
공통 질문
출처: https://www.youtube.com/watch?v=sqVByJ5tbNA
1. RDB의 단점
- 스키마(컬럼) 추가
기존에 데이터를 다시 써야한다
db 부담이 된다
- 정규화
장점:
- data 중복을 최소화한다
단점
- 데이터를 조회할때 join을 많이 해야한다.
- read 응답 시간이 늦어진다.
- join을 여러개 하면 cpu를 많이 사용한다
- Scale up
요청이 많아지면, 성능 좋은 컴퓨터로 바꾼다
- replication 사용
한대의 쓰기, 여러개의 읽기 서버 다수를 만든다.
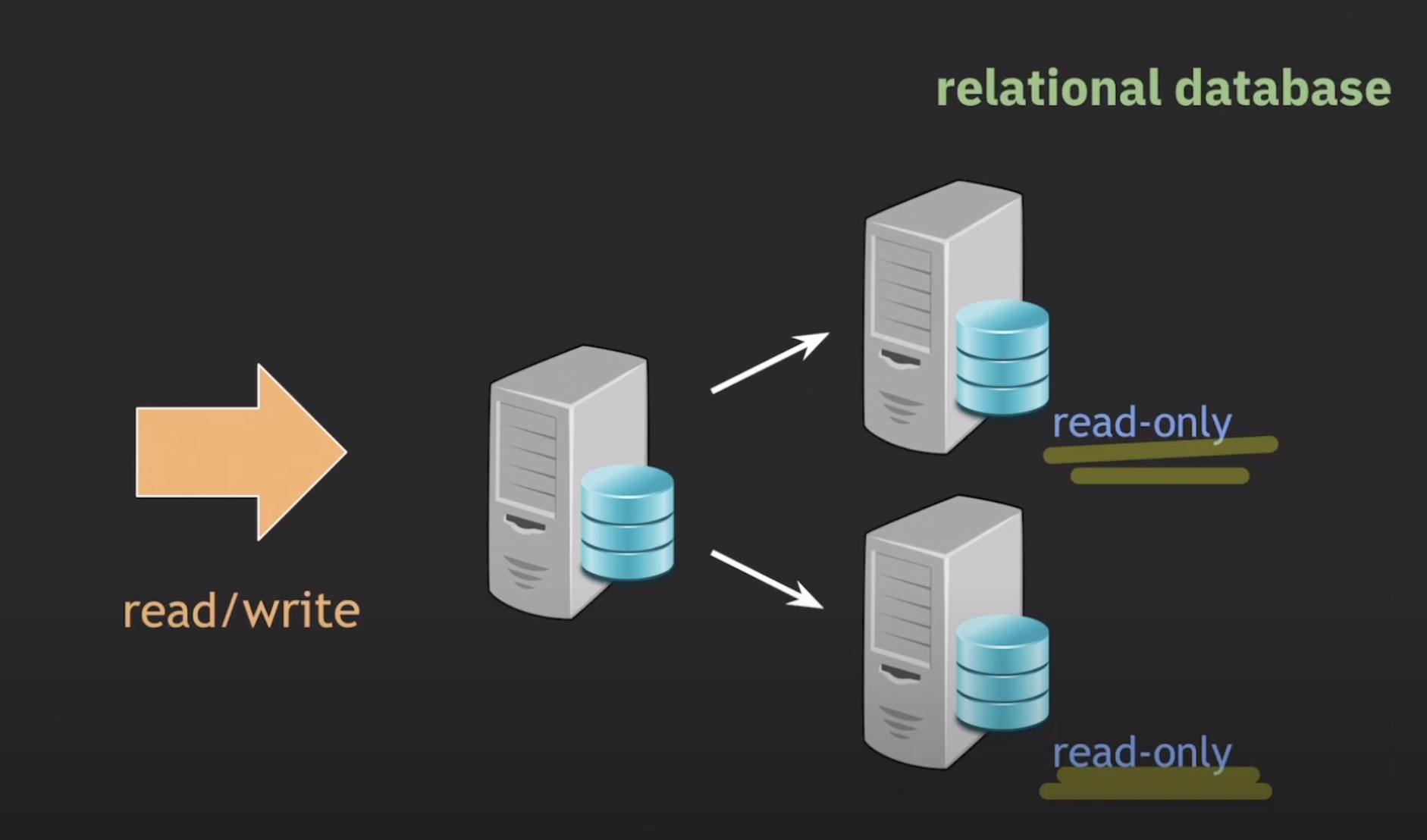
- Scale out 유연하지 않다
database server를 추가해서 해결하는 방법
write 트래픽이 많다면, 성능이 낮아진다
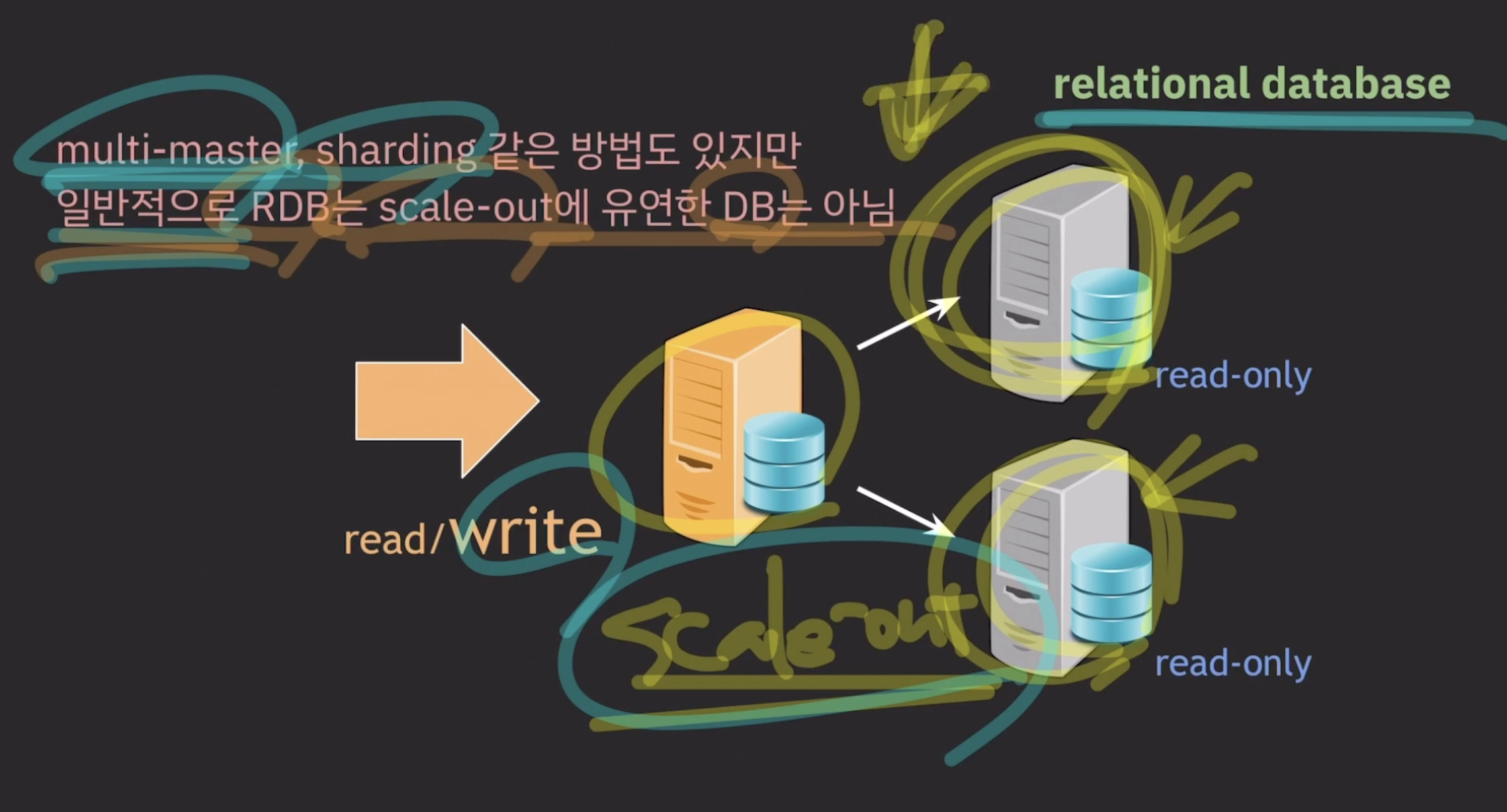
- 어떻게 해결할까?
1. 샤딩
샤딩을 하면 데이터를 옮겨야한다.
서비스가 운영중이면 데이터를 옮기는건 쉬운 작업이 아니다
2. 마스터
- ACID를 보장해서 performance가 낮아진다

- acid를 유지하려다 보니 처리량이 줄어든다
2. NoSql 등장 배경
- 기존의 RDB에서 커버하기 힘든 규모의 트래픽이 생성됨
- SNS 등장
- 인터넷 등장
- 전 지구인을 대상으로 함
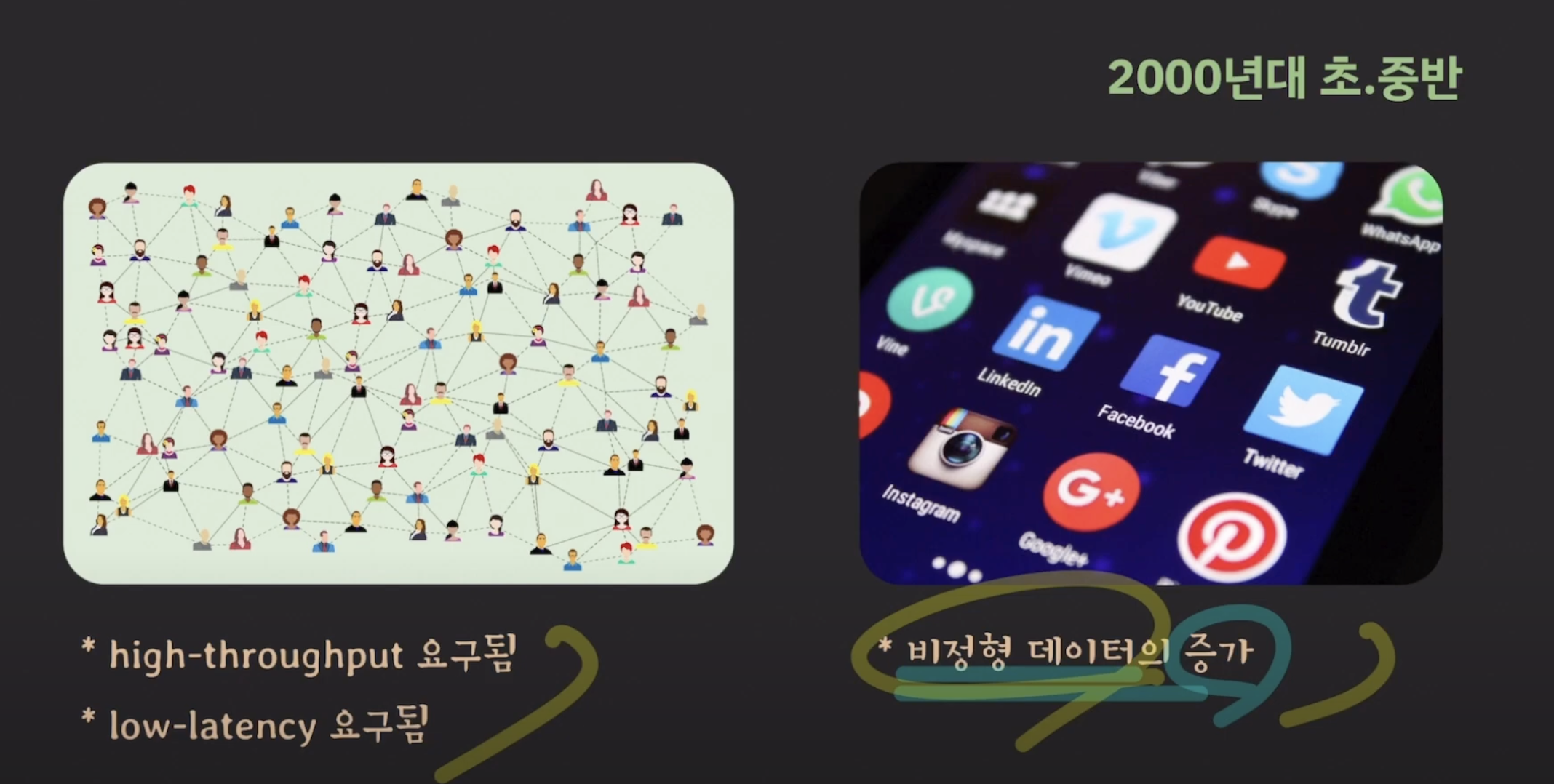
새로운 요구 사항
- 높은 처리량이 필요해짐
- 응답 시간이 빨라지는 것이 필요해짐
- 비정형 data 증가(다양한 사람이 다양한 데이터를 원함, 예상할 수 없는 데이터가 필요해짐)
NoSQL
각각 마다 특징이 다르다

MongoDB로 보는 NoSQL 특징
- 유연한 스키마
넣고 싶은대로 data를 넣는다
- 중복 허용
따라서 join을 회피한다
- scale out 최적화
- ACID 일부 포기하고 빠른 처리, 높은 처리량 제공
금융회사 처럼 일관성(consistency)가 중요한 환경에서는 사용하기 조심스러움
- 유연한 스키마
단점:
- application에서 schema 관리 필요
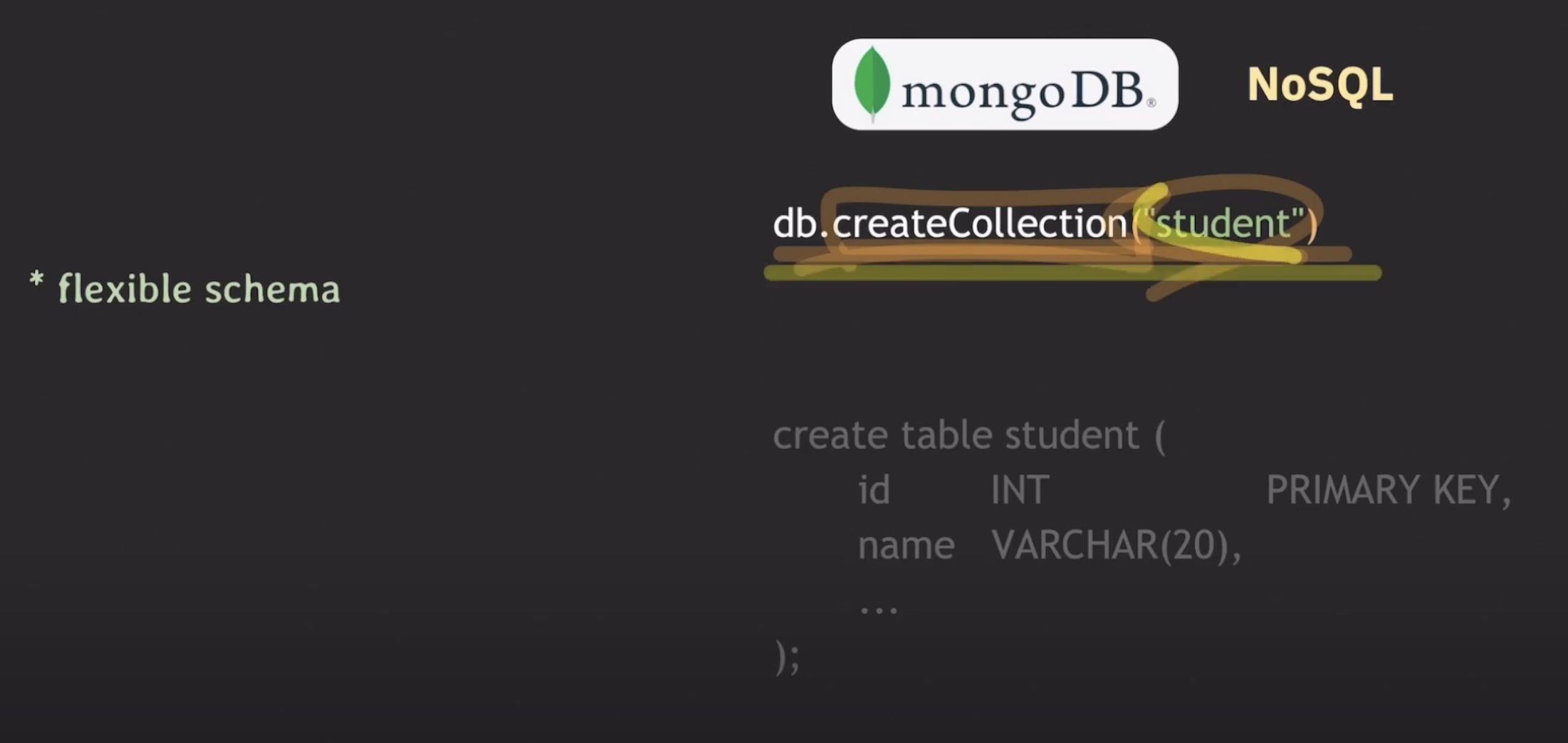
생성
 |
 |
조회: document
 |
전체 데이터 조회 |
- 중복 허용
user_name, phone_number 중복 됨
단점:
- application 레벨에서 중복된 data들이 모두 최신 data를 유지하도록 관리 해야 함

- scale out 최적화
rdbms 보다 쉽게 scale out을 상대적으로 쉽게 할 수 있다.
서버 여러 대를 묶어서 cluster로 구성한다
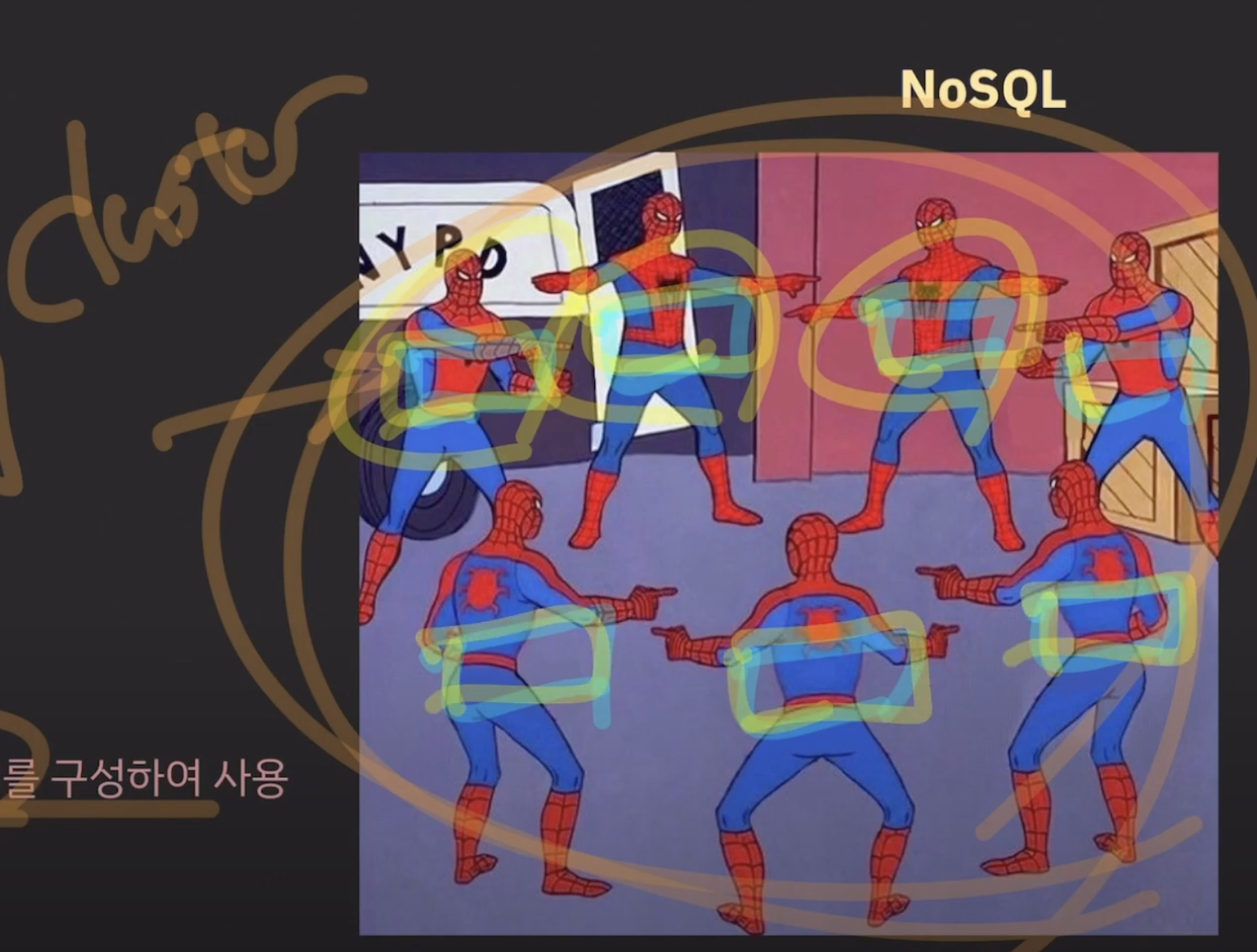
스파이더맨 == 각각의 서버
서버는 서로 다른 data를 가지고 있음
join은 안씀, 중복이 가능함
그래서 서버(스파이더맨)이 증가해도, 이미 중복된 데이터를 가지고 있기 때문에, 요청을 분산해서 read, write 가능함
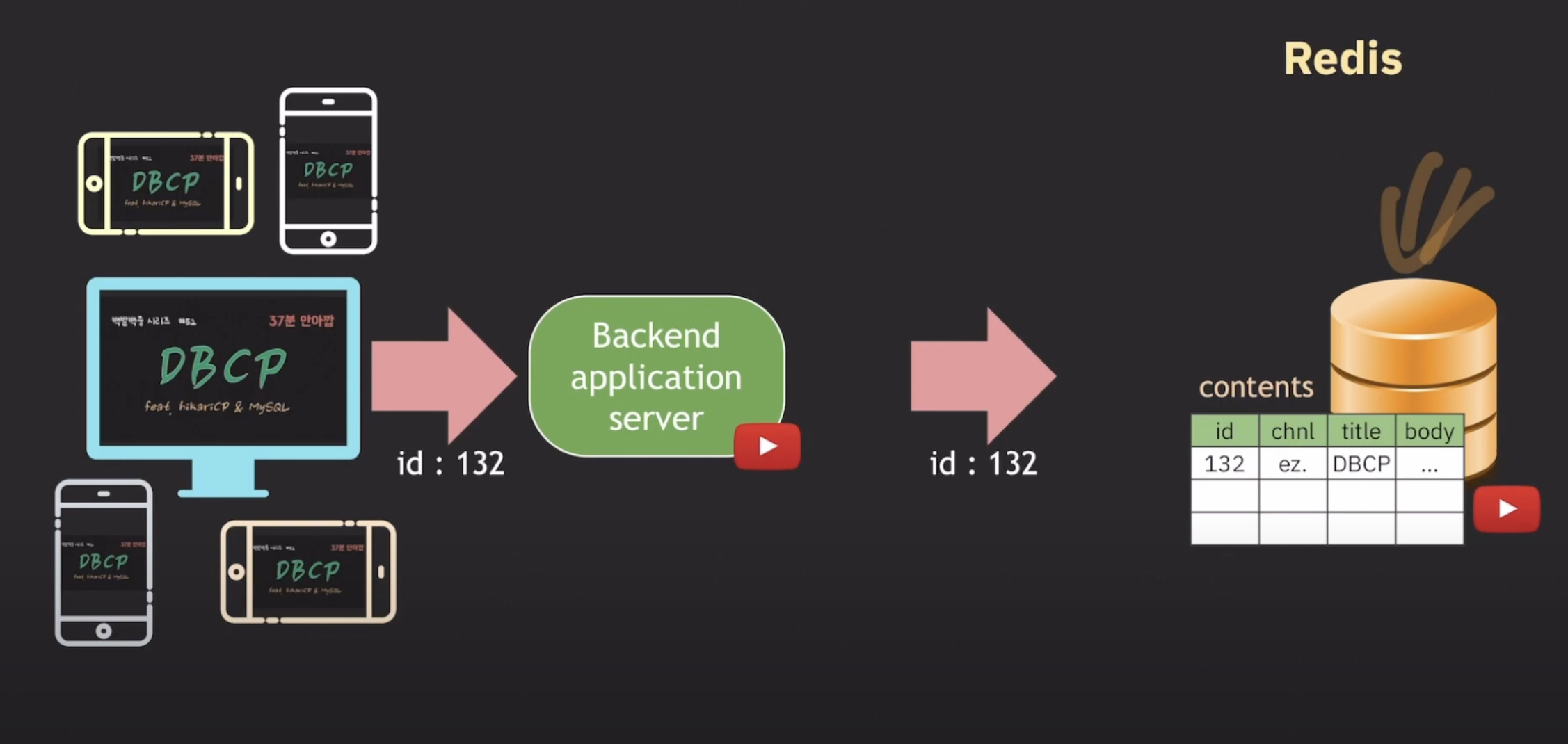
redis ( in-memory database, cache)
메모리를 사용하는
key-value 형태로 data를 저장한다
메모리는 가격이 비싸서, db로 사용하기는 부담스럽다
따라서 보통 회사에서는 메모리, cache로 주로 사용된다.

다양한 data type을 제공한다
hash로 샤딩 클러스터를 제공한다
고가용성을 제공한다(replication, failover 제공한다)

요청자가 많아지면 db 부하가 높아지면서 performence가 낮아진다
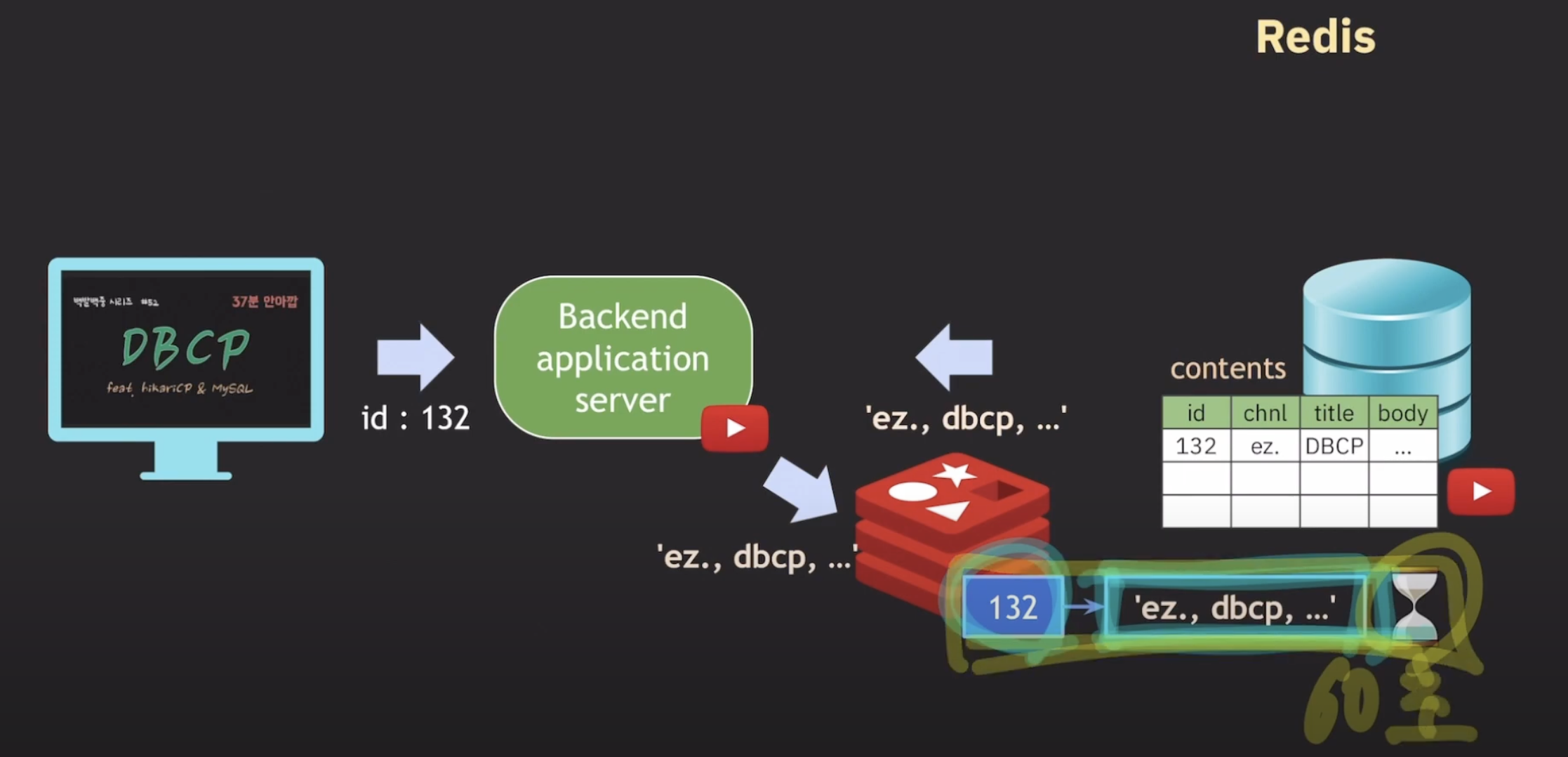
해결 방법
- cache 사용
서버 앞단에 redis를 cache로 둔다
redis는 memory라서 ssd, hdd보다 훨씬 빠르다
'학습 기록 (Learning Logs) > CS Study' 카테고리의 다른 글
| Real-time Notification Service Using WebSocket (0) | 2025.02.20 |
|---|---|
| concurrenct problem (0) | 2025.02.13 |
| mvcc (0) | 2025.02.06 |
| lock (0) | 2025.02.06 |
| database (0) | 2025.02.06 |



