Item35~Item36 제이크
Item37~Item38 인호
Item39~Item40 진성
Item41~Item42 가을
Item43~Item44 민이/워니
Item45~Item46 워니/민이
43. 람다보다는 메서드 참조를 사용하라
핵심 정리
- 메서드 참조는 람다의 간단명료한 대안이 될 수 있다.
- 메서드 참조 쪽이 짧고 명확하다면 메서드 참조를 쓰고, 그렇지 않을 때만 람다를 사용하도록 한다.
메서드 참조: http://www.tcpschool.com/java/java_lambda_reference
코딩교육 티씨피스쿨
4차산업혁명, 코딩교육, 소프트웨어교육, 코딩기초, SW코딩, 기초코딩부터 자바 파이썬 등
tcpschool.com
위의 링크를 보면
코드 길이: 메서드 참조 < 람다
람다
map.merge(key, 1, (count, incr)->count+incr);
메서드 참조
map.merge(key, 1, Integer::sum);
단순히 합을 리턴하는 람다식이다. 각 변수의 이름은 크게 중요하지 않은데도 의미를 표현하느라 코드 공간을 꽤 많이 차지한다. Integer wrapper class는 위의 람다와 똑같은 sum 메서드를 제공한다
코드의 해석:

Wrapper 클래스: http://tcpschool.com/java/java_api_wrapper
코딩교육 티씨피스쿨
4차산업혁명, 코딩교육, 소프트웨어교육, 코딩기초, SW코딩, 기초코딩부터 자바 파이썬 등
tcpschool.com
Item 61. 박싱된 기본 타입보다는 기본 타입을 사용하라 | Carrey`s 기술블로그
서론 자바의 데이터 타입은 크게 두 가지로 나눌 수 있다. 기본 타입 (Primitive type) vs 참조 타입 (Reference Type) 으로 구분 할 수 있다. 기본 타입 (Primitive Type) int long short double char boolean 참조 타입 (Ref
jaehun2841.github.io
그러나 마냥 메서드 참조가 정답이 아닌 이유
- 그러나 람다의 매개변수 자체가 코드 이해에 도움이 되는 경우도 있다.
- 메서드 참조는 코드를 간결하게 해주지만 코드의 의미까지 간결하게 하는 부작용도 있다.
- 메서드 참조가 더 길 때도 있다.
메서드와 람다가 같은 클래스에 있을 때는 람다가 메서드 참조보다 간결하다.
//메서드 참조
service.execute(GoshThisClassNameIsHumongouse::action);
//람다식
service.execute(()->action());메서드 참조 쪽은 더 짧지도, 더 명확하지도 않다. 따라서 람다 쪽이 낫다.
메서드 참조의 유형
- 메서드 참조의 유형은 다섯 가지이다.
- 정적 메서드를 가리키는 메서드 참조하는 유형
- 수신 객체(receiving object; 참조 대상 인스턴스)를 특정하는 한정적(bound) 인스턴스 메서드 참조.
- 한정적 참조는 근본적으로 정적 참조와 비슷하다. 함수 객체가 받는 인수와 참조되는 메서드가 받는 인수가 똑같다.
- 수신 객체를 특정하지 않는 비한정적(unbound) 인스턴스 메서드 참조.
- 비한정적 참조에서는 함수 객체를 적용하는 시점에 수신 객체를 알려준다.
- 이를 위해 수신 객체 전달용 매개변수가 매개변수 목록의 첫 번째로 추가되며, 그 뒤로는 참조되는 메서드 선언에 정의된 매개변수들이 뒤따른다.
- 비한정적 참조는 주로 스트림 파이프라인에서의 매핑과 필터 함수에 쓰인다.
- 클래스 생성자를 가리키는 메서드 참조. 생성자 참조는 팩터리 객체로 사용된다.
- 배열 생성자를 가리키는 메서드 참조.
| 메서드 참조 유형 | 예시 | 같은 기능의 람다 |
| 정적 | Integer::parseInt | str -> Integer.parseInt(str) |
| 한정적(인스턴스) | Instant.now::isAfter | Instant then = Instant.now(); t -> then.isAfter(t) |
| 비한정적(인스턴스) | String::toLowerCase | str -> str.toLowerCase() |
| 클래스 생성자 | TreeMap<K, V>::new | () -> new TreeMap<K, V>() |
| 배열 생성자 | int[]::new | len -> new int[len] |
제네릭 함수 타입(generic function type)
interface G1 {
<E extends Exception> Object m() throws E;
}
interface G2 {
<F extends Exception> String m() throws Exception;
}
interface G extends G1, G2 {
}- 람다로는 불가능하지만 메서드 참조로는 가능한 유일한 예가 제네릭 함수 타입 구현이다.
- 함수형 인터페이스의 추상 메서드가 제네릭일 수 있듯이 함수 타입도 제네릭일 수 있다.
- 위 코드에서 함수형 인터페이스 G를 함수 타입으로 표현하면 <F extends Exception> () -> String throws F 와 같다.
- 함수형 인터페이스를 위한 제네릭 함수 타입은 메서드 참조 표현식으로는 구현할 수 있지만, 람다식으로는 불가능하다. 제네릭은 람다식이라는 문법이 존재하지 않기 때문이다.
람다와 메서드 참조 중 더 간결한 것을 찾고,
만약 메서드 참조 코드가 코드 자체로 의미를 띄지 못할거면 코드가 좀 길어지더라도
람다의 매개변수 이름 등으로 의미를 명확하게 하는 것을 고려해보자
44. 표준 함수형 인터페이스를 사용하라
핵심 정리
- 자바 8부터 람다를 지원한다. 입력값과 반환값에 함수형 인터페이스 타입을 활용하도록 한다.
- 보통은 java.util.function 패키지의 표준 함수형 인터페이스를 사용하는 것이 가장 좋은 선택이다.
- 흔치 않지만, 가끔은 직접 새로운 함수형 인터페이스를 만들어 쓰는 편이 나을 수도 있다.
익명 객체 사용 예제
RemoteControl 인터페이스
package Anonymous;
public interface RemoteControl {
void turnOn();
void turnOff();
}
Anonymous 클래스
: 인터페이스를 사용해 익명 객체를 정의한다
package Anonymous;
public class Anonymous2 {
//필드 초기값으로 대입
RemoteControl TV = new RemoteControl() {
@Override
public void turnOn() {
System.out.println("TV를 켭니다.");
}
@Override
public void turnOff() {
System.out.println("TV를 끕니다.");
}
};
void method1(){
//로컬 변수값으로 대입
RemoteControl audio = new RemoteControl() {
@Override
public void turnOn() {
System.out.println("오디오를 켭니다.");
}
@Override
public void turnOff() {
System.out.println("오디오를 끕니다.");
}
};
//로컬 변수 사용
audio.turnOn();
audio.turnOff();
}
void method2(RemoteControl remoteControl){
remoteControl.turnOn();
remoteControl.turnOff();
}
}main
package Anonymous;
public class Anoymous2Example {
public static void main(String[] args) {
Anonymous2 anonymous2 = new Anonymous2();
//익명 객체 필드 사용
anonymous2.TV.turnOn();
anonymous2.TV.turnOff();
//익명 객체 메소드 사용
anonymous2.method1();
//매개변수로 익명 객체 대입
anonymous2.method2(new RemoteControl() {
@Override
public void turnOn() {
System.out.println("자동차를 켭니다.");
}
@Override
public void turnOff() {
System.out.println("자동차를 끕니다.");
}
});
}
}실행 결과:
TV를 켭니다.
TV를 끕니다.
오디오를 켭니다.
오디오를 끕니다.
자동차를 켭니다.
자동차를 끕니다.
코드 복사: https://colinch4.github.io/2021-06-11/nested_2/
인터페이스 새로 작성함 -> 필요없다
@FunctionalInterface
public interface EldestEntryRemovalFunction<K, V> {
boolean remove(Map<K, V> map, Map.Entry<K, V> eldest);
}
- 위 인터페이스는 잘 동작하지만, 굳이 사용할 이유는 없다. 자바 표준 라이브러리에 이미 같은 모양의 인터페이스가 준비되어 있기 때문이다.
- java.util.function 패키지를 보면 다양한 용도의 표준 함수형 인터페이스가 담겨 있다.
- 필요한 용도에 맞는 게 있다면, 직접 구현하지 말고 표준 함수형 인터페이스를 활용하도록 한다.
- API가 다루는 개념의 수가 줄어들어 익히기 더 쉬워질 것이다.
- 표준 함수형 인터페이스들은 유용한 디폴트 메서드를 많이 제공하므로 다른 코드와의 상호운용성도 좋아질 것이다.
표준 함수형 인터페이스
java.util.function
- java.util.function 패키지에는 총 43개의 인터페이스가 있다. 아래는 기본 함수형 인터페이스들을 정리한 표다.
- 각각의 기본 인터페이스들은 기본 타입인 int, long, double용에 맞게 변형된 형태가 존재한다.
| 인터페이스함수 | 시그니처 | 예시 |
| UnaryOperator<T> | T apply(T t) | String::toLowerCase |
| BinaryOperator<T> | T apply(T t1, T t2) | BigInteger::add |
| Predicate<T> | boolean test(T t) | Collection::isEmpty |
| Function<T> | R apply(T t) | Arrays::asList |
| Supplier<T> | T get() | Instant::now |
| Consumer<T> | void accept(T t) | System.out::println |
- Operator 인터페이스는 인수가 1개인 UnaryOperator와
인수가 2개인 BinaryOperator로 나뉘며,
반환 값과 인수의 타입이 같은 함수를 뜻한다. - Predicate 인터페이스는 인수 하나를 받아 boolean을 반환하는 함수를 뜻한다.
- Function 인터페이스는 인수와 반환 타입이 다른 함수를 뜻한다.
- Supplier 인터페이스는 인수를 받지 않고 값을 반환(혹은 제공)하는 함수를 뜻한다.
- Consumer 인터페이스는 인수를 하나 받고 반환값은 없는, 인수를 소비하는 함수를 뜻한다
언제 표준 함수형 인터페이스를 사용해야 할까?
- 표준 함수형 인터페이스 대부분은 기본 타입만 지원한다.
기본 함수형 인터페이스에 박싱 타입을 넣지 마라. 기본 타입 사용해라.- 계산량이 많을 때는 성능이 처참히 느려질 수 있다.
직접 작성하는 것보다 표준 함수형 인터페이스를 사용하는 편이 낫다
코드를 직접 작성해야 할 때는 언제인가?
- 표준 인터페이스 중 필요한 용도에 맞는 게 없다면 직접 작성해야한다.
구조적으로 똑같은 표준 함수형 인터페이스가 있더라도 직접 작성해야만 할 때가 있다.
예시: Comparator<T> 인터페이스
구조적으로 ToIntBiFunction<T, U>와 동일하다.
독자적인 인터페이스로 존재해야 하는 이유가 몇 개 있다.
- 첫 번째. API에서 굉장히 자주 사용되는데, 이름이 그 용도를 아주 훌륭히 설명해준다.
- 두 번째. 구현하는 쪽에서 반드시 지켜야 할 규약을 담고 있다.
- 세 번째. 비교자들을 변환하고 조합해주는 유용한 디폴트 메서드들을 많이 담고 있다.
Comparator의 특성을 정리하면 아래와 같다. 이 중 하나 이상을 만족한다면 전용 함수형 인터페이스를 구현해야 하는 건 아닌지 고민해보도록 해야 한다.
- 자주 쓰이며, 이름 자체가 용도를 명확히 설명해준다.
- 반드시 따라야 하는 규약이 있다.
- 유용한 디폴트 메서드를 제공할 수 있다.
만약 전용 함수형 인터페이스를 작성하기로 했다면, '인터페이스'임을 명심해야 한다. 아주 주의해서 설계해야 한다.
@FunctionalInterface 애노테이션
@FunctionalInterface 애노테이션을 붙이면
두 개 이상의 추상 메소드가 선언되지 않도록 컴파일러가 검사해서 알려준다.
단, 디폴트 메소드 등은 추가로 있어도 괜찮다.(2개 이상 메소드가 있는 것처럼 보이지만 아님.)
람다식의 타겟 타입
람다식이 대입될 인터페이스를 람다식의 타겟 타입(target type)이라고 한다.
@FunctionalInterface 애노테이션을 사용하는 이유는 @Override를 사용하는 이유와 비슷하다.
프로그래머의 의도를 명시하는 것으로, 크게 세 가지 목적이 있다.
- 첫 번째. 해당 클래스의 코드나 설명 문서를 읽을 이에게 그 인터페이스가 람다용으로 설계된 것임을 알려준다.
- 두 번째. 해당 인터페이스가 추상 메서드를 오직 하나만 가지고 있어야 컴파일되게 해준다.
- 세 번째. 유지보수 과정에서 누군가 실수로 메서드를 추가하지 못하게 막아준다.
따라서, 직접 만든 함수형 인터페이스에는 항상 @FunctionalInterface 애너테이션을 사용하도록 한다.
함수형 인터페이스를 사용할 때의 주의점
- 서로 다른 함수형 인터페이스를 같은 위치의 인수로 받는 메서드들을 다중 정의해서는 안 된다.
- 클라이언트에게 불필요한 모호함만 줄 뿐이며, 이 때문에 실제로 문제가 일어나기도 한다.
45 스트림은 주의해서 사용해라
핵심 정리
- 스트림과 반복 방식은 각각에 알맞은 일이 있다.
- 수 많은 작업은 이 둘을 조합했을 때 가장 멋지게 해결된다.
- 만약 스트림과 반복 중 어느 쪽이 나은지 확신하기 어렵다면 둘 다 해보고 더 나은 쪽을 선택하도록 한다.
스트림 API
Java SE 8부터 추가된 스트림 API는 앞서 입력과 출력 수업에서 살펴본 스트림과는 전혀 다른 개념입니다.
자바에서는 많은 양의 데이터를 저장하기 위해서 배열이나 컬렉션을 사용합니다.
이렇게 저장된 데이터에 접근하기 위해서는 반복문이나 반복자(iterator)를 사용하여 매번 새로운 코드를 작성해야 합니다.
하지만 이렇게 작성된 코드는 길이가 너무 길고 가독성도 떨어지며, 코드의 재사용이 거의 불가능합니다.
즉, 데이터베이스의 쿼리와 같이 정형화된 처리 패턴을 가지지 못했기에 데이터마다 다른 방법으로 접근해야만 했습니다.
이러한 문제점을 극복하기 위해서 Java SE 8부터 스트림(stream) API를 도입합니다.
스트림 API는 데이터를 추상화하여 다루므로, 다양한 방식으로 저장된 데이터를 읽고 쓰기 위한 공통된 방법을 제공합니다.
따라서 스트림 API를 이용하면 배열이나 컬렉션뿐만 아니라 파일에 저장된 데이터도 모두 같은 방법으로 다룰 수 있게 됩니다.
스트림 API의 특징
스트림 API는 다음과 같은 특징을 가집니다.
1. 스트림은 외부 반복을 통해 작업하는 컬렉션과는 달리 내부 반복(internal iteration)을 통해 작업을 수행합니다.
2. 스트림은 재사용이 가능한 컬렉션과는 달리 단 한 번만 사용할 수 있습니다.
3. 스트림은 원본 데이터를 변경하지 않습니다.
4. 스트림의 연산은 필터-맵(filter-map) 기반의 API를 사용하여 지연(lazy) 연산을 통해 성능을 최적화합니다.
5. 스트림은 parallelStream() 메소드를 통한 손쉬운 병렬 처리를 지원합니다.
스트림 API의 동작 흐름
스트림 API는 다음과 같이 세 가지 단계에 걸쳐서 동작합니다.
1. 스트림의 생성
2. 스트림의 중개 연산 (스트림의 변환)
3. 스트림의 최종 연산 (스트림의 사용)
다음 그림은 자바 스트림 API가 동작하는 흐름을 나타냅니다.
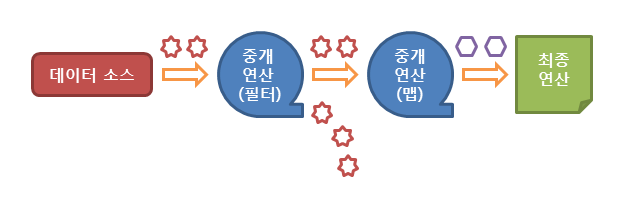
- 스트림 API가 제공하는 추상 개념 중 핵심은 두 가지다.
- 첫 번째. 스트림(stream)은 데이터 원소의 유한 혹은 무한 시퀀스(sequence)를 뜻한다.
- 두 번째. 스트림 파이프라인(stream pipeline)은 이 원소들로 수행하는 연산 단계를 표현하는 개념이다.
- 스트림 안의 데이터 원소들은 객체 참조나 기본 타입 값이다.
- 기본 타입 값으로는 int, long, double 이렇게 세 가지를 지원한다.
스트림 파이프라인
- 스트림 파이프라인은 소스 스트림에서 시작해 종단 연산(terminal operation)으로 끝난다.
- 스트림의 시작과 종단 연산의 사이에 하나 이상의 중간 연산(intermediate operation)이 있을 수 있다.
- 각 중간 연산은 스트림을 어떠한 방식으로 변환(transform)한다.
- 스트림 파이프라인은 지연 평가(lazy evaluation)된다.
- 평가는 종단 연산이 호출될 때 이뤄지며, 종단 연산에 쓰이지 않는 데이터 원소는 계산에 쓰이지 않는다.
- 종단 연산이 없는 스트림 파이프라인은 아무 일도 하지 않는 명령어인 no-op과 같으므로, 종단 연산은 필수다.
- 스트림 API는 메서드 연쇄를 지원하는 플루언트 API(fluent API)다.
- 파이프라인 하나를 구성하는 모든 호출을 연결하여 단 하나의 표현식으로 완성할 수 있으며, 파이프라인 여러 개를 연결해 표현식 하나로 만들 수도 있다.
- 기본적으로 스트림 파이프라인은 순차적으로 수행된다.
- 파이프라인을 병렬로 실행하려면 파이프라인을 구성하는 스트림 중 하나에서 parallel 메서드를 호출해주기만 하면 된다. 다만, 효과를 볼 수 있는 상황은 많지 않다.
사전 파일에서 단어를 읽어
사용자가 지정한 갯수< 원소 수가 많은 아나그램 그룹들을 출력한다.
아나그램: 철자를 구성하는 알파벳이 같고, 순서만 다른 단어
staple, aelpst, petals, ...
public class Anagrams {
public static void main(String[] args) {
Path dictionary = Paths.get(args[0]);
int minGroupSize = Integer.parseInt(args[1]);
Map<String, Set<String>> groups = new HashMap<>();
try (Scanner scanner = new Scanner(dictionary)) {
while (scanner.hasNext()) {
String word = scanner.next();
groups.computeIfAbsent(alphabetize(word), (unused) -> new TreeSet<>()).add(word);
}
}
for (Set<String> group : groups.values()) {
if (group.size() >= minGroupSize) {
System.out.println(group.size() + ": " + group);
}
}
}
private static String alphabetize(String word) {
char[] a = word.toCharArray();
Arrays.sort(a);
return new String(a);
}
}- 자바 8에서 추가된 computeIfAbsent 메서드가 사용되었다.
- 이 메서드는 맵 안에 키가 있는지 찾은 다음, 있으면 단순히 그 키에 매핑된 값을 반환한다.
- 만약 키가 없으면 건네진 함수 객체를 키에 적용하여 값을 계산하고, 그 키와 값을 매핑한 뒤 계산된 값을 반환한다.
groups.computeIfAbsent(alphabetize(word), (unused) -> new TreeSet<>()).add(word);각 키에 다수의 값을 매칭하는 쉽게 맵을 구현할 수 있다.
스트림을 과하게 사용했다. - 따라 하지 말 것!
public class Anagrams {
public static void main(String[] args) throws IOException {
Path dictionary = Paths.get(args[0]);
int minGroupSize = Integer.parseInt(args[1]);
// 스트림을 과하게 사용했다. - 따라 하지 말 것!
try (Stream<String> words = Files.lines(dictionary)) {
words.collect(groupingBy(word -> word.chars().sorted()
.collect(StringBuilder::new, (sb, c) -> sb.append((char) c), StringBuilder::append).toString()))
.values().stream()
.filter(group -> group.size() >= minGroupSize)
.map(group -> group.size() + ": " + group)
.forEach(System.out::println);
}
}
private static String alphabetize(String word) {
char[] a = word.toCharArray();
Arrays.sort(a);
return new String(a);
}
}- 스트림을 과용하면 프로그램이 읽거나 유지보수하기 어려워진다.
스트림을 적절히 사용하면 깔끔하고 명료해진다.
public class Anagrams {
public static void main(String[] args) throws IOException {
Path dictionary = Paths.get(args[0]);
int minGroupSize = Integer.parseInt(args[1]);
// 스트림을 적절히 사용하면 깔끔하고 명료해진다.
try (Stream<String> words = Files.lines(dictionary)) {
words.collect(groupingBy(word -> alphabetize(word)))
.values().stream()
.filter(group -> group.size() >= minGroupSize)
.forEach(g -> System.out.println(g.size() + ": " + g));
} catch (IOException e) {
e.printStackTrace();
}
}
private static String alphabetize(String word) {
char[] a = word.toCharArray();
Arrays.sort(a);
return new String(a);
}
}- 사전 파일을 열고
- 파일의 모든 라인으로 구성된 스트림을 얻는다
- 스트림 변수의 이름을 words로 지어, 스트림 안의 각 원소가 단어임을 명확히 함
- 이 스트림의 파이프라인에는 중간 연산이 없다.
- 종단 연산에서 모든 단어를 수집해 맵으로 모은다.
- values()가 반환한 값으로부터 새로운 Stream을 연다.
- 최소그룹 사이즈보다 적은것을 필터링한다.
- foEach로 살아남은 list를 출력한다.
- 람다 매개변수의 이름은 주의해서 정해야 한다.
- 람다에서는 타입 이름을 자주 생략하므로 매개변수 이름을 잘 지어야 스트림 파이프라인의 가독성이 유지된다.
- 도우미 메서드를 적절히 활용하는 일의 중요성은 일반 반복 코드에서보다 스트림 파이프라인에서 훨씬 크다.
파이프라인에서는 타입 정보가 명시되지 않거나 임시 변수를 자주 사용하기 때문이다.
- 자바는 기본 타입인 char용 스트림을 지원하지 않는다.
- char은 int 값을 갖기 때문이고, 그 덕에 int 스트림을 반환하면 헷갈릴 수 있다. 올바르게 동작하게 하려면 명시적으로 형변환을 해줘야 한다.
- 따라서 char 값들을 처리할 때는 스트림을 삼가는 편이 낫다.
- 예제: "hello world".chars().forEach(System.out::print); //8845484548415185654
- "hello world".chars().forEach( x -> System.out:print( (char) x) );
- 스트림이 언제나 가독성과 유지보수 측면으로 뛰어난 것은 아니다.
- 스트림과 반복문을 적절히 조합하는 게 최선이다.
- 따라서 기존 코드는 스트림을 사용하도록 리팩터링하되, 새 코드가 더 나아 보일 때만 반영하도록 한다.
반복 코드 vs 스트림 파이프라인
- 스트림 파이프라인은 되풀이되는 계산을 함수 객체(주로 람다나 메서드 참조)로 표현한다.
- 반복 코드에서는 코드 블록을 사용해 표현한다.
함수 객체로는 할 수 없지만 코드 블록으로는 할 수 있는 일
- 코드 블록에서는 범위 안의 지역변수를 읽고 수정할 수 있다.
- 람다에서는 final이거나 사실상 final인 변수만 읽을 수 있고, 지역변수를 수정하는 건 불가능하다.
- 코드 블록에서는 return 문을 사용해 메서드에서 빠져나가거나,
break나 continue 문으로 블록 바깥의 반복문을 종료하거나 반복을 한 번 건너뛸 수 있다. - 또한, 메서드 선언에 명시된 검사 예외를 던질 수 있다.
- 람다로는 이 중 어떤 것도 할 수 없다.
계산 로직에서는 스트림을 사용하기 별로임.
스트림이 안성맞춤인 일
- 원소들의 시퀀스를 일관되게 변환한다.
- 원소들의 시퀀스를 필터링한다.
- 원소들의 시퀀스를 하나의 연산을 사용해 결합한다(더하기, 연결하기, 최솟값 구하기 등).
- 원소들의 시퀀스를 컬렉션에 모은다(아마도 공통된 속성을 기준으로 묶어가며).
- 원소들의 시퀀스에서 특정 조건을 만족하는 원소를 찾는다.
스트림으로 처리하기 어려운 일
- 한 데이터가 파이프라인의 여러 단계(stage)를 통과할 때 이 데이터의 각 단계에서의 값들에 동시에 접근하는 것은 처리하기 어렵다.
- 스트림 파이프라인은 일단 한 값을 다른 값에 매핑하고 나면 원래의 값은 잃는 구조이기 때문이다.
스트림과 반복 중 어느 쪽을 써야 할까?
데카르트 곱 계산을 반복 방식으로 구현
public class Item45 {
private static List<Card> newDeck() {
List<Card> result = new ArrayList<>();
for (Suit suit : Suit.values()) {
for (Rank rank : Rank.values()) {
result.add(new Card(suit, rank));
}
}
return result;
}
}데카르트 곱 계산을 스트림 방식으로 구현
import java.util.stream.Stream;
public class Item45 {
private static List<Card> newDeck() {
return Stream.of(Suit.values())
.flatMap(suit -> Stream.of(Rank.values())
.map(rank -> new Card(suit, rank)))
.collect(toList());
}
}- 중간 연산으로 사용한 flatMap은 스트림의 원소 각각을 하나의 스트림으로 매핑한 다음 그 스트림들을 다시 하나의 스트림으로 합친다.
- 이러한 작업을 평탄화(flattening)라고도 한다.
46 스트림에서 부작용 없는 함수를 사용하라
핵심 정리
- 스트림 파이프라인 프로그래밍의 핵심은 부작용 없는 함수 객체에 있다.
- 스트림뿐 아니라 스트림 관련 객체에 건네지는 모든 함수 객체가 부작용이 없어야 한다.
- 종단 연산 중 forEach는 스트림이 수행한 계산 결과를 보고할 때만 이용해야 한다. 계산 자체에는 이용하지 않도록 한다.
- 스트림을 올바로 사용하려면 수집기를 잘 알아야 하며, 가장 중요한 수집기 팩터리는 toList, toSet, toMap, groupingBy, joining이다.
스트림
스트림은 함수형 프로그래밍에 기초한 패러다임이다.
스트림 패러다임
- 스트림 패러다임의 핵심은 계산을 일련의 변환(transformation)으로 재구성하는 부분이다.
- 이때 각 변환 단계는 가능한 한 이전 단계의 결과를 받아 처리하는 순수 함수여야 한다.
- 순수 함수란 오직 입력만이 결과에 영향을 주는 함수를 말한다.
- 다른 가변 상태를 참조하지 않고, 함수 스스로도 다른 상태를 변경하지 않는다.
- 이렇게 하려면 스트림 연산에 건네는 함수 객체는 모두 부작용(side effect)이 없어야 한다.
스트림 패러다임을 이해하지 못한 채 API만 사용했다 - 따라 하지 말 것!
public class Item46 {
public static void main(String[] args) {
Map<String, Long> freq = new HashMap<>();
try (Stream<String> words = new Scanner("file").tokens()) {
words.forEach(word -> freq.merge(word.toLowerCase(), 1L, Long::sum));
}
}
}- 이건 스트림 코드가 아니다
- 스트림 코드 인 척 하는스트림다.
- 위 코드의 모든 작업은 종단 연산인 forEach에서 일어나는데, 이때 외부 상태(빈도표)를 수정하는 람다를 실행하면서 문제가 생긴다.
words.forEach( word -> freq.merge(word.toLowerCase(), 1L, Long::sum) );
스트림을 제대로 활용해 빈도표를 초기화한다.
public class Item46 {
public static void main(String[] args) {
Map<String, Long> freq = new HashMap<>();
try (Stream<String> words = new Scanner("file").tokens()) {
words.collect(groupingBy(String::toLowerCase, counting()));
}
}
}
words.collect( groupingBy(String::toLowerCase, counting() ) );
- for-each 반복문은 forEach 종단 연산과 비슷하게 생겼다.
- 하지만 forEach 연산은 종단 연산 중 기능이 가장 적고 대놓고 반복적이라서 병렬화할 수도 없다.
- forEach 연산은 스트림 계산 결과를 보고할 때만 사용하고, 계산하는 데는 쓰지 말도록 한다.
Collectors, 수집기
- java.util.stream.Collectors 클래스는 스트림의 원소들을 객체 하나에 취합하는 여러 메서드를 제공해준다.
- 이를 이용하면 스트림의 원소를 손쉽게 컬렉션으로 모을 수 있으며, toList(), toSet(), toCollection(collectionFactory) 등이 있다.
- Collectors의 멤버를 정적 임포트하여 쓰면 스트림 파이프라인의 가독성을 향상시킬 수 있다.
수집기에는 아래의 것들을 비롯해 여러 가지 종류가 있다.
- toMap, groupingBy, partitioningBy 등의 메서드가 있다.
- counting, filtering, mapping, flatMapping, collectiongAndThen 등의 메서드가 있다.
- minBy, maxBy는 인수로 받은 비교자를 이용해 스트림에서 값이 가장 작은 혹은 가장 큰 원소를 찾아 반환한다.
- Stream 인터페이스의 min과 max 메서드를 살짝 일반화한 것이자, java.util.function.BinaryOperator의 minBy와 maxBy 메서드가 반환하는 이진 연산자의 수집기
버전이다.
- Stream 인터페이스의 min과 max 메서드를 살짝 일반화한 것이자, java.util.function.BinaryOperator의 minBy와 maxBy 메서드가 반환하는 이진 연산자의 수집기
- joining 메서드는 문자열 등의 CharSequence 인스턴스의 스트림에만 적용할 수 있다.
- 매개변수가 없는 joining은 단순히 원소들을 연결(concatenate)하는 수집기를 반환한다.
- 인수 하나짜리 joining은 CharSequence 타입의 구분문자(delimiter)를 매개변수로 받으며, 연결 부위에 이 구분문자를 삽입하여 연결한 결과를 만들어준다.
- 인수 3개짜리 joining은 구분문자에 더해 접두문자(prefix)와 접미문자(suffix)도 받는다.
'학습 기록 (Learning Logs) > 이펙티브 자바' 카테고리의 다른 글
| [item 65] 리프렉션보다는 인터페이스를 사용하라 (0) | 2022.01.30 |
|---|---|
| Item51~Item52 (0) | 2022.01.23 |
| Item29~30 (0) | 2022.01.09 |
| [item 21~22] (0) | 2022.01.01 |
| [item 1] 생성자 대신 정적 팩터리 메서드를 고려하라 (0) | 2021.12.29 |

