Array
1) 배열 생성시 크기 결정됨 ->, 크기 고정, 불특정 다수 객체 저장 문제
2) 객체 삭제시 해당 인덱스가 비게 된다. 듬성듬성 옥수수
| 인터페이스 분류 | 특징 | 구현 클래스 | |
| Collection | List 인덱스-값 |
순서를 유지, 저장 중복 저장 가능 |
ArrayList Vector LinkedList |
| Set 키 주머니 |
순서 없음, 저장 키 = 유니크 |
HashSet TreeSet |
|
| Map 키-값 |
키-값 으로 구성됨 키 = 유니크 |
HashMap TreeMap HashTable Properties |
|
출처: 이것이 자바다 - 신용권
List 컬렉션
1) 저장 순서 유지 됨. ex) list.add(2) list.add(1) list.add(3) // [2,1,3]
2) 인덱스-값
인덱스로 추가add, 수정set, 삭제remove 가능
3) 객체를 저장하지 않고 객체의 번지를 참조한다
4) 배열과 다르게: 중간에 데이터 삭제시 인덱스 위치가 당겨진다, 데이터 추가 시 인덱스 위치가 밀려난다
| 기능 | 리턴 | 메소드 | 설명 |
| 객체 추가 | boolean | add(객체) | 맨끝에 객체 추가 |
| void | add(index, 객체) | index에 객체 추가 |
|
| E | set(index, 객체) | index에 객체 바꿈 | |
| 객체 검색 | boolean | contains(객체) | 객체가 저장되어 있는가? boolean |
| E | get(index) | 인덱스에 저장된 값 리턴 | |
| boolean | isEmpty() | 컬렉션이 비어졌는가? boolean | |
| int | size() | 전체 객체 수 리턴 | |
| 객체 삭제 | void | clear() | 모든 객체 삭제 |
| E | remove(index) | index에 저장된 객체 삭제 | |
| boolean | remove(객체) | 객체 삭제 |
ArrayList
List<String> list = new ArrayList<String>();
1) 인덱스 - 값
2) 용량이 고정된 배열과 달리, 자동으로 용량이 늘어난다
3) 값 저장 시: Object 타입으로 변환되어 저장됨
4) 찾아올때는 타입 변환 해야함.
5) 똑같은 타입만 저장 가능
6) 배열과 다르게: 중간에 데이터 삭제시 인덱스 위치가 당겨진다, 데이터 추가 시 인덱스 위치가 밀려난다
Vector
List list<E> = new Vector<E>();
1) ArrayList 동일한 내부 구조
2) ArrayList 달리, 동기화된 메소드 구성 : 하나의 쓰레드
LinkedList
List list = new LinkedList<String>();
1) 특정 인덱스의 객체를 추가, 삭제하면 링크만 변경된다 => 듬성듬성 옥수수 안됨
2) 빈번한 객체 추가, 삭제 환경에서는 ArrayList보다 빠르다
| ArrayList | LinkedList |
| 인덱스를 가진다. | 인덱스 없다. 노드의 연결(링크)로 연결됨 |
| 중간에 데이터를 추가, 삭제 하면 전체 인덱스가 변한다. |
중간에 데이터를 추가, 삭제 해도 전체 인덱스가 변하지 않는다. |
| 인덱스로 값을 빨리 찾는다 | 처음부터 끝까지.. 순차 탐색을 사용. 탐색 속도가 떨어진다. |
| 탐색, 정렬 --> 배열 사용해! | 데이터 추가/삭제 많은 경우 --> 연결 리스트 사용해!! |
Queue
package com.company;
public class Message {
public String command;
public String to;
public Message(String command, String to){//생성자??
this.command = command;
this.to = to;
}
}
package com.company;
import java.util.LinkedList;
import java.util.Queue;
public class QueueExample {
public static void main(String[] args) {
Queue<Message> mq = new LinkedList<Message>();
mq.offer(new Message("인사","워니"));
mq.offer(new Message("노래","사람1"));
mq.offer(new Message("놀기","사람2"));
mq.offer(new Message("공부","사람3"));
while(!mq.isEmpty()){
Message ms = mq.poll();//꺼냄
switch (ms.command){
case "인사":
System.out.println(ms.to+"는 사람들에게 인사합니다");
break;
case "노래":
System.out.println(ms.to+"는 락 노래를 부릅니다");
break;
case "놀기":
System.out.println(ms.to+"는 먹고 놀고 먹고 놀고");
break;
case "공부":
System.out.println(ms.to+"은 자바 공부합니다");
break;
}
}
}
}
queue에 객체를 담을 수 있구나..
while(!mq.isEmpty())로 반복하는구나..
이 두가지를 사용하면 짧게 만들 수 있겠다.

import java.util.Arrays;
import java.util.Iterator;
import java.util.LinkedList;
public class linkedList {
public static void main(String[] args) {
//선언 : LinkedList 초기 크기를 미리 생성할 수 없다.
LinkedList list = new LinkedList(); // 타입 미설정 객체로 선언된다 : 비추천
LinkedList<queue> members = new LinkedList<queue>();//타입 설정, queue 객체만 가능
LinkedList<Integer> num = new LinkedList<Integer>();//타입설정, int만 가능
LinkedList<Integer> num2 = new LinkedList<>(); //오른쪽 타입 파라미터 생략
LinkedList<Integer> list2 = new LinkedList<Integer>(Arrays.asList(1, 2, 3)); //생성 시 값 넣음
//값 넣기
list2.addFirst(0);//맨 앞에 데이터 추가
list2.addLast(4);//맨 뒤에 데이터 추가
list2.add(7);//01234
list2.add(0, 5);// index 4에
//값 넣기2
queue q = new queue(0, "wonny");
members.add(q);
members.add(q);
members.add(new queue(1, "hoy"));
members.add(new queue(2, "hoy"));
members.add(new queue(3, "hoy"));
members.add(new queue(4, "hoy"));
members.add(new queue(5, "hoy"));
//값 출력 : for
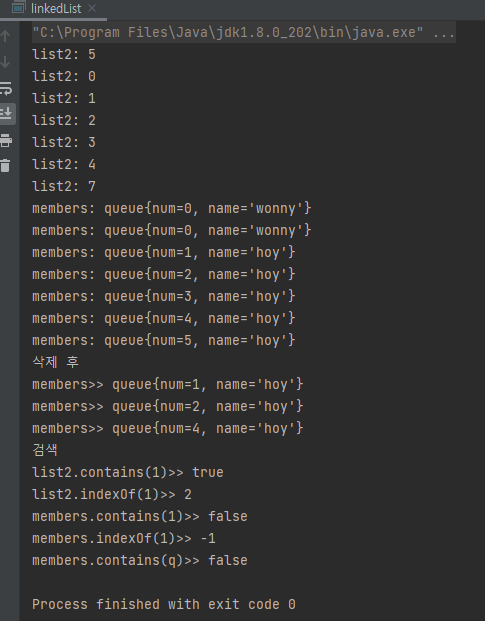
for (Integer i : list2) {
System.out.println("list2: " + i);
}
//값 출력 : while
Iterator<queue> iter = members.iterator();//iterator 선언
while (iter.hasNext()) {
System.out.println("members: " + iter.next().toString());
}//while end
//값 삭제
members.removeFirst();//맨 앞 제거
members.removeLast();//맨 뒤 제거
members.remove(3);
members.remove();
System.out.println("삭제 후");
//값 출력 : for - get
for(int i=0; i<members.size(); i++){
System.out.println("members>> "+members.get(i));//array보다 느리다
}//for end
System.out.println("검색");
//검색
System.out.println("list2.contains(1)>> "+ list2.contains(1));
System.out.println("list2.indexOf(1)>> "+ list2.indexOf(1));
System.out.println("members.contains(1)>> "+ members.contains(1));//false
System.out.println("members.indexOf(1)>> "+ members.indexOf(1));//-1
System.out.println("members.contains(q)>> "+ members.contains(q));//false
}
}
Set 컬렉션 (구슬 주머니)
1) 인덱스가 없다. 저장 순서 유지 안됨. ex) 주머니에서 구슬 뺼때 어떤게 나올지 모름
2) 키=값 즉, 1개 (구슬)
3) 키: 유니크 , 중복 불가능
| 기능 | 리턴 | 메소드 | 설명 | ||
| 객체 추가 | boolean | add(객체) | 객체 저장 | ||
| 객체 검색 | boolean | contains(객체) | 객체 찾기 | ||
| boolean | isEmpty() | 컬렉션이 비어있는가 | |||
| Iterator | iterator() | 저장된 객체를 하나씩 가져오는 반복자 | |||
| hasNext() | boolean | 다음 있어? 가져올 객체가 있으면 true 반환 |
|||
| next() | E | 컬렉션에서 객체 하나 가져옴 | |||
| remove() | void | 컬렉션에서 객체 제거 | |||
| int | size() | 전체 객체 수 리턴 | |||
| 객체 삭제 | void | clear() | 전체 삭제 | ||
| boolean | remove(객체) | 객체 삭제 | |||
HashSet
hash의 의미부터 잡고 가야한다.
hash: 암호화 시킨다. (input은 다르지만 암호화된 output이 같을 수 있다.)
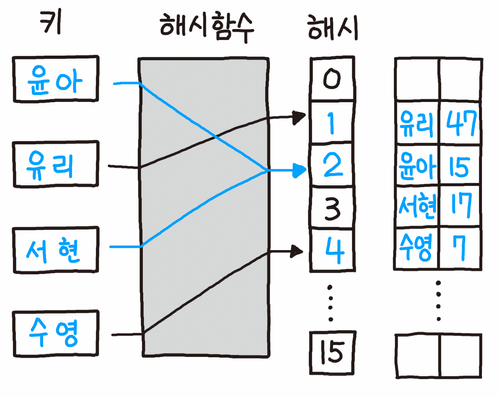
윤아 키를 해시함수hashCode()를 통과하면 2해시코드이 된다. 2해시코드에 윤아 객체를 넣는다.
유리 키를 해시함수hashCode()를 통과하면 1해시코드이 된다. 1해시코드에 유리 객체를 넣는다.
서현 키를 해시함수hashCode()를 통과하면 2해시코드가 된다. 그런데 윤아랑 해시코드가 같다.
서현과 윤아는 객체가 다르다.eqauls() 그럴 경우 아래 3해시코드에 서현 객체를 넣는다.
Set<String> set = new HashSet<String>();
1) 인덱스 없다. 순서 없다.
2) 키=값. 유니크하다
3) hashCode(), eqauls() : 검증을 두번해서 Hashset에 값을 저장한다. 두 함수는 오버라이딩 가능.
예제보기: https://coding-factory.tistory.com/554?category=758267
TreeSet
TreeSet <Integer> set = new TreeSet<Integer>();
1) 인덱스 없다.
2) (이진탐색트리) 순서 있다
2-1) 자동 정렬: set.add(2); set.add(1); set.add(3); // [1,2,3]
3) 최대, 최소 함수 사용 가능
set.first(); 최소값 출력
set.last(); 최대값 출력
set.higher(2); 2보다 큰 데이터 출력
set.lower(1); 1보다 작은 데이터 출력
예제보기: https://coding-factory.tistory.com/555
4) 정렬
4-1) 내림 차순
NavigableSet<> 내림차순 = treeSet.descendingSet();
4-2) 올림 차순
NavigableSet<> 내림차순 = treeSet.ascendingSet();
Map 컬렉션
1) Entry 객체(키 객체-값 객체)
키: 유니크
| 기능 | 리턴 | 메소드 | 설명 |
| 객체 추가 | V | put(키, 값) | 새로 추가 : null 리턴 키 존재: 값 대체, 이전 값 리턴 |
| 객체 검색 | boolean | containsKey(키 객체) | 키 있나 |
| boolean | containsVaulue(값 객체) | 값 있나 | |
| Set<> |
entrySet() |
Map.entry객체(키-값) 리턴 | |
| Set<Map.Entry<String, Integer>> Eset=map.entrySet();//다 가져와 Iterator<Map.Entry<String,Integer>> iter=Eset.iterator();// 하나씩 while(iter.hasNext() ){ Map.Entry<S, I> entryO = iter.next(); // entry객체 String key = entryO.getKey(); //키 Integer value = entryO.getVaulue();//값 } |
|||
| V | get(키 객체) | 키의 값 리턴 | |
| boolean | isEmpty() | 컬렉션이 비어있는가 | |
| Set<K> |
keySet() |
모든 키를 Set 객체로 리턴 | |
| Set<String> keySet = map.keySet();// 다 가져와 Iterator<String> iter = keySet.iterator();//하나씩 while(iter.hasNext() ){ String key = iter.next(); // 키 Integer value = map.get(key); // 값 } |
|||
| int | size() | 저장된 총 Entry의 수 | |
| Collection<V> | values() | 모든 값 Collection으로 리턴 | |
| 객체 삭제 | void | clear() | 모든 Map.Entry(키-값) 삭제 |
| V | remove(키 객체) | 키와 일치하는 Map.Entry(키-값) 삭제 후 값 리턴 |
| getOrDefault(키,디폴트값) | 찾는 키가 존재한다면 찾는 키의 값을 반환하고 없다면 기본 값을 반환 | for(String key : alphabet) hm.put(key, hm.getOrDefault(key, 0) + 1); |
HashMap
Map<String, Integer> map = new HashMap<String, Integer>();
hash: 암호화 시킨다. (input은 다르지만 암호화된 output이 같을 수 있다.)
1) hashCode(), eqauls() : 검증을 두번해서 Hashset에 값을 저장한다. 두 함수는 오버라이딩 가능.
2) 키: 유니크
HashTable
1) HashMap과 같음
2) 동기화된 메소드로 구성됨, 하나의 스레드로 실행됨
TreeMap
TreeMap<Integer, String> treeMap = new TreeMap<Integer, String>();
1) Map.Entry(키-값) 를 저장한다
2) 이진트리, 자동 정렬
3) 최대, 최소 함수 사용 가능
set.firstEntry(); 최소값 출력
set.lastEntry(); 최대값 출력
set.higherEntry(2); 키2보다 큰 데이터 출력
set.lowerEntry(1); 키1보다 작은 데이터 출력
4) 정렬
4-1) 내림 차순
NavigableMap<> 내림차순 = treeMap.descendingKeyMap();
4-2) 올림 차순
NavigableMap<> 내림차순 = treeMap.ascendingMap();
'학습 기록 (Learning Logs) > 알고리즘 개념 정리' 카테고리의 다른 글
| [java] Math 클래스, String (0) | 2021.09.27 |
|---|---|
| [java] stream (0) | 2021.09.27 |
| [java] Comparable, Comparator (0) | 2021.09.27 |
| [java] 형 변환 (0) | 2021.09.25 |
| [java] 입력 Scanner BufferedReader 비교 (0) | 2021.09.25 |


