https://youtu.be/R873BlNVUB4?si=8YxFgKlkCBqYlL9U

data가 많아지면 문제가 생긴다

kafka에서 사용하는 partion을 사용하는 이유



Queue, Sub/Pub 차이

삭제하지 않는다, broadcast 하려면 pub/sub
pub/sub 원리

kafka: How can we do both Queue and Pub/Sub?
-> Consumer Group

2개의 partion에서 consuming을 할 수 있다.

you don't really care which partition this is coming from right.

This is a rule.
Each partition have to be consumed by one and Only one consumer.

you feel like a queue.

분산 시스템


복사

소비자 주키퍼 알고리즘에 달려있다


예시 코드

make zookeeper : 2181


another terminal, kafka:9092


npm init -y
create topic.js




create producer.js
just changed from kafka.admin() to kafka.producer();

Add just send messages function using by producer.send()


partition 적용





you can see increasing baseOffset number, check partition.

create consumer.js
kafka.consumer({});


I wanna that consumer will keep polling for messages in a long polling.
so delete consumer.disconnect();
Add consumer.subscribe({})



3개의 서버를 띄우겠습니다
prepare for running producer.js

run consumer.js

producer.js : send message : test
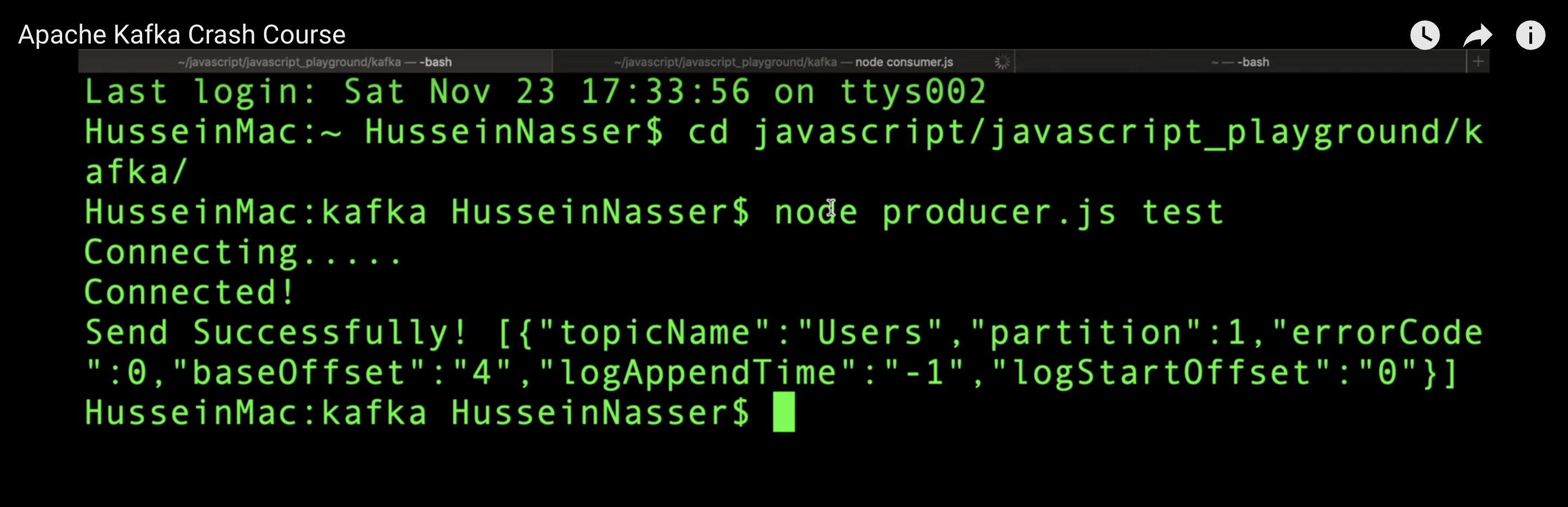
consumer.js : consuming message : test

producer.js : send message : test, ali, Ali

consumer.js : consuming message : test, ali, Ali

Run second consumer2.js

producer.js : partition 0 : Adam

consumer1.js : partition 0 : Adam

producer.js : partition 1 : Zain

consumer2.js : partition 1 : Zain

append only commit log, this is a the heart of kafka.
all partitions, all topics, everything message use you right it goes to a log.
and that log is append-only.
the end, you can append extreamely fast to end.
you are not seeking to the middle. and you are inserting data between two blocks of data.
unlike relational databases and B trees.
you are not manipulating the actual desk space and fragment of stuff.

so fast

Long polling

Event driven

zookeeper help scaling


샤딩에서 강하다


'학습 기록 (Learning Logs) > CS Study' 카테고리의 다른 글
| Tree (0) | 2025.02.03 |
|---|---|
| WAL(Write-Ahead Logging) (0) | 2025.02.03 |
| nestjs + kafka (0) | 2025.01.20 |
| 리눅스 서버 관리 기초 (0) | 2025.01.13 |
| sort (0) | 2025.01.09 |



