
공통 질문
RDB와 NoSQL DB의 차이점을 설명해주세요.
데이터베이스에서 인덱스를 사용하는 이유와 인덱스가 성능에 미치는 영향을 설명해주세요.
트랜잭션(Transaction)이 무엇이며, ACID 특성을 설명해 주세요.
데이터베이스에서 JOIN의 개념과 사용 사례를 설명해주세요.
외래 키(Foreign Key)와 참조 무결성(Referential Integrity)에 대해 설명해주세요.
데이터베이스 샤딩(Sharding)이란 무엇인가요?
데이터베이스에서 파티셔닝(Partitioning)을 적용하는 이유를 설명하고, 수평/수직 파티셔닝의 차이점을 설명해주세요.
RDB와 NoSQL DB의 차이점을 설명해주세요.
1. 데이터 모델
Relational Database
각 데이터를 테이블 형식으로 저장(행, 열)
테이블은 스키마를 따라야한다
테이블 간 관계를 foreign ket로 정의한다

NoSQL DB
정형화된 스키마가 없다. 다양한 데이터 모델을 지원한다
key-value
ex) redis, dynamoDB
document
json 형태로 데이터를 저장
ex) MongoDB
{
"ID": 1,
"Name": "Alice",
"Age": 25
}
Graph
노드와 엣지로 데이터를 표현
ex) Neo4j, ArangoDB
Column-Family
데이터를 열단위로 저장
ex) Cassandra, Hbase
2. Schema
RDB
고정된 스키마를 사용
데이터를 삽입하려면 테이블 구조를 미리 정의 해야한다
스키마를 변경하는 작업은 복잡하고, 성능에 영향을 줄 수 있다
NoSQL DB
유연한 스키마 ㅅ용
동일한 컬렉션에 다른 구조의 데이터를 저장할 수 있다
데이터 구조가 변경 가능성이 높거나, 동적일 경우 적합
3. 확장성
RDB
수직 확장: 강력한 하드웨어로 업그레이드해서 성능을 높인다
수평 확장: 데이터 샤딩, 파티셔닝
NoSQL DB
수평 확장: 여러 서버에 데이터를 분산하여 처리 가능
분산환경에서 대용량 데이터를 효율적으로 처리 가능
4. 트랜잭션 지원 여부
RDB
ACID 준수
Automicity, Consistency, Isolation, Durability
강령학 데이터 일관성을 보장, 트랜잭션이 중요할때 사용
NoSQL DB
BASE 준수
Basically Available, Soft state, Eventually consistent
데이터의 일관성보다는 가용성, 확장성을 중시
일부 NoSQL DB는 제한적인 ACID를 지원한다(MongoDB, Cassandra)
5. 사용 사례
RDB
데이터 관계가 복잡 && 강력한 데이터 무결성 필요
데이터 모델, 쿼리가 안정적인 경우
ex) 은행, 전자상거래, ERP 시스템
NoSQL DB
데이터 구조가 유연하고, 실시간으로 대량의 데이터를 처리해야하는 경우
빠른 읽기/쓰기 성능이 요구되는 경우 적합
ex) social media, IoT데이터, 로그 데이터 분석
데이터베이스에서 인덱스를 사용하는 이유와 인덱스가 성능에 미치는 영향을 설명해주세요.
인덱스
db table에서 특정 열의 검색 속도를 높이기 위한 데이터 구조
대량의 데이터를 효과적으로 조회, 정렬, 필터링 하기 위해 사용.
주요 역할
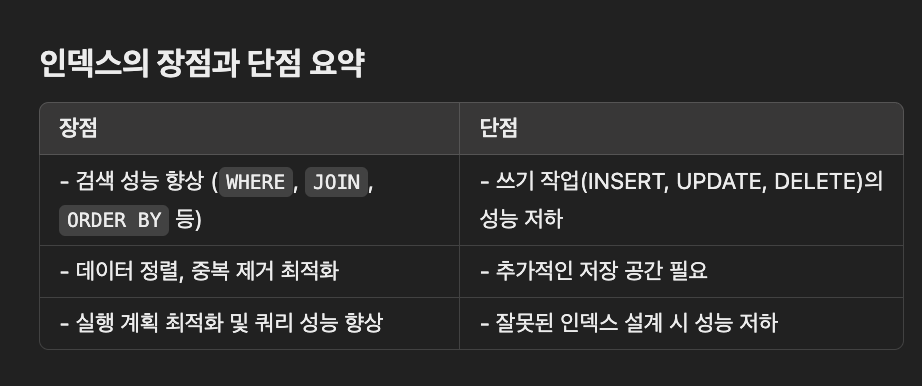
1) 검색 속도 향상
테이블의 특정 열에 인덱스를 생성하면 해당 열의 데이터를 검색할때 전체 테이블 스캔을 피한다. 인덱스를 통해 검색을 빠르게 수행.
2) 데이터 정렬
인덱스는 기본적으로 데이터가 정렬된 상태로 유지됨, order by, group by 같은 작업을 빠르게 처리 가능
3) 참조 무결성 유지
foreign key 제약 조건이 있는 경우, 데이터 무결성을 유지하기 위해 내부적으로 인덱스를 생성한다
4) 중복방지
unique 제약 조건을 적용할때 인덱스가 사용된다. 데이터 중복 여부를 빠르게 확인 가능
인덱스가 성능에 미치는 영향
1) 긍정: 쿼리 성능 향상
select 문에서 특정 열에 대한 where, join, order by 조건을 사용할때 인덱스를 사용하면 속도가 빨라진다.
인덱스가 없으면 테이블에서 전체 스캔을 해서 모든 행을 확인한다.
// 인덱스 없이
SELECT * FROM employees WHERE name = 'John';
// 인덱스 활용
CREATE INDEX idx_name ON employees(name);
SELECT * FROM employees WHERE name = 'John';
2) 긍정: 데이터 정렬, 집계 최적
order by, group by, distinct 작업에서 인덱스가 있으면 정렬, 중복 제거를 효율적으로 수행 가능
1) 부정: 쓰기 성능 저하
인덱스를 추가하면 insert, update, delete 작업시 추가적 작업 발생
2) 부정: 저장공간 증가
인덱스는 별도의 데이터 구조(B-Tree, Hash)를 생성하므로, 테이블 크기에 비례하여 추가 저장 공간 필요
3) 부정: 잘못된 인덱스 설계
인덱스가 너무 많은 경우: 데이터를 삽입, 수정, 삭제 시 인덱스를 모두 갱신해야하므로 성능 저하
너무 큰 인덱스: 다중 열 인덱스를 비효율적으로 생성하면 성능에 부정적 영향
사용시 고려사항
1) 자주 검색, 자주 조건으로 사용되는 열
where, join, order by, group by에서 자주 사용되는 열
2) 적절한 인덱스 수 유지
테이블에 너무 많은 인덱스를 생성하면 쓰기 작업이 느려짐, 꼭 필요한 열에만 생성
3) 데이터 분포 고려
인덱스는 중복도가 낮고, 값의 분포가 고르게 퍼져 있는 열에서 효과적
인덱스의 동작 구조
1. B-Tree 인덱스
- B-Tree는 가장 널리 사용되는 인덱스 구조로, 데이터가 정렬된 상태로 저장됩니다.
- 동작 원리:
- 루트 노드(Root)에서 시작하여 자식 노드(Child)로 이동하며 값을 검색.
- 값을 찾기 위해 트리를 내려가는 데 걸리는 시간은 트리의 높이에 비례.
- 데이터가 정렬된 상태로 유지되므로, 범위 검색(BETWEEN, >, <)에 유리.
- 예:
- SELECT * FROM users WHERE age BETWEEN 20 AND 30;
- 인덱스가 있는 경우, B-Tree는 20과 30 사이의 값을 빠르게 검색.
- SELECT * FROM users WHERE age BETWEEN 20 AND 30;
2. Hash 인덱스
- Hash Table을 기반으로 하는 인덱스.
- 동작 원리:
- 해시 함수를 사용하여 키 값을 해시 값으로 변환한 뒤, 해당 위치에서 데이터를 찾음.
- 정확한 값 비교(=)에는 빠르지만, 정렬이나 범위 검색에는 적합하지 않음.
- 예:
- SELECT * FROM users WHERE id = 100;
- id 열에 해시 인덱스가 있는 경우, 100의 해시 값을 계산하여 데이터를 바로 조회.
- SELECT * FROM users WHERE id = 100;
3. 다른 데이터 구조
- Bitmap 인덱스: 값의 분포가 적은 열(예: 성별, 상태)에서 사용.
- Full-Text 인덱스: 텍스트 검색에 최적화.
Integrity?
완전함, 온전함, 정직함
결함 없이, 온전하고 훼손되지 않은 상태
무결성?
db에서 무결성은 data가 정확, 일관, 신뢰할 수 있는 상태를 유지하는 것.
무결성 유지의 중요성
1) 데이터 신뢰 향상
잘못된 data가 저장되지 않도록 함
2) 데이터 일관성 보장
data가 모순되지 않도록 유지, 부모-자식 테이블 간 관계를 올바르게 유지
3) 오류 방지
잘못된 data로 인해 발생할 문제를 방지
4) 보안 강화
허용되지 않은 data 입력을 차단
개체 무결성(Entity Integrity)
db의 모든 행이 고유하게 식별되도록 보장
primary key가 설정되어야 한다. 키는 중복될수 없다. Null 안된다.
참조 무결성(Referential Integrity)
두 테이블 간에 관계를 올바르게 유지하도록 보장
foreign key를 통해 부모 테이블의 데이터가 존재해야 자식 테이블에서 참조할 수 있다.
CREATE TABLE users (
user_id INT PRIMARY KEY,
name VARCHAR(100)
);
CREATE TABLE orders (
order_id INT PRIMARY KEY,
user_id INT,
FOREIGN KEY (user_id) REFERENCES users(user_id) -- 참조 무결성 보장
);
참조 무결성이 깨진다:
부모 테이블에 없는 값을 자식 테이블에서 참조
부모 테이블에서 삭제된 데이터를 자식 테이블이 여전히 참조
도메인 무결성(Domain Integrity)
열에 저장할 수 있는 데이터 유형을 정의하고, 유효하지 않으면 저장하지 않도록 보장
제약 조건을 통해 데이터 허용 범위를 지정한다
CREATE TABLE employees (
employee_id INT PRIMARY KEY,
age INT CHECK (age >= 0), -- 나이는 0 이상이어야 함
month INT CHECK (month BETWEEN 1 AND 12) -- 월은 1~12 사이여야 함
);
사용자 정의 무결성(User-Defined Integrity)
특정 비지니스 로직에 맞춘 사용자 정의 규칙을 정의하여 무결성을 보장
stored procedure, trigger를 사용하여 구현
ex) 은행 시스템에서 계좌 잔액은 항상 0 이상이어야 하고, 특정 조건을 만족하는 트랜잭션만 허용
CREATE TRIGGER check_balance
BEFORE INSERT OR UPDATE ON accounts
FOR EACH ROW
BEGIN
IF NEW.balance < 0 THEN
SIGNAL SQLSTATE '45000'
SET MESSAGE_TEXT = '잔액은 0 이상이어야 합니다.';
END IF;
END;
무결성 제약 조건

트랜잭션(Transaction)이 무엇이며, ACID 특성을 설명해 주세요.
ACID
Automicity, Consistency, Isolation, Durability
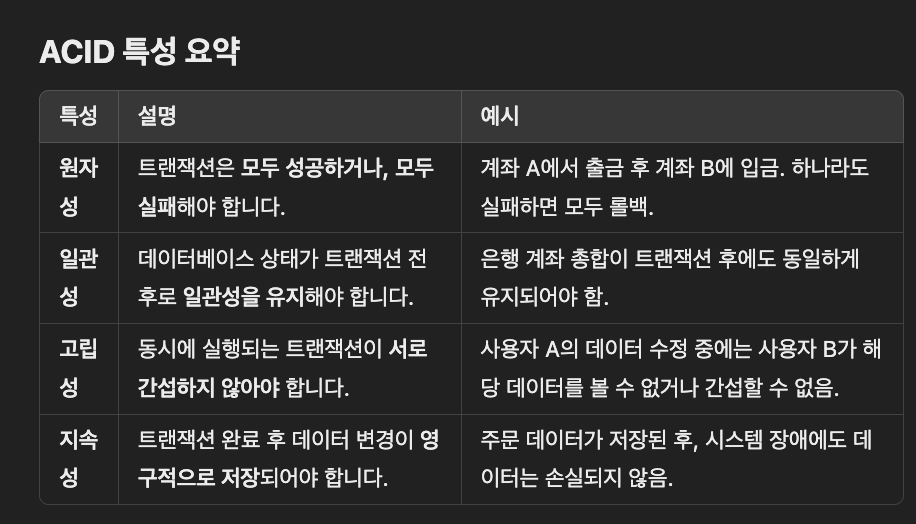
원자성 Automicity
트랜잭션 내의 모든 작업은 '전부 성공/ 전부 실패' 해야 한다
트랜잭션 내의 작업은 하나의 '단위'로 취급되어, 일부만 완료되는 상태는 허용되지 않는다.
일관성 Consistency
트랜잭션이 시작전, 완료 후의 데이터베이스 상태는 일관성을 유지해야한다
foreign key, unique key, data type 처럼 제약 조건은 항상 유지되어야 한다
ex) 은행 계좌의 총합이 1억이면, 트랜잭션 이후에도 총합이 여전히 1억원
고립성 Isolation
동시에 실행되는 트랜잭션은 서로 간섭하지 않아야한다.
독립적으로 수행한 것과 동일한 결과를 보장
트랜잭셕이 진행 중인 데이터는 다른 트랜잭션에서 볼수 없다. 영향을 줄 수 없다.
ex) 사용자 A가 상품 재고를 조회 중일 때, 사용자 B가 같은 상품의 재고를 업데이트하더라도, A는 트랜잭션이 완료되기 전까지 업데이트된 데이터를 볼 수 없다
지속성 Durability
트랜잭션이 성공적으로 완료되면 변경 사항은 영구적으로 저장된다
시스템 장애로 인해 복구 후에도 변경된 데이터는 유지된다
ex) 상품 주문 트랜잭션이 성공한 후, 서버가 갑자기 재부팅되더라도 주문 데이터는 손실되지 않아야 한다
ACID 특성의 필요성
1) 데이터 신뢰성 보장
데이터베이스는 중요한 데이터를 다루므로, 트랜잭션 실패시 데이터가 다른 것에 영향을 주지 않도록 보장한다
2) 동시성 문제 해결
여러 사용자가 동시에 같은 데이터에 접근하여 변경해도 데이터 충돌을 방지한다
3) 안정적 장애 복구
시스템 중단, 장애 발생 후에도 데이터 무결성과 일관성 유지된다.
예제
--- 1. 트랜잭션 시작, 커밋, 롤백
-- 트랜잭션 시작
START TRANSACTION;
-- 데이터 삽입
INSERT INTO accounts (account_id, balance) VALUES (1, 1000);
UPDATE accounts SET balance = balance - 500 WHERE account_id = 1;
UPDATE accounts SET balance = balance + 500 WHERE account_id = 2;
-- 모든 작업 성공 시 커밋
COMMIT;
-- 실패 시 롤백
ROLLBACK;
--- 2. 트랜잭션을 활용한 동시성 문제 해결
SET TRANSACTION ISOLATION LEVEL SERIALIZABLE;
START TRANSACTION;
SELECT * FROM accounts WHERE account_id = 1 FOR UPDATE;
-- 이 쿼리는 계좌를 수정하려는 다른 트랜잭션을 차단.
UPDATE accounts SET balance = balance - 500 WHERE account_id = 1;
COMMIT;
데이터베이스에서 JOIN의 개념과 사용 사례를 설명해주세요.
JOIN
db에서 두개 이상의 테이블을 연결할때 데이터를 조회할때 사용되는 SQL 연산
테이블 간에 공통 colunm key를 기준으로 원하는 결과를 가져옴
종류
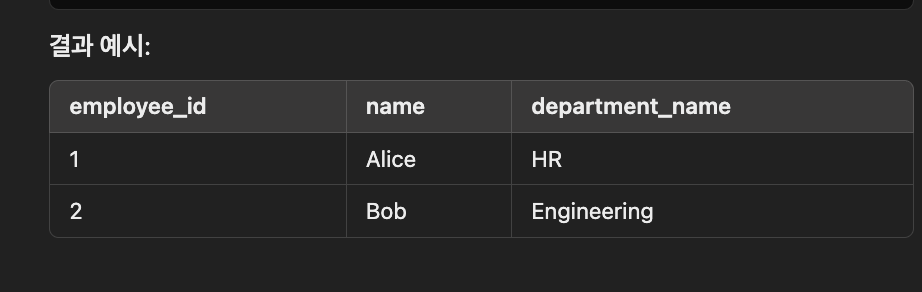
INNER JOIN (내부 조인)
두 table의 공통된 data만 반환
조건이 맞지 않는 data 제외
SELECT e.employee_id, e.name, d.department_name
FROM employees e
INNER JOIN departments d
ON e.department_id = d.department_id;
LEFT JOIN (LEFT OUTER JOIN)
왼쪽 table의 모든 데이터, 조건 일치하는 오른쪽 table의 data 반환
오른쪽 table에 조건이 안맞는 data는 null로 채움
SELECT e.employee_id, e.name, d.department_name
FROM employees e
LEFT JOIN departments d
ON e.department_id = d.department_id;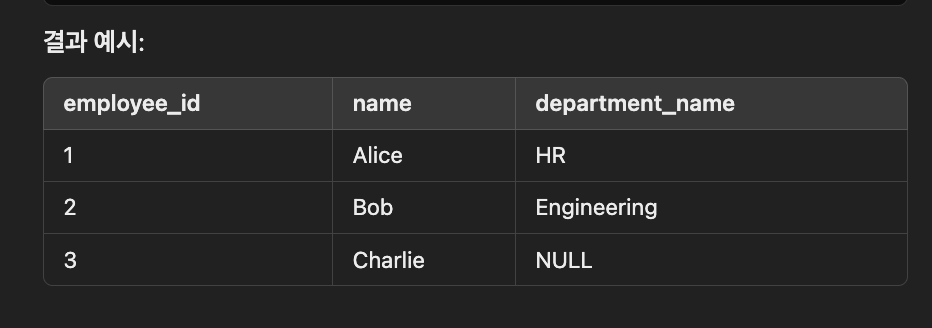
RIGHT JOIN (RIGHT OUTER JOIN)
오른쪽 table의 모든 데이터, 조건 일치하는 왼쪽 table의 data 반환
왼쪽 table에 조건이 안맞는 data는 null로 채움
FULL JOIN (FULL OUTER JOIN)
두 table의 모든 데이터 반환
조건에 맞지 않는 데이터는 null로 채움
CROSS JOIN
두 테이블의 모든 행의 곱을 반환
모든 조합을 가져오기때문에 조건이 없으면 결과가 너무 많아짐
SELECT e.name, p.project_name
FROM employees e
CROSS JOIN projects p;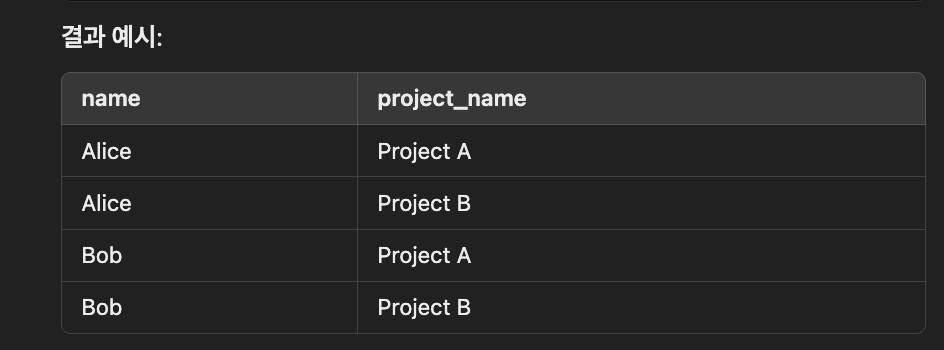
SELF JOIN
동일한 테이블을 두번 사용하여 자기 자신과 조인
-- 직원 테이블에서 관리자와 직원의 관계를 조회
SELECT e1.name AS employee, e2.name AS manager
FROM employees e1
LEFT JOIN employees e2
ON e1.manager_id = e2.employee_id;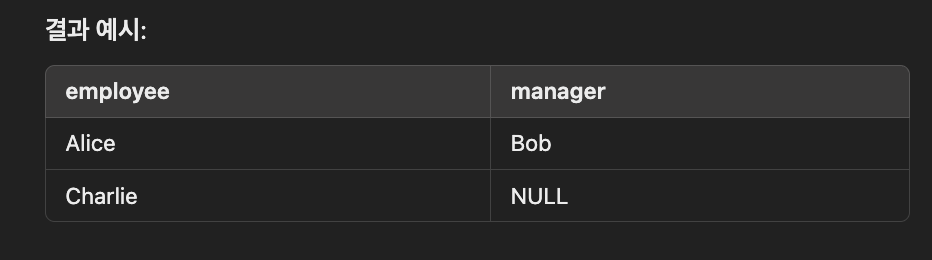
Join 장단점
장점
1) 데이터 관계 표현
테이블간 관계를 이용해 의미 있는 데이터 추출 가능
ex) 직원과 부서 정보를 결합하여 조회
2) sql 간단 조작
여러 테이블의 데이터를 조합하여 간단한 쿼리 -> 복잡 분석 가능
단점
1) 성능 저하 가능성
큰 테이블 간의 join은 많은 데이터를 처리하므로 성능 저하
해결책: 인덱스 활용, where 조건 추가
2) 결과 데이터 복잡성 증가
많은 테이블을 join하면 결과가 복잡, 가독성 떨어짐
외래 키(Foreign Key)와 참조 무결성(Referential Integrity)에 대해 설명해주세요.
foreign key?
외래키는 db에서 두 table 간의 관계를 정의하는 데 사용되는 제약 조건.
부모 table의 특정 열을 자식 table의 primary key or unique key로 참조하도록 설정함
역할
1) 테이블 간 관계 설정
2) 데이터 일관성, 무결성 보장
3) 잘못된 데이터 삽입 방지
참조 무결성
외래키를 사용하는 테이블들 간의 데이터 관계를 유지하기 위한 규칙
1) 자식 테이블의 외래키는 부모 테이블에 존재한다
2) 부모 테이블의 data가 삭제/변경 시 -> 자식 테이블의 관계 처리
참조 무결성이 꺠지는 경우
1) 자식 테이블의 외래키가 부모 테이블에 없는 값을 참조하려고 할 때
2) 부모 테이블의 데이터가 삭제/수정 -> 자식 테이블에서 참조할 데이터가 없을 때
외래 키 제약 조건 문법
-- 테이블 생성 시 외래 키 설정
CREATE TABLE 부모테이블 (
id INT PRIMARY KEY,
name VARCHAR(100)
);
CREATE TABLE 자식테이블 (
child_id INT PRIMARY KEY,
parent_id INT,
FOREIGN KEY (parent_id) REFERENCES 부모테이블(id)
);
-- 테이블 생성 후 외래 키 추가
ALTER TABLE 자식테이블
ADD CONSTRAINT fk_parent FOREIGN KEY (parent_id) REFERENCES 부모테이블(id);
참조 무결성 동작 방식
foreign key 제약 조건을 사용하면 부모 테이블에서 수정/삭제 할때 규칙이 적용된다
이 규칙은 ON UPDATE/ON DELETE 옵션으로 설정됨
1) CASCADE
부모 테이블의 행 수정/삭제 -> 자식 테이블의 행 수정/삭제
2) SET NULL
부모 테이블의 행 수정/삭제 -> 자식 테이블의 foreign key 값을 null 설정
3) SET DEFAULT
부모 테이블의 행 수정/삭제 -> 자식 테이블의 foreign key 값을 default 설정
4) NO ACTION
부모 테이블의 행 수정/삭제 못하게 막음
5) RESTRICT
부모 테이블의 행 수정/삭제 못하게 제한, 즉시 적용
CREATE TABLE 부모테이블 (
id INT PRIMARY KEY,
name VARCHAR(100)
);
CREATE TABLE 자식테이블 (
child_id INT PRIMARY KEY,
parent_id INT,
FOREIGN KEY (parent_id) REFERENCES 부모테이블(id)
ON DELETE CASCADE
ON UPDATE SET NULL
);
-- ON DELETE CASCADE:
-- 부모 테이블의 행이 삭제되면, 자식 테이블에서 해당 행도 자동으로 삭제
-- ON UPDATE SET NULL:
-- 부모 테이블의 기본 키가 수정되면, 자식 테이블의 외래 키 값이 NULL로 설정
-- 학생이 수강 중인 강의 데이터를 저장할 때:
CREATE TABLE courses (
course_id INT PRIMARY KEY,
course_name VARCHAR(100)
);
CREATE TABLE students (
student_id INT PRIMARY KEY,
course_id INT,
FOREIGN KEY (course_id) REFERENCES courses(course_id)
ON DELETE SET NULL
);
-- 고객과 주문 정보를 저장할 때:
CREATE TABLE customers (
customer_id INT PRIMARY KEY,
customer_name VARCHAR(100)
);
CREATE TABLE orders (
order_id INT PRIMARY KEY,
customer_id INT,
FOREIGN KEY (customer_id) REFERENCES customers(customer_id)
ON DELETE CASCADE
ON UPDATE NO ACTION
);
장단점
장점
1) 데이터 무결성 보장
부모-자식 관계의 일관성, 신뢰성 유지
2) 데이터 변경 관리
부모 테이블의 data를 자동으로 관리 -> 데이터 정합성 유지
3) 관계 명시
테이블 간 관계를 명확히 정의 -> db 설계의 가독성을 높힘
단점
1) 복잡한 구조
다수의 외래키로 테이블 관계가 복잡해질 수 있음
2) 성능 저하 가능성
외래키(제약조건)으로 인해 insert, delete, update가 느려질 수 있음
3) 유연성 부족
유연한 데이터 처리가 어려움
데이터베이스 샤딩(Sharding)이란 무엇인가요?
sharding?
data를 여러개의 작은 단위(shard)로 나누어 저장하는 방법
수평적 분할 기업: 대규모 데이터를 효율적으로 처리, db 성능을 향상시키기 위한 기법
하나의 db에 모든 data를 저장하지 않고, data를 여러개의 서버 또는 db에 분산하여 저장.
각 shard는 독립된 db 역할을 함, 특정 data를 담당
목적
1) 성능 향상
data의 조회, 삽입, 업데이트 속도를 높이기 위해 부하 분산
shard를 병렬처리하여 요청 처리 속도를 향상
2) 확장성
data가 증가해도, shard를 추가하여 시스템 확장
수평적 확장
3) 가용성
특정 shard가 문제 생겨도, 다른 shard가 정상적으로 작동하기 때문에 db의 가용성 높음
4) 대용량 데이터 처리
data가 너무 커서 하나의 db에 저장할 수 없는 경우, data를 나눠서 여러 서버로 저장.
방식
Range-based Sharding
data를 특정 범위로 나누어서 shard에 저장
ex) 사용자 ID가 11,000은 샤드 1에, 1,0012,000은 샤드 2에 저장
Hash-based Sharding
특정 key를 hasing하여 결과 값을 기준으로 data를 shard에 저장
ex) hard_id = hash(user_id) % number_of_shards
장점: 데이터 찾기 빠름
단점: shard수 변경 시, data 재배치 필요
Geographic Sharding
나라별로 data 저장
ex) 유럽 사용자는 샤드 1, 아시아 사용자는 샤드 2
장점: 지역별 요청 처리 최적화
단점: data 분포가 지역에 따라 불균형
Custom Sharding
비지니스 로직에 따라 data를 shard에 분배
ex) 회사별, 카테고리별
장점: 특정 비지니스에 맞게 최적화
단점: 설계, 관리 복잡
동작 방식
1) shard key 선택
data를 나누는 기준이 되는 키
2) data 라우팅
app에 요청을 보낼때 shard key를 기반으로 data 저장/요청
3) shard에서 data 처리
각 shard는 독립적으로 data를 처리하고 결과 반환
장단점
장점
1) 성능 향상
db 부하 감소
2) 확장성
data 증가에 따라 shard 추가
3) 가용성
shard 하나가 고장나도, 다른 shard 사용 가능
4) 비용 효율
고사양 서버 1개 << 저사양 서버 여러대
단점
1) 복잡
데이터 분배, 라우팅 로직 추가 -> 설계, 관리 복잡
2) 재분할 문제
shard 수가 변하면 data 이동, 재분배 필요
3) join, transaction
shard간 join, transaction 처리가 어려움
4) 불균형 데이터 == hot spot
shard key를 잘못 선택 -> 특정 shard에 data가 몰릴 수 있음
사용 사례
1) 대규모 사용자 서비스
사용자 id를 기준으로 hash 기반 shard
2) 지리적
지역별로 db를 나눔
3) 로그 데이터 저장
대량의 로그 데이터를 효율적으로 저장, 분석
시간 범위를 기준으로 shard
4) IoT
대규모 센서 데이터를 분선 처리
센서 id를 shard key로 사용
MySQL 샤딩:
MySQL에서는 직접 샤딩 설계, 샤딩 프레임워크(ProxySQL, Vitess) 사용
MongoDB 샤딩:
MongoDB는 기본적으로 샤딩을 지원하며, 데이터를 자동으로 분산 저장.
Cassandra:
분산 데이터베이스로, 샤딩 없이도 데이터를 자동 분산 저장.
Amazon DynamoDB:
AWS의 NoSQL 데이터베이스로, 기본적으로 해시 기반 샤딩을 사용.
데이터베이스에서 파티셔닝(Partitioning)을 적용하는 이유를 설명하고, 수평/수직 파티셔닝의 차이점을 설명해주세요.
Partitioning?
하나의 db table을 작은 단위의 물리적 partition으로 나누어 저장.
테이블 전체를 처리하는 대신, 특정 기준에 따라 나눠진 데이터만 처리 가능.
1) 성능 향상
쿼리 실행시 전체 테이블을 스캔하지 않음
관련된 partition만 스캔해서 data 조회 속도 빠름
2) 관리 용이
각 partition을 독립적으로 관리 가능 -> data 삭제/백업/복구 작업 쉬움
ex) 오래된 data를 특정 partition만 삭제 가능
3) 확장성
테이블 크기 제한에 도달하기 전에 data가 증가하면 새로운 partition 추가
4) 병렬 처리
여러 partition에서 작업을 처리 가능, 대규모 처리에서 성능 향상
5) 가용성
특정 partition이 장애나도 다른 partition 사용 가능
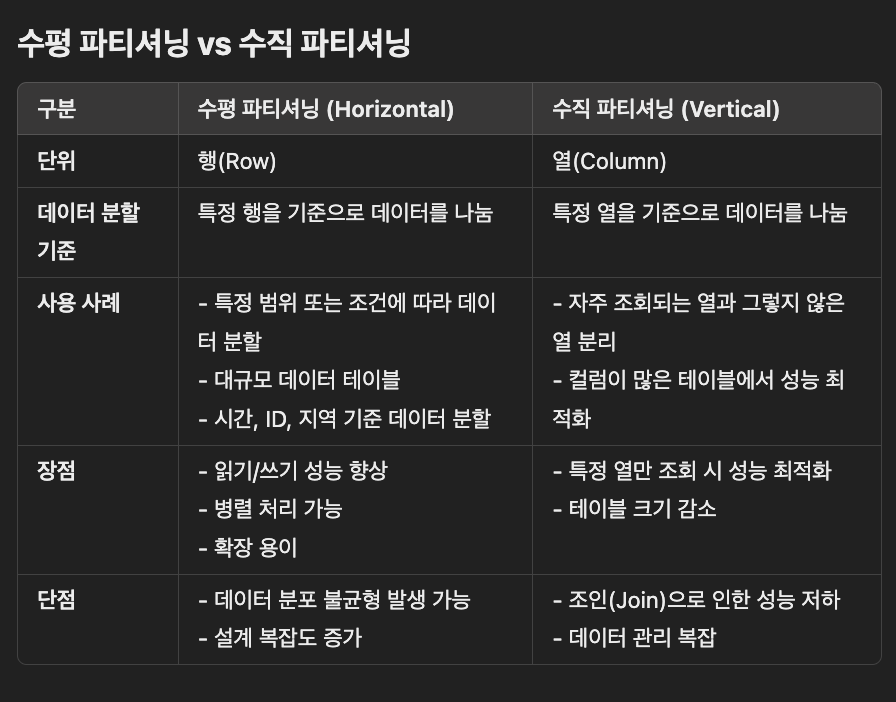
종류
Horizontal Partitioning
data를 row로 나눔
범위, 해시, 키를 기준으로 데이터를 나눔
ex) 사용자 데이터 테이블을 나이(age) 기준으로 나누기
나이 0~20세 → 파티션 1 나이 21~40세 → 파티션 2 나이 41세 이상 → 파티션 3.
CREATE TABLE users (
user_id INT,
name VARCHAR(100),
age INT
) PARTITION BY RANGE (age) (
PARTITION p1 VALUES LESS THAN (21), -- 0~20세
PARTITION p2 VALUES LESS THAN (41), -- 21~40세
PARTITION p3 VALUES LESS THAN MAXVALUE -- 41세 이상
);장점
특정 범위의 데이터만 조회할 때 성능 향상. 데이터 양이 많아질수록 파티션을 추가해 확장 가능.
단점
특정 범위에 데이터가 집중되면 성능이 저하될 수 있음. 파티션 키를 신중히 설계해야 함.
Vertical Partitioning
data를 column으로 나눔
특정 열만 자주 조회하는 경우, 해당 열을 별도로 분리
ex) 사용자 테이블의 기본 정보와 상세 정보를 분리
-- 기본 정보 테이블
CREATE TABLE users_basic (
user_id INT PRIMARY KEY,
name VARCHAR(100)
);
-- 상세 정보 테이블
CREATE TABLE users_details (
user_id INT PRIMARY KEY,
address VARCHAR(255),
phone_number VARCHAR(20),
FOREIGN KEY (user_id) REFERENCES users_basic(user_id)
);장점
특정 열만 필요로 하는 쿼리에서 성능 향상. 넓은 테이블(컬럼이 많은 테이블)을 분리해 메모리 사용량 최적화.
단점
두 테이블을 조인해야 하는 경우 성능 저하 가능. 데이터 관리가 복잡해질 수 있음.
사례
1) 대규모 로그 데이터
날짜 기준으로 로그 데이터 partitioning
2) 사용자 데이터
사용자 기본 정보, 민감한 정보를 수직 partitioning으로 보안 강화
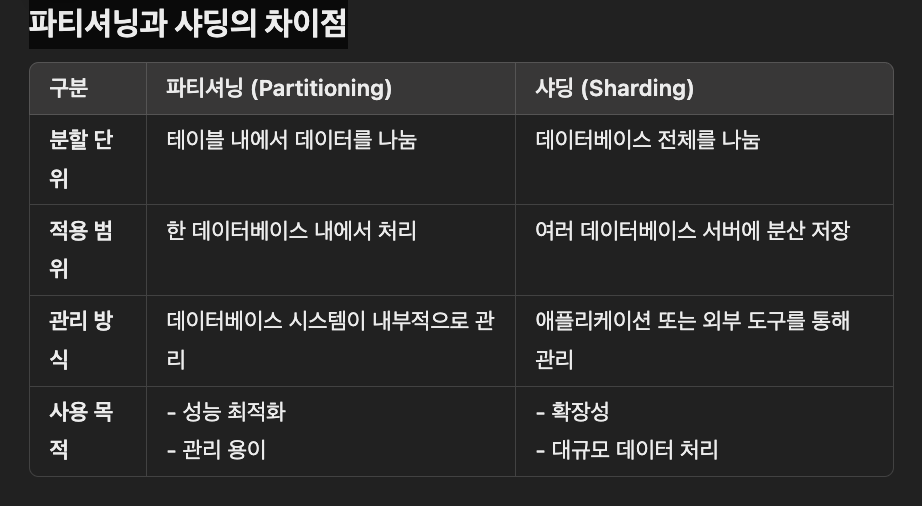
파티셔닝과 샤딩의 차이점
'학습 기록 (Learning Logs) > CS Study' 카테고리의 다른 글
| JPA-mapping (0) | 2024.12.12 |
|---|---|
| JPA-default (0) | 2024.12.12 |
| C, C++, C# 차이 (0) | 2024.12.07 |
| 운영체제 (0) | 2024.12.02 |
| 네트워크 (0) | 2024.11.24 |

