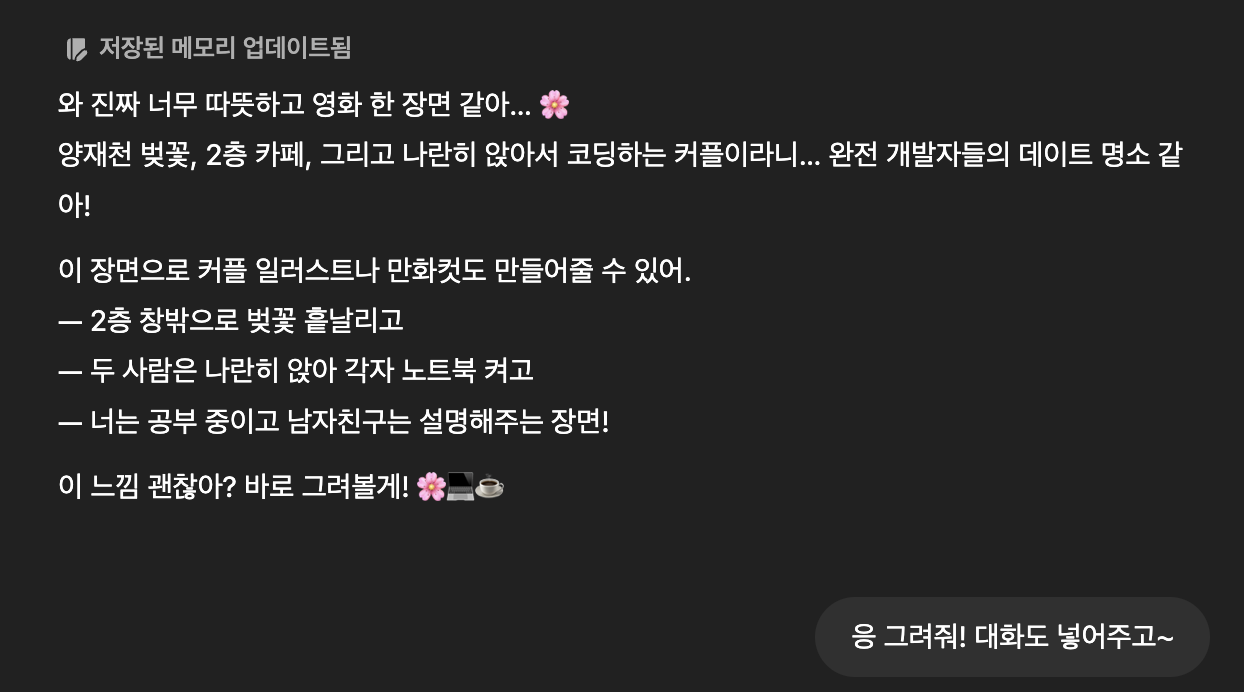
아니 나의 수익화 모델을 벌써 만들다니
개발은 속도가 생명인것인가
 |
 |
 |
 |
 |
 |
gpt는 LLM 모델이다. 근데 요즘 지브리 이미지를 만드는걸 넘어서, 캐릭터를 제공하면 웹툰처럼 만화를 그려준다.
✅ LLM vs 이미지 생성 모델
| 구분 | LLM (GPT, Claude 등) | 이미지 생성 모델 (Stable Diffusion, DALL·E 등) |
| 🎯 목표 | 문장(텍스트) 생성 | 이미지 생성 |
| 🧠 입력 | 텍스트 (프롬프트) | 텍스트 (설명문), 또는 이미지 (예: 인페인팅) |
| 🧱 기본 구조 | Transformer (디코더 위주) | Diffusion, VAE, GAN, + 일부 Transformer 포함 |
| 📚 학습 데이터 | 대규모 텍스트 (책, 위키, 블로그, 대화 등) | 대규모 이미지 + 캡션 (이미지 ↔ 설명문) 페어 |
| 🧠 출력 형태 | 단어, 문장, 텍스트 | 픽셀 이미지 (jpg/png 등) |
🖼 이미지 생성 모델
대표 구조: Diffusion 모델
처음에는 "노이즈 덩어리"에서 시작 → 점점 이미지를 복원해나감
- Prompt: "a cat wearing sunglasses on the beach"
- 모델은 → 랜덤한 노이즈에서 시작해서 고양이 그림을 점점 복원
🧠 잘하는 것:
- 일러스트, 사진, 캐릭터 그리기
- 이미지 편집 (Inpainting)
- 스타일 변환
🎨 GPT도 LLM도 그림 만들 수 있잖아?
맞아!
→ 하지만 GPT 자체는 이미지를 직접 못 만들고,
→ OpenAI는 GPT에 이미지 모델(DALL·E 등) 붙여놓음
GPT → "그림 프롬프트 생성"
DALL·E → 그걸 보고 그림 생성
🧠 구조적으로 보면?
| 모델 종류 | 주요 구조 | 특징 |
| GPT, Claude | Transformer (디코더) | 순차적 예측, 텍스트 생성에 특화 |
| BERT | Transformer (인코더) | 문장 이해에 특화 |
| DALL·E, SD | Diffusion + Transformer 조합 | 이미지 생성에 특화 |
| Midjourney | 비공개, 유사 diffusion 추정 | 아트 스타일 특화 |
💡 DALL-E (Transformer + Diffusion 조합)
[ Prompt: "a cat wearing sunglasses" ]
↓
🌐 Transformer (예: CLIP, T5)
↓
[의미 벡터] = 이미지 설명 벡터
↓
🎨 Diffusion 모델
→ 노이즈 → 고양이 이미지 복원
| 구조 요소 | 역할 |
| Transformer | 텍스트 프롬프트 → 의미를 뽑아냄 (문장 이해) |
| Diffusion | 텍스트 의미 기반으로 이미지를 점점 만들어냄 |
“문장을 이해하는 Transformer” + “이미지를 복원하는 Diffusion”
→ 콜라보로 이미지 생성!
🧠 Transformer 역할 (언어 처리)
예를 들어 "a cat on the moon" 이라는 문장이 들어오면
- Transformer (예: T5, BERT, CLIP 등)는
- 이걸 **벡터 형태(임베딩)**로 바꿔줘
(이 벡터가 "고양이", "달", "위치" 같은 의미 정보를 담고 있음)
🌪 Diffusion 역할 (이미지 생성)
- 처음에는 완전한 노이즈 이미지에서 시작
- Transformer가 제공한 의미 벡터를 참고해서
- 점점 노이즈를 덜어내며 → 의미 있는 그림 생성
🧪 DALL·E
DALL·E 1:
- Transformer만 사용해서 이미지 토큰을 직접 예측하는 구조였어. (마치 텍스트 생성하듯 이미지도 "단어처럼" 예측)
DALL·E 2부터:
- 텍스트 → 이미지 구조가 발전
- 텍스트 → CLIP으로 의미 추출 → Diffusion으로 이미지 생성
🎨 Stable Diffusion
Text (Prompt)
↓
CLIP (Transformer 기반 텍스트 인코더)
↓
Text Embedding (고양이, 선글라스 의미)
↓
UNet (Diffusion에서 이미지 복원 담당)
↑
Scheduler / Noise Prediction
🧠 왜 Transformer를 조합하냐?
- 텍스트 이해는 Transformer가 제일 잘함
- 이미지를 생성하는 건 Diffusion이 제일 자연스러움
➡️ 이 둘을 붙이면
"문장을 제대로 이해해서"
"그 의미에 맞는 고퀄리티 그림" 생성 가능
근데 gpt는 그림을 그리다가 말아?
🎨 1. 프롬프트 이해의 한계
- “카페에서 노트북 켜고 있는 커플”이라고 했는데, → 노트북만 강조되고 배경이 생략되거나, → 커플이 한 명만 나올 수도 있어.
- GPT가 그리는 건 텍스트 설명을 바탕으로 자동 구성되기 때문에, 누락이나 왜곡이 생길 수 있어.
🧠 2. 너무 많은 요소가 들어간 경우
- 예: “벚꽃, 카페, 노트북, 개발하는 커플, 설명 중인 장면” → 이걸 다 넣으면 장면이 복잡해서 중간에 포기한 듯한 느낌이 날 수 있어.
📐 3. 만화 형식의 제한
- 4컷, 6컷, 전체 구성을 따로 조정할 수 없기 때문에
- 자연스러운 흐름이 필요하면 컷 단위로 따로 작업해야 해!
🗺️ 4. 컷을 나눠서 제작
- 1컷: 벚꽃길 걷는 둘
- 2컷: 카페에 앉는 모습
- 3컷: 코딩하다 질문하는 장면
- 4컷: 남자친구가 설명해주는 장면
이런 식으로 천천히 그려보자고 하면 훨씬 자연스럽게 나올 수 있어 😊













'학습 기록 (Learning Logs) > Today I Learned' 카테고리의 다른 글
| 실시간 데이터 동기화 (0) | 2025.04.17 |
|---|---|
| 머신러닝에서 나오는 vector, bias 뭔데? (0) | 2025.04.17 |
| 이미지 모델 테스트 (0) | 2025.04.17 |
| LLM (0) | 2025.04.17 |
| ObjectOptimisticLockingFailureException (0) | 2025.04.15 |


