- 인공신경망의 역사
- 퍼셉트론 등장
- 역전파의 고안
- Deep 출현
- 딥러닝의 개요
- 인공신경망 개념
- 딥러닝 개념
- 딥려닝 학습
- 딥러닝의 유형
- DFN
- RNN
- LSTM
- CNN
- 워드 임베딩
- GAN
01 퍼셉트론은 신호를 입력으로 받아 하나의 신호를 출력하며, 현재 신경망의 기원이 되는 알고리즘입니다.
02 역전파란 오차(예측값과 실제값의 차이)를 역방향으로(출력층 - 은닉층 입력층) 전 파시키면서 가중치를 계산하는 방법입니다.
03 제프리 힌튼은 가중치의 초기값을 제대로 설정하면 깊이가 깊은 신경망도 학습이 가능하 다는 것을 증명하였습니다. 즉, 신경망을 학습시키기 전에 계층(데 입력층, 은닉층) 단 위의 학습을 거쳐 더 나은 초기값을 얻는 방식인 사전훈련 방식을 제안한 것입니다.
04 인공신경망이란 인간의 신경망을 흉내 낸 머신러닝 기법입니다.
05 딥러닝이란 여러 층(특히 은닉층이 여러 개)을 가진 인공신경망을 사용하여 머신러닝 학 습을 수행하는 것으로, 심층학습이라고도 합니다.
06 가중합이란 입력값과 가중치를 곱한 뒤 편향(Bias)을 더한 값입니다.
07 활성화 함수는 인공신경망에서 각 뉴런이 입력을 받아 출력을 계산하는 함수입니다.
08 활성화 함수에는 시그모이드 함수, 하이퍼볼릭 탄젠트 함수, 렐루 함수, 리키렐루 함수, 소프트맥스 함수가 있습니다.
09 순전파란 입력층에서 출력층 방향으로 연산이 진행되면서 최종 출력값이 도출되는 과정 을 뜻합니다.
10 손실함수는 예측값과 실제값의 차이를 구하는 함수입니다.
11 옵티마이저는 딥러닝에서 학습 속도를 빠르고 안정적이게 만드는 것입니다.
12 심층 순방향 신경망(DFN)은 딥러닝에서 가장 기본으로 사용하는 인공신경망입니다.
13 순환 신경망(RNN)은 시계열 데이터와 같이 시간적으로 연속성이 있는 데이터를 처리하 기 위해 고안된 인공신경망입니다.
14 LSTM은 순환 신경망과는 다르게 신경 내에 메모리를 두어 먼 과거의 데이터도 저장할 수 있도록 하였습니다.
15 합성곱 신경망(CNN)은 인간의 시각 처리 방식을 모방한 모델이며, 합성곱 신경망은 합 성곱층, 풀링층, 완전연결층으로 구성되어 있습니다.
• 합성곱층 : 이미지를 분류하는 데 필요한 특징 정보들을 추출하는 역할을 합니다.
• 풀링층 : 합성곱층의 출력 데이터(특성 맵)를 입력으로 받아서 출력 데이터인 활성화 맵의 크기를 줄이거나 특정 데이터를 강조하는 용도로 사용됩니다.
• 완전연결 : 합성곱층과 풀링층으로 추출한 특징을 분류하는 역할을 합니다.
16 워드 임베딩은 단어를 벡터로 표현하는 방법이며, 대표적으로 원-핫 인코딩, 워드투벡 터, TF-IDF, Fasttext가 있습니다.
• 원-핫 인코딩 : N개의 단어를 각각 N차원의 벡터로 표현하는 방식입니다.
• 워드투벡터 : 비슷한 컨텍스트에 등장하는 단어들은 유사한 의미를 지닌다는 이론에 기반하여 단어를 벡터로 표현하는 기법입니다.
• TF-IDF : 단어마다 가중치를 부여하여 단어를 벡터로 변환하는 방법입니다.
• Fasttext : 부분 단어라는 개념을 도입하여 단어를 벡터로 변환하는 방식입니다.
17 적대적 생성 신경망(GAN)은 생성과 판별 두 개의 신경망 모델이 서로 경쟁하면서 더 나 은 결과를 만들어 내는 강화학습입니다.인공신경망의 역사

인공신경망 역사
- 1943년
- 워렌 맥컬록(Warren McCulloch)과 월터 피츠(Walter Pitts)가 제시한 논문에서 시작
- 인간의 뇌를 기계적으로 모델링한 최초의 시도
- 1949년
- 캐나다 의 심리학자 도널드 햄(Donald Hebb)
- 뉴런 사이의 연결 강도를 조정할 수 있는 학습 규칙을 발표
- 1957년
- 프랭크 로젠블라트(Frank Rosenblat)
- 퍼셉트론 (Perceptron) 신경망 모델을 발표
- 인간의 두뇌 움직임을 수학적으로 구성
- 뉴욕타임즈(The New York Times) -> 인공신경망에 대한 기대가 얼마나 컸는지 짐작

인공신경망(Artificial Neural Network, ANN)
- 인간의 뇌 구조에서 영감을 받은 모델
- 여러 개의 노드(뉴런)가 층을 이루고, 이들 사이에 연결 가중치가 존재함
- 입력층(Input Layer), 은닉층(Hidden Layer), 출력층(Output Layer)으로 구성됨
인공신경망은 수많은 '노드'들로 구성된다.
하나의 노드: 여러 함수로 이루어진 하나의 계산 단위, 단위 자체가 뉴런을 모방한다.
층: 각 노드를 용도별로 분리한 단위
밍: 각 노드가 얼마나 많은 노드와 신호(정보)를 주고 받는지 따질 수 있는 그 연결의 수
그래서 최종적으로 인공신경망이라고 하는 것이다.

현재의 인공지능은 인공신경망에 의해 이루어진다.
인공신경망이 지능이 있는 것으로 보이게 만드는 원리는: 수많은 코드(노드/계산 단위)가 각자의 계산을 수행한다는 과정에 있다.
인공지능에 어떠한 질문(신호)이 주어질 때 각 노드 별로 질문에 반응하며 다음 노드에 신호를 전달한다.
신호를 받는 개별 노드는 자신에게 주어진 가중치를 통해 편향(bias/기준치)으로 신호를 거르고 다시 산출하는데,
그렇게 걸러진 산출된 신호들의 총합이 바로 인공지능이 우리에게 전달하는 '대답'이 된다.
퍼셉트론(Percepron)
- 인공신경망의 가장 기본 단위
- 여러 입력값(x)에 각각 가중치(w)를 곱하고, 편향(b)을 더해 활성화 함수로 출력 결정
- 단일 퍼셉트론은 선형 분류만 가능 → XOR 문제 해결 불가
- 신호(x1, x2)를 입력
- 하나의 신호(y)를 출력하는 기계
- 신경 망의 기원이 되는 알고리즘
- 다수의 신호를 입력으로 받아 하나의 신호를 출력으로 내보냄

퍼셉트론(Percepron) 내부 과정
- 입력(x0, x1, x2...)에 가중치(w0, w1, w2...)를 곱하고
- 곱한 결과를 모두 더한 값이 --> 활성화 함수를 거쳐 출력
- 입력(input): AND 또는 OR 연산을 위한 입력 신호
- 가중치(Weight) : 입력 신호에 부여되는 중요도로, 가중치가 크다는 것은 그 입력이 출력을 결정하는 데 큰 역할을 한다는 의미
- 가중합(Weighted Sum) : 입력값과 가중치의 곱을 모두 합한 값
- 활성화 함수(Activation Function) : 어떠한 신호를 입력받아 이를 적절하게 처리하여 출력해 주는 함수, 가중합이 임계치(Threshold)를 넘어가면 1, 그렇지 않으면 0을 출력함
- 출력(Output): 최종 결과(분류)
퍼셉트론을 이용한 학습의 한계
AND와 OR 연산의 경우 퍼셉트론을 통한 선형 분리가 가능함
초기 퍼셉트론을 이용한 문제해결은 AND와 OR 같은 간단한 연산이었습니다.
그 당시 기계가 AND와 OR 연산을 스스로 풀 수 있으면 이를 조합해 어떤 문제든 풀어낼 수 있다고 생각했습니다.

- 1969년
- 마빈 민스키와 시모어 페퍼트
- 저서 「퍼셉트론(Perceptrons)」
- '현재의 퍼센트론으로는 XOR 연산이 절대 불가능하다'라는 가설을 수학적으로 증명함
퍼셉트론을 이용한 학습의 한계 -> 인공신경망 연구는 침체기
퍼셉트론을 여러 개 쌓아 올린 다층 퍼셉트론(MLP, Multilayer Perceptron)을 통해 XOR 연산에 대 한 문제는 해결될 수 있지만,
각각의 가중치(Weight)와 편향(Bias)을 학습시킬 방법이 없다'라는 결론
다층 퍼셉트론(MLP: Multi-layer Perceptron)
- 은닉층을 1개 이상 추가한 구조
- 비선형 활성화 함수(ReLU 등)를 통해 복잡한 문제 해결 가능
- 역전파 알고리즘(Backpropagation)을 통해 학습 가능
🎨 웹툰 이미지 생성 예시로 본 퍼셉트론
🎨 웹툰 이미지 생성 예시로 본 퍼셉트론
✔ 먼저 퍼셉트론을 아주 쉽게 요약하면:
여러 개의 입력값(x) → 중요도(가중치 w) 적용 → 합친 결과가 일정 기준(임계값)을 넘으면
→ 그림의 어떤 부분을 그릴지 결정
셉트론은 웹툰 생성 모델에서 "이 캐릭터의 눈/코/입을 어떻게 그릴지 결정하는 최소 단위"로 작동해요.
수많은 퍼셉트론이 함께 작동해서 전체 그림을 생성하게 됩니다!
🧠 예시: "캐릭터 얼굴 생성기" 만들기!
💡 목표
AI가 웹툰 캐릭터의 눈, 코, 입 위치와 특징을 정해서 얼굴을 자동으로 그림
🧩 퍼셉트론을 어떻게 사용하냐면?
🧾 입력 (x)
- 사용자가 주는 정보들:
- x1: 머리 스타일 (숏컷: 0, 긴머리: 1)
- x2: 눈 크기 (0.0 ~ 1.0)
- x3: 입 모양 (웃는 정도)
- x4: 감정 (슬픔, 행복 등)
⚖ 가중치 (w)
- 각 특징이 얼굴 모양에 얼마나 영향을 주는지
- w1: 머리 스타일이 눈 위치에 얼마나 영향을 줄까?
- w2: 감정이 입 크기에 얼마나 영향을 줄까?
➕ 가중합 계산 (∑ x × w)
눈 위치 결정 퍼셉트론:
output = w1×x1 + w2×x2 + w3×x3 + w4×x4
🔥 활성화 함수 통과
- 위 결과가 임계값보다 크면 → "눈을 크게 그려라!"
- 작으면 → "눈을 작게 그려라!"
→ 즉, 퍼셉트론은 "이 캐릭터는 눈을 크게 그리는 게 맞아?" 같은 질문에
0 또는 1로 판단해서 결과를 결정해주는 역할을 함
🤖 그런데 현실에서는?
퍼셉트론 하나만으로는 얼굴을 못 그려요!
하지만, 이 퍼셉트론을 수백 개~수천 개로 연결해서 만든 게 바로:
→ 신경망(Neural Network)
→ 그리고 그걸 더 확장한 게 웹툰 생성 모델에 쓰이는:
→ 합성곱 신경망(CNN), GAN(생성 모델)
역전파(Backpropagation)
이후 가중치와 편향을 학습하기 위한 방법으로 역전파(Backpropagation)가 고안되었습니다.
- 1974년
- 폴 워보스(Paul Werbos)
- 박사과정 논문에서 처음 제안
- 인공신경망에 대한 실망감이 만연해 그의 논문은 외면 받음
- 1986년
- 제프리 힌튼(Geoffrey Hinton)
- XOR 연산 문제뿐만 아니라 더 복잡한 문제도 해결할 수 있음이 증명
- 인공신경망은 다시 사람 들의 관심을 끌음

전방향(Feedforward) 학습을 통해 가중치와 편향을 수정하는 것이 아니라
전방향에 대한 학습 결과를 보고
뒤로 가면서 가중치와 편향을 조정하는 방법
- 신경망의 오차(예측값과 실제값의 차이)를 출력층에서부터 입력층으로 거꾸로 전파시켜
- 각 층(Layer)의 가중치와 편향을 업데이트
역전파 한계
신경망이 너무 깊으면, 오차(기울기)를 전달하는 과정에서 줄거나(소멸) 커져서(발산)
앞쪽 층이 제대로 학습되지 않는 문제가 생긴다!

- 신경망의 깊이가 깊어질수록 원하는 결과를 얻을 수 없음
- 신경 학습에 최적화된 하이퍼파라미터에 대한 이론적인 근거가 없음
신경망이 깊어질수록 학습력이 좋아져야 하는데 기대하는 결과가 나오지 않는 일이 지속적으로 발생
🧩 왜 이런 문제가 생길까?
- 역전파는 곱셈 연산을 반복하는 구조예요.
- 0.8 * 0.8 * 0.8 * ... → 점점 작아져서 소멸
- 1.5 * 1.5 * 1.5 * ... → 점점 커져서 발산
- 그래서 층이 많아질수록 이런 문제가 생기기 쉬움
기울기 소멸 문제(Vanishing Gradient)
역전파를 수행할 때 출력층에서 멀리 떨어진 층에서는 기울기가 급속히 작아짐
기울기 발산(Exploding Gradient)
역전파를 수행할 때 출력층에서 멀리 떨어진 층에서는 기울기가 너무 커짐
🎯 예시: “멀리 있는 친구에게 전달하기”
🎯 “멀리 있는 친구에게 전달하기”
🧑🏫 상황 예시
- 당신은 긴 줄의 사람들(= 신경망의 층)을 통해 종이쪽지(=오차/기울기) 를 친구에게 전달하려고 해요.
- 한 명씩 쪽지를 전달합니다.
그런데... 전달하는 과정에서 문제가 생겨요.
❌ 1. 기울기 소멸 (Vanishing Gradient)
전달하는 사람이 조금씩 줄여서 전달하는 경우
- 첫 번째 사람이 “100”이라고 쪽지를 넘김
- 두 번째 사람이 “조금만 줄여서 전달하자” 해서 “50”
- 세 번째 사람이 “25”
- 네 번째는 “12.5”
- 마지막 친구가 받을 때는 거의 0에 가까운 쪽지를 받게 됨
🧠 이게 바로 기울기 소멸이에요.
→ 출력층에서 멀어진 층(초기 층)은 학습할 정보가 거의 없음
→ 아무리 학습해도 잘 안 바뀌는 층이 생김
❌ 2. 기울기 발산 (Exploding Gradient)
전달하는 사람이 숫자를 과하게 키워서 전달하는 경우
- 첫 번째 사람이 “2”라고 쪽지를 넘김
- 두 번째 사람이 “4”
- 세 번째가 “8”
- 네 번째가 “16”… 마지막에는 “1024”
→ 너무 커져서 막판에는 종이 터지거나, 친구가 당황함
🧠 이게 바로 기울기 발산이에요.
→ 앞쪽 층에서 너무 큰 값을 받아 파라미터가 불안정하게 튐
→ 학습이 제대로 안 됨
✅ 해결 방법은?
| 문제 | 해결 방법 |
| 기울기 소멸 | ReLU 같은 활성화 함수 사용, Batch Normalization |
| 기울기 발산 | Gradient Clipping, 적절한 초기화 (He/Xavier 초기화 등) |
| 공통 해결 | Residual Network (ResNet)처럼 스킵 연결 사용 |
🤔 왜 MSE, MAE를 알아야 할까?
MSE와 MAE는 단순한 수식이 아니라, 모델의 성능을 평가하고 방향을 잡아주는 나침반

✅ 1. 모델이 얼마나 잘 예측했는지 평가하려면 필요함
- 모델이 어떤 값을 예측했는데, 그게 얼마나 실제와 가까운지 알아야 하잖아요?
- 그걸 판단하는 도구가 바로 오차(에러) 지표예요.
- 예:
- 예측: 98점
- 실제: 100점
→ 오차는 -2점, 혹은 2점인데...
수많은 예측을 종합적으로 평가하려면 평균적인 오차가 필요합니다.
✅ 2. 모델 선택이나 성능 비교에 사용됨
- 두 모델 중 어떤 게 더 좋은지 어떻게 비교할까요?
- MSE가 낮은 모델이 더 정교한 예측을 했다고 판단할 수 있어요.
- 예: 모델 A는 MSE 3.2 / 모델 B는 MSE 7.5 → 모델 A가 더 우수!
✅ 3. 실제 업무에 미치는 영향이 다르기 때문
- 예측이 조금 틀린 건 괜찮지만, 크게 틀리는 건 문제일 수 있어요.
- MSE는 큰 오차에 더 큰 패널티를 줘서, 치명적인 예측 실패를 막는 데 유리
- MAE는 모든 오차를 동일하게 취급해서, 전반적인 평균 오차가 중요한 경우에 유리
택배 도착시간 예측
- 큰 오차를 피하고 싶으면 MSE
- 전체 평균 오차만 중요하면 MAE
✅ 4. 모델 학습(=손실 함수)에 직접 사용됨
- 회귀 문제에서는 MSE나 MAE가 손실 함수(loss function) 로 직접 쓰여요.
- 딥러닝 모델을 학습시킬 때, 오차를 기반으로 가중치를 조정하는데
- 어떤 오차 계산을 쓰느냐에 따라 학습 방향과 결과가 달라짐
오차 계산
회귀모델에서 오차를 계산하는 방법으로는 MSE와 MAE가 많이 사용됩니다.
| MSE(Mean Squared Error) | MAE (Mean Absolute Error) |
| 예측값과 실제값의 차이인 오차들의 제곱에 대한 평균 | 예측값과 실제값의 차이인 오차들의 절댓값에 대한 평균 |
 |
 |
| 장점 : 직관적이고 단순함 | 장점 : 매우 직관적인 지표 |
단점 :
|
단점 : 스케일에 의존적 |
📌 회귀 모델이란?
📌 회귀 모델이란?
숫자를 예측하는 모델이에요!
입력을 주면, 그에 맞는 연속적인 수치 값을 예측해줘요.
회귀 모델 = 숫자를 예측하는 머신러닝/딥러닝 모델
집값, 기온, 조회수, 매출 등 숫자가 필요한 모든 문제에 사용돼요!
"웹툰 추천 시스템", "작가별 수익 예측" 같은 것도 회귀 문제
🎯 예를 들어 보자
예시 1: 집값 예측
- 입력 (X): 방 개수, 위치, 평수
- 출력 (Y): 집값 (숫자)
이럴 때 "집값"처럼 연속된 숫자를 예측하는 모델 = 회귀 모델
예시 2: 웹툰 조회수 예측
- 입력 (X): 장르, 업로드 요일, 작가 팔로워 수
- 출력 (Y): 예상 조회수 (숫자)
"웹툰의 조회수"도 숫자니까 → 회귀 문제!
🤔 분류 모델과 뭐가 달라?
| 구분 | 회귀 모델 | 분류 모델 |
| 예측값 | 숫자 값 | 카테고리 (예: 남자/여자, 고양이/개) |
| 예시 | 온도 예측, 가격 예측 | 성별 분류, 스팸 메일 여부 분류 |
| 사용 함수 | MSE, MAE 등 | Cross Entropy 등 |
📈 수학적으로 보면?
회귀 모델은 보통 이런 수식을 따릅니다:
y = w1*x1 + w2*x2 + ... + b
- x는 입력 (예: 평수, 작가 팔로워 수 등)
- w는 가중치 (중요도)
- b는 편향
- 이 수식 결과로 나온 y가 바로 예측값!
✅ 언제 회귀 모델을 써야 할까?
| 문제 형태 | 회귀 모델? |
| 예측 결과가 숫자인가요? | ✅ 회귀 모델 사용 |
| 예측 결과가 이름/카테고리인가요? | ❌ 분류 모델 사용 |
🧠 전역 최소점이 뭐냐면?
- 우리는 머신러닝에서 오차(손실, loss) 를 줄이는 게 목표예요.
- 수많은 파라미터(w, b 등)를 조절하면서 오차 함수(Loss Function)를 최소로 만드는 지점을 찾는 거예요.
- 이때, **오차가 가장 작아지는 지점이 바로 “전역 최소점”**입니다.
전역 최소점을 구한다는 건,
모델이 가장 정확하게 예측할 수 있는 상태를 찾아내는 거예요.

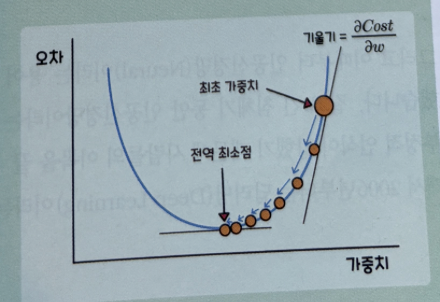

손실함수
- 지역 최소점(Local Minimum) : 함수 일부 구간의 최솟값
- 전역 최소점(Global Minimum) : 전체 구간에서의 최솟값
경사 하강법
오류가 작아지는 방향으로 가중치(W)값을 보정하기 위해 사용합니다.
가중치값을 보정하는 방법은 그래프와 같이 전역 최소점인 접선의 기울기가 0이 되는 지점,
즉 미분값이 0인 점을 찾는 것입니다.
최초 가중치에서부터 미분을 적용한 뒤
미분값이 계속 감소하는 방향으로(방향이 정해지지 않음) 순차적으로 가중치값을 업데이트합니다.
이후 업데이트가 끝나는 전역 최소점에서의 가중치값을 반환합니다.
🎯 왜 전역 최소점을 구하냐면?
🎯 왜 전역 최소점을 구하냐면?
✅ 1. 예측이 가장 정확해지는 지점이니까!
- 손실(Loss)이 최소 → 예측값이 실제값과 가장 가까움
- 즉, 이 지점이 모델이 가장 잘 맞추는 상태
✅ 2. 최적의 파라미터(가중치)를 찾는 것
- 전역 최소점은 모델 파라미터가 최적으로 조합된 상태를 의미해요.
- 이걸 찾아야 좋은 예측을 할 수 있음
🧗 쉽게 비유하면?
🎢 산 속에서 가장 낮은 골짜기 찾기!
- 여러분은 산속에서 눈을 가리고 걷고 있어요. (→ 경사하강법으로 파라미터 조정 중)
- 가장 낮은 지점 = 전역 최소점
- 거기까지 가면 더 이상 낮출 수 없는 최적의 지점
하지만…
- 도중에 작은 웅덩이(=지역 최소점)에 빠질 수도 있어요!
- 전역 최소점은 아니지만, 거기서 더 움직이면 오히려 올라가는 것처럼 보일 수 있음
🎨 예: 웹툰 생성 모델 만들기
🎨 예: 웹툰 생성 모델 만들기
가정:
- 웹툰 대사를 자동으로 만들어주는 모델 또는
- 그림 스타일을 학습해서 비슷한 웹툰 컷을 생성하는 모델
🧠 이론이 어떻게 적용되는지?
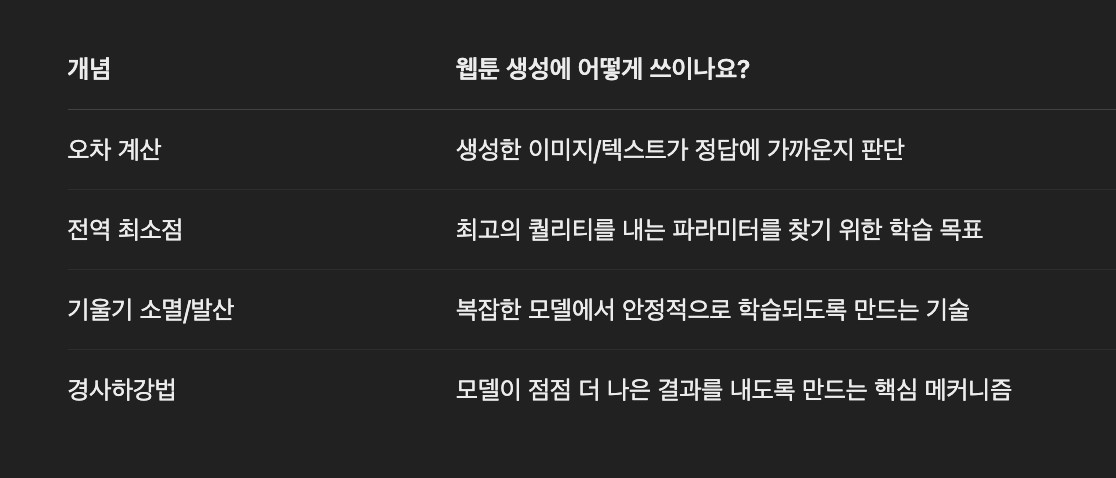
✅ 1. 오차 계산 (MSE, MAE 등)
어떤 걸 얼마나 잘 생성했는지 판단할 기준
- 예시 1: 웹툰 캐릭터 얼굴을 자동 생성
- 예측된 이미지(픽셀 값) vs 정답 이미지의 차이
- → MSE를 이용해 두 이미지의 픽셀 간 차이 평균 제곱값을 계산
- → 값이 작을수록 더 정답에 가까운 그림이라는 뜻!
- 예시 2: 웹툰 대사를 자동 생성
- 예측된 문장 vs 실제 문장
- → Cross Entropy Loss 같은 텍스트 전용 오차 함수를 사용함
✅ 2. 전역 최소점
모델이 최고 성능을 발휘할 수 있는 파라미터 조합을 찾는 목표
- 학습 중에 계속 가중치(w, b)를 바꾸며 손실(loss)을 줄이는 게 목표예요.
- 손실이 가장 작아졌을 때 → 전역 최소점에 가까워짐
- 이때의 파라미터를 저장해서 모델 최종 버전으로 사용
✅ 3. 기울기 소멸 / 발산
깊은 모델에서 학습이 안 되는 원인 방지
- 웹툰 생성은 종종 딥하고 복잡한 모델을 사용해요 (예: GAN, Transformer, VAE)
- 학습 중에:
- 기울기 소멸: 앞단 레이어는 거의 안 바뀜 → 그림이 흐릿해짐
- 기울기 발산: 학습이 튀어서 이상한 그림 생성
- 그래서:
- ReLU, LeakyReLU 같은 활성화 함수
- BatchNorm, Gradient Clipping 같은 기법들로 문제 방지
✅ 4. 손실 함수를 줄이는 방향으로 학습 (Gradient Descent)
- 네트워크가 "이 그림이 정답에 가까워졌는지?" 확인하고
- 오차를 줄이기 위해 파라미터를 살짝 조정하는 작업을 수천~수만 번 반복
- 그 과정을 통해 점점 더 정교한 웹툰을 그리는 모델이 됨
딥러닝(Deep Learning)
- 은닉층이 여러 개인 심층 신경망(Deep Neural Network, DNN)을 기반으로 한 학습 방식
- 대용량 데이터와 높은 계산 성능을 기반으로 비약적인 발전
- 이미지 인식, 음성 인식, 자연어 처리 등 다양한 분야에 활용
Deep 출현
2006년부터는 딥러닝(Deep Learing) 이라는 용어가 사용되기 시작
이때부터 인공신경(Neural)이라는 용어 대신 '딥(Deep)' 이라는 용어를 사용하기 시작
길고 긴 침체기 동안 인공신경망이라는 용어만 들어가도 논문 채택이 거절당할 정도로 부정적 인식이 강했기 때문에
사람들의 이목을 끌 수 있는 새로운 단어가 필요했기 때문입니다.
사전훈련(Pre-training)
선행학습이라고도 부르며, 다층 퍼셉트론에서 가중치와 편향을 잘 초기화 시키는 방법을 뜻합니다.
- 2006년
- 역전파 를 고안했었던 제프리 힌튼
- 「A fast learning algorithm for deep belief nets」 논문
- 가중치의 초기값을 제대로 설정하면 깊이가 깊은 신경망도 학습이 가능하다
- 사전 훈련(Pre-training) 방식 제안
- 신경망을 학습시키기 전에 계층(에 입력층, 은닉층) 단위의 학습을 거쳐 -> 더 나은 초기 값을 얻는 방식
- 2007년
- 벤지오 (Bengio) 팀
- 「Greedy layer-wise training of deep networks」
- 오토 인코더 (Autoencoder)를 사용한 좀 더 간단한 사전 훈련 방법을 제안
오토인코더(Autoencoder)
입력층과 출력층이 동일한 네트워크에 데이터를 입력하여 비지도학습을 하는 것입니다.
인코더(Encoder)를 통해 입력 데이터에 대한 특징을 추출하고,
디코더(Decoder)를 통해 원본 데이터를 재구성하는 학습을 합니다.
가중치의 좋은 초기값을 얻는 목적으로 이용됩니다.
인코더와 디코더가 중요한 이유는 데이터 압축 때문입니다.
영상 데이터처럼 의미 없는 부분이 많은 데이터는 중요한 부분만 추려낸 후에도,
그 데이터로 원본을 복원할 수 있어 오토인코더가 딥러닝에서 중요한 모델로 자리 잡고 있습니다.
| 지도학습(Supervised Learning) | 비지도학습(Unsupervised Learning) | 강화학습(Reinforcement Learning) |
| 정답이 있는 데이터를 활용해 데이터를 학습시키는 것입니다. 입력 값(X data)이 주어지면 입력값에 대한 Label(Y data)를 주어 학습시키며 분류, 회귀 문제 |
답 라벨이 없는 데이터를 비슷한 특징끼리 군집화 하여 새로운 데이터에 대한 결과를 예측하는 방법 라벨링 되어있지 않은 데이터로부터 패턴이나 형태를 찾아야 하기 때문에 지도학습보다는 조금 더 난이도가 있다 클러스터링(Clustering) Dimentionality Reduction, Hidden Markov Model 여러 과일의 사진이 있고 이 사진이 어떤 과일의 사진인지 정답이 없는 데이터에 대해 색깔이 무엇인지, 모양이 어떠한지 등에 대한 피처를 토대로 바나나 집단, 사과 집단으로 판단 |
행동 심리학에서 나온 이론 분류할 수 있는 데이터가 존재하지 않음 데이터가 있어도 정답이 따로 정해져 있지 않음 자신이 한 행동에 대해 보상(reward)를 받으며 학습하는 것 게임을 예로들면 게임의 규칙을 따로 입력하지 않고 자신(Agent)이 게임 환경(environment)에서 현재 상태(state)에서 높은 점수(reward)를 얻는 방법을 찾아가며 행동(action)하는 학습 방법 특정 학습 횟수를 초과하면 높은 점수(reward)를 획득할 수 있는 전략 형성 행동(action)을 위한 행동 목록(방향키, 버튼)등은 사전에 정의가 되어야 합니다. 이것을 지도 학습(Supervised Learning)의 분류(Classification)를 통해 학습을 한다고 가정하면 모든 상황에 대해 어떠한 행동을 해야 하는지 모든 상황을 예측하고 답을 설정해야 하기 때문에 엄청난 양의 예제가 필요함 |
2. 딥러닝의 개요
인공신경망 (Artificial Neural Network) 개념
딥러닝의 기원은 인공신경망입니다.
인공신경은 사람의 신경망 구조에서 착안해 만 들어졌기 때문에 뉴런들의 연결, 즉 신경망을 인공적으로 흉내 낸 것
인간의 신경망(Neural Network)
인간의 뇌에는 수많은 뉴런이 존재하고 그 뉴런들은 시냅스로 서로 연결되어 있음

- 가지돌기에서 신호를 받아들임
- 신호가 축삭돌기를 지나 축삭말단으로 전달됨
- 축삭돌기를 지나는 동안 신호가 약해져서 축삭말단까지 전달되지 않거나 강하게 전달되기도 함
- 축삭말단까지 전달된 신호는 다음 뉴런의 가지돌기로 전달됨
- 수억 개의 뉴런 조합을 통해 손가락을 움직이거나 물체를 판별하는 등 다양한 조작과 판단 수행 가능
인공 신경망(Artificial Neural Network)
입력층: 가지돌기
출력층: 축삭말단
가중치: 축삭말단에 이르기까지의 신호의 크기

딥러닝(Deep Learning) 개념
여러 층(특히 은닉층이 여러 개)을 가진 인공신경망을 사용하여 머신러닝 학습을 수행하는 것
심층학습이라고도 불림

| 입력층 | 학습하고자 하는 데이터를 입력 받음 |
| 은닉층 | 모든 입력 노드로부터 입력값을 받아 가중합을 계산하고, 이 값을 활성화 함수에 적용하여 출력층에 전달 |
| 출력층 | 최종 결과 출력 |
| 가중치 | 입력 신호가 출력에 미치는 영향을 조절하는 매개변수로, 입력값의 중요도를 결정 |
| 편향 | 가중합에 더하는 상수로, 하나의 뉴런에서 활성화 함수를 거쳐 최종적으로 출력되는 값을 조절 |
가중합(Weighted Sum)
입력값과 가중치를 곱한 뒤 편향(Bias)을 더한 값
가중합(y) = (Xo x W0) + (X1 x W1) + (X2 x W2) + b

활성화 함수(Activation Function)
- 뉴런의 출력 여부를 결정하는 함수
- 주요 종류:
- Sigmoid: 0~1 사이 출력, 기울기 소실 문제 있음
- ReLU: 0 이상은 그대로, 0 이하는 0 → 빠르고 효율적, 현재 가장 많이 사용됨
인공신경망에서 각 뉴런이 입력을 받아 출력을 계산하는 함수
- 출력값을 0~1 사이의 값으로 반환해야 하는 경우에 사용 : 이진 분류 문제
- 비선형을 위해 사용
가중치(m)와 편향(b)을 구하는 과정이 선형의 수식들만 거친다면 무슨 일이 일어날까요?
어떤 복잡한 과정을 거쳐도 y= W^TX+b 라는 단순한 형식을 벗어날 수 없어 선형 구조만 유지됩니다.
선형 함수 f(x)=WX 식이 있다고 가정
은닉을 2개 사용한다면, 식은 f(f(f(x)= WWWX = KX 로 단순 하게 변형됩니다.
은닉층을 20개 사용한다고 해도 동일한 결과가 나옵니다.
선형함수로는 은닉층을 여러 개 추가해도 은닉층을 1개 추가한 것과 차이가 없다.
정확한 결과를 위해선 비선형 함수, 즉 활성화 함수가 필요합니다.
가중치 초기화
- 학습 초기에 가중치를 어떻게 정하느냐에 따라 성능이 달라짐
- 보통 무작위로 초기화하지만, Xavier, He 초기화처럼 전략적인 방식 사용
선형과 비선형

선형(Linear)
- 그래프가 직선(ine)의 모양을 취하는 것
- 1차 함수의 그래프 모 양을 유지하는 것
비선형(Non-linear)
- 직선이 아닌 것을 뜻합니다.
- 그래프에서 곡선 모양을 취하는 것
시그모이드(Sigmoid) 함수

로지스틱 함수
x값의 변화에 따라 0에서 1까지의 값을 출력하는 S자형 함수
이진 분류 문제
출력층 노드가 한 개이고, 그 한 개의 노드에서 0~1의 값을 반환합니다.
시그모이드 함수는 과거에 인기가 많았지만,
딥러닝 모델의 깊이가 깊어질수록 기울기가 사라지는 기울기 소멸 문제가 발생해 현재 딥러닝 모델에는 추천하지 않습니다.
하이퍼블릭 탄젠트(Hyperbolic Tangent) 함수

시그모이드 함수와 유사
-1~1의 값을 가지면서 데이터의 평균이 0이라는 점이 다릅니다.
데이터의 평균이 0이라는 점만 다를 뿐이지만 거의 모든 측면에서 시그모이드 함수보다 성능이 우수합니다.
하이퍼볼릭 탄젠트 함수에서도 기울기 소멸 문제가 발생하므로 주의해서 사용해야 합니다.
렐루 (RecLu) 함수

x가 음의 값을 가지면 0을 출력하고, 양의 값을 가지면 x를 그대로 출력
함수 형태도 max(0, x)로 계산이 간단하여 학습 속도가 매우 빠릅니다.
기울기가 1 --> 기울기 소멸 문제도 해결됩니다.
죽은 렐루(Dying ReLu)
입력값이 음수이면 기울기가 0이 된다는 점입니다.
기울기가 0인 뉴런은 사용이 불가능한 상태
리키렐루(LeakyReLL) 함수

렐루 함수와 거의 유사하지만 차이점은 가중치 곱의 합이 0보다 작을 때의 값도 고려한다는 점입니다.
이 함수는 렐루 함수의 죽은 렐루 현상을 보완합니다.
소프트맥스(SoftMax) 함수

입력받은 값이 0~1 사이의 값으로 출력되도록 정규화하여 출력의 총 합이 1이 되는 특성을 갖는 함수입니다.
딥러닝에서 출력 노드의 활성화 함수로 많이 사용됩니다.
정규화(Normalization)
데이터의 범위를 사용자가 원하는 범위로 제한하는 것입니다.
예를 들어, 이미지 데이터의 경우 0~255 사이의 값을 갖는데, 이를255로 나누면 0~1.0 사이의 값을 갖게 됩니다.
딥러닝 학습
순전파(Forward Propagation)
입력층에서 출력층 방향으로 연산이 진행되면서 최종 출력값(예측값)이 도출되는 과정
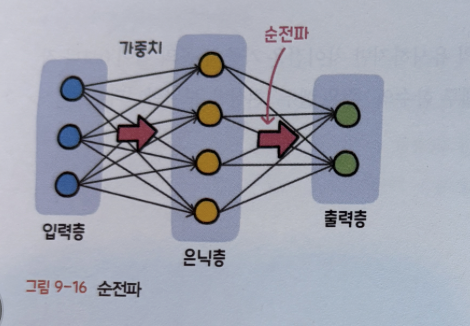
네트워크(신경망)를 구성하기 위해서는 하이퍼파라미터를 결정해야 합니다.
- 은닉충의 수
- 각 은닉층의 뉴런 수
- 활성화 합수
- 손실 함수
네트워크가 구성된 이후에는
입력값이 은닉층을 지나면서
곱해진 가중치값의 결과가 출력층으로 향합니다.
출력층에서는 모든 연산을 마친 예측값이 출력됩니다.
손실함수(Loss Function)

예측값과 실제값의 차이를 구하는 함수입니다.
이 두 값의 차이가 클 수록 손실함수의 값은 커지고,
차이가 작을수록 손실함수의 값도 작아집니다.
회귀: 평균 제곱 오차(MSE, Mean Squared Brror)
분류 문제: 크로스 엔트로피(Cross Entropy)
손실함수가 중요한 이유는 딥러닝의 학습 과정에서 손실함수의 값이 최소가 되는 두 개의 매개변수인, 가중치(w)와 편향(b)을 찾을 수 있기 때문입니다.
옵티마이저(Optimizer)

딥러닝에서 학습 속도를 빠르고 안정적이게 만드는 것을 뜻합니다.
배치(Batch)
가중치 등 매개변수의 값을 조정하기 위해 사용하는 데이터의 양을 뜻합니다.
전체 데이터(전체 배치)를 가지고 매개변수(가중치, 편향) 의 값을 조정할 수 있고,
정해진 양의 데이터(미니 배치)만 가지고 매개변수의 값을 조정할 수도 있습니다.
일반적으로 전체 데이터를 한번에 학습하게 되면 계산량이 많아질 뿐만 아니라 속도도 느려질 수 있기 때문에
미니 배치를 이용한 학습을 합니다.
딥러닝 학습의 핵심: 역전파 (Backpropagation)
- 출력 값과 정답 값의 차이(오차)를 기반으로 가중치를 수정하는 과정
- 오차를 각 층으로 전파하며, 경사하강법(Gradient Descent)으로 학습 진행
역전파(Backpropagation)

오차(예측값과 실제값의 차이)를 역방향으로 전파시키면서(출력층-> 은닉층 - 입력층) 가중치를 업데이트하는 것입니다.
경사 하강법

경사 하강법을 이용해 오차를 줄이는 방향으로 가중치를 수정합니다.
가중치를 수정할 때에는 순전파에서 계산한 결과 y=f(x)의 편미분값을 오차에 곱해
출력층- 은닉층-> 입력충 순 서로 전달합니다.
이때 편미분을 사용하는 이유는 많은 노드들에 부여되는 모든 가중치값을 전부 고려하지 않고
계산하려는 노드와 연결된 가중치값만을 고려할 수 있기 때문입니다.
3. 딥러닝의 유형
- CNN (Convolutional Neural Network): 이미지 처리에 특화
- RNN (Recurrent Neural Network): 시퀀스 데이터 처리 (ex. 문장)
- LSTM (Long Short-Term Memory): RNN의 장기 의존성 문제 해결
- GAN (Generative Adversarial Network): 이미지를 생성하는 데 사용
- Transformer: 문맥을 이해하고 병렬 처리 가능, GPT/BERT 기반 구조
DFN
심층 순방향 신경망(Deep Feedforward Network, DFN)

심층신경망이라고도 부르며, 딥러닝에서 가장 기본으로 사용하는 인공신경망입니다.
입력층, 은닉층, 출력층으로 이루어져 있습니다.
이때 중요한 것은 은닉층이 2개 이상이어야 한다 는 점입니다.
순방향(Feedforward)이라고 부르는 이유는 데이터가 입력층, 은닉층, 출력층의 순서로 전파되기 때문입니다.
단점
은닉층이 수십 개에서 수백 개라고 할 때, 입력 데이터가 시간 순서에 따른 종속성을 가질 경우 -> 시계열 데이터 처리에 한계가 있습니다.
그래서 이러한 문제점을 해결하기 위해 제안된 것이 순환 신경망입니다.
순환 신경망(Recurrent Neural Network, RNN)
시계열 데이터
일정한 시간 동안 관측되고 수집된 데이터를 의미
주식 데이터나 제조 공정에서 수많은 센서로부터 수집되는 데이터가 대표적입니다.

RNN은 시계열 데이터와 같이 시간적으로 연속성이 있는 데이터를 처리하기 위해 고안된 인공신경망입니다.
시계열 데이터가 딥러닝 신경망의 입력값으로 사용될 때는 데이터의 특성상
앞에 입력된 데이터 (이전 시간의 데이터)가 뒤에 입력된 데이터에 영향을 미칩니다.
입력된 데이터를 단순히 입력층, 은닉층, 출력층의 순서로 전파하기만 하는 DPN으로는 시계열 데이터를 정확히 예측할 수 없습니다.
그렇다면 RNN 구조는 DFN과 어떻게 다를까요?
은닉층의 각 뉴런에 순환(recurrent) 구조를 추가하여
이전에 입력된 데이터가 현재 데이터를 예측할 때 다시 사용될 수 있도록 하였습니다.
현재 데이터를 분석할 때 과거 데이터를 함께 고려하여 정확한 데이터 예측이 가능합니다.
장기 의존성(Long-Te Dependency) 문제
신경망 층이 깊어질수록(은닉층 수가 많을수록) 먼 과거의 데이터가 현재에 영향을 미치지 못하는 문제가 발생합니다
이를 해결하기 위해 제안된 것이 LSTM입니다.
LSTM
LSTM(Long Short-Term Memory)
🔍 LSTM?
LSTM은 RNN(Recurrent Neural Network)의 일종으로,
시간 순서가 있는 데이터(시퀀스) 를 잘 처리하는 모델이에요.
예:
- 소설 쓰기
- 챗봇 대화 예측
- 음악 생성
- 대사/문장 자동 생성
📌 그래서 LSTM은 "과거의 정보(기억)"을 잘 활용해서
다음에 올 단어, 문장, 감정 등을 예측하는 데 강합니다.
LSTM은 무슨 정보를 기억하고, 무슨 걸 잊고, 무슨 걸 다음에 쓸지
세 가지 문으로 똑똑하게 판단하는 모델이에요.
그래서 이야기가 길어져도 앞의 맥락을 기억하고 자연스러운 대사를 만들 수 있죠.

RNN과는 다르게 신경망 내에 메모리를 두어 먼 과거의 데이터도 저장할 수 있도록 하였습니다.
게이트(Gate)
입출력을 제어하기 위한 소자(논리적인 장치)
- 입력 게이트 : 현재의 정보를 기억하기 위한 소자입니다. 과거와 현재 데이터가 시그모이드 함 수와 하이퍼볼리 탄젠트 함수를 거치면서 현재 정보에 대한 보존량을 결정합니다.
- 망각 게이트 : 과거의 정보를 어느 정도까지 기억할지 결정하는 소자입니다. 과거와 현재 데이터 가 시그모이드 함수를 거쳐 나온 값을 과거의 정보와 곱합니다. 따라서 시그모이드 함수의 출력이 0 일 경우 과거의 정보는 완전히 잊혀지고, 1일 경우에는 과거의 정보가 온전히 보존됩니다.
- 출력 게이트 : 출력층으로 출력할 정보의 양을 결정하는 소자입니다.
현재까지 제안된 RNN 기반의 응용 서비스들은 대부분 LSTM을 이용하여 구현되었습니다.
🎯 Gate 예시 - “오늘은 정말 힘든 하루였어.”
예: “오늘은 정말 힘든 하루였어.” → 다음 문장을 자동으로 이어쓰기
LSTM은 이전 단어들을 기억해서,
👉 "슬픈 톤이네, 감정이 이어져야겠네" 하고 판단해서
→ “그래도 내일은 나아질 거야.” 같은 문장을 만들어낼 수 있어요.
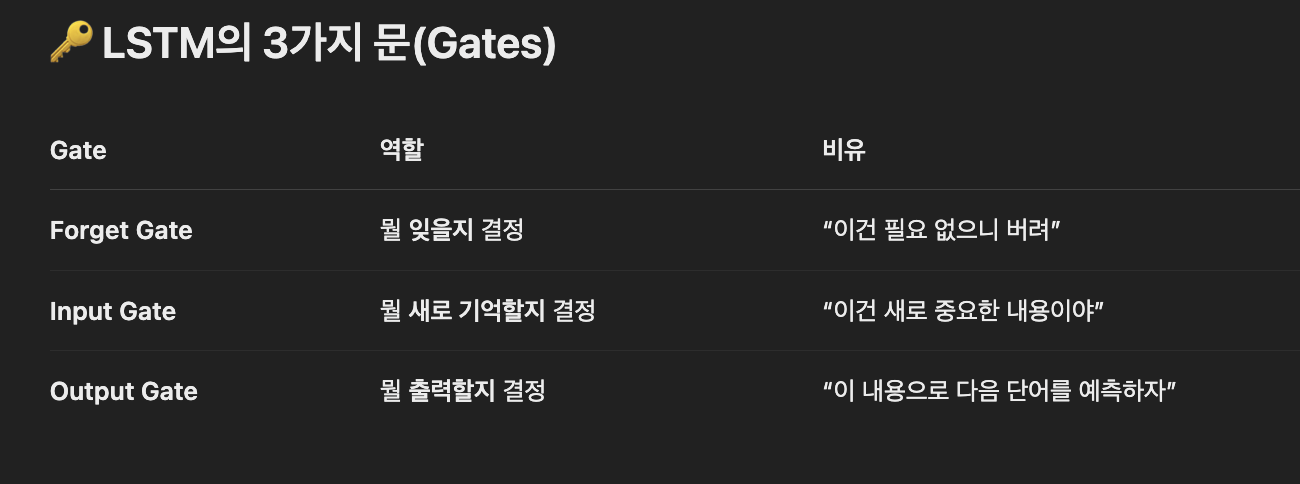
🔄 전체 흐름 요약
[이전 기억] + [지금 단어]
⬇
🔘 Forget Gate → 잊을 정보 삭제
🔘 Input Gate → 새 정보 선택
🔘 Output Gate → 다음 단어 생성
⬇
[새 기억 저장] → 다음 입력으로 넘김
🤖 예시로 다시!
입력: “나는 오늘”
1. Forget Gate:
- 과거에 있던 “날씨 얘기”는 필요 없다고 판단 → 버림
2. Input Gate:
- “오늘”이라는 키워드를 새로 중요하게 저장
3. Output Gate:
- 이 정보를 기반으로 → “기분이 좋았다” 같은 다음 단어 예측!
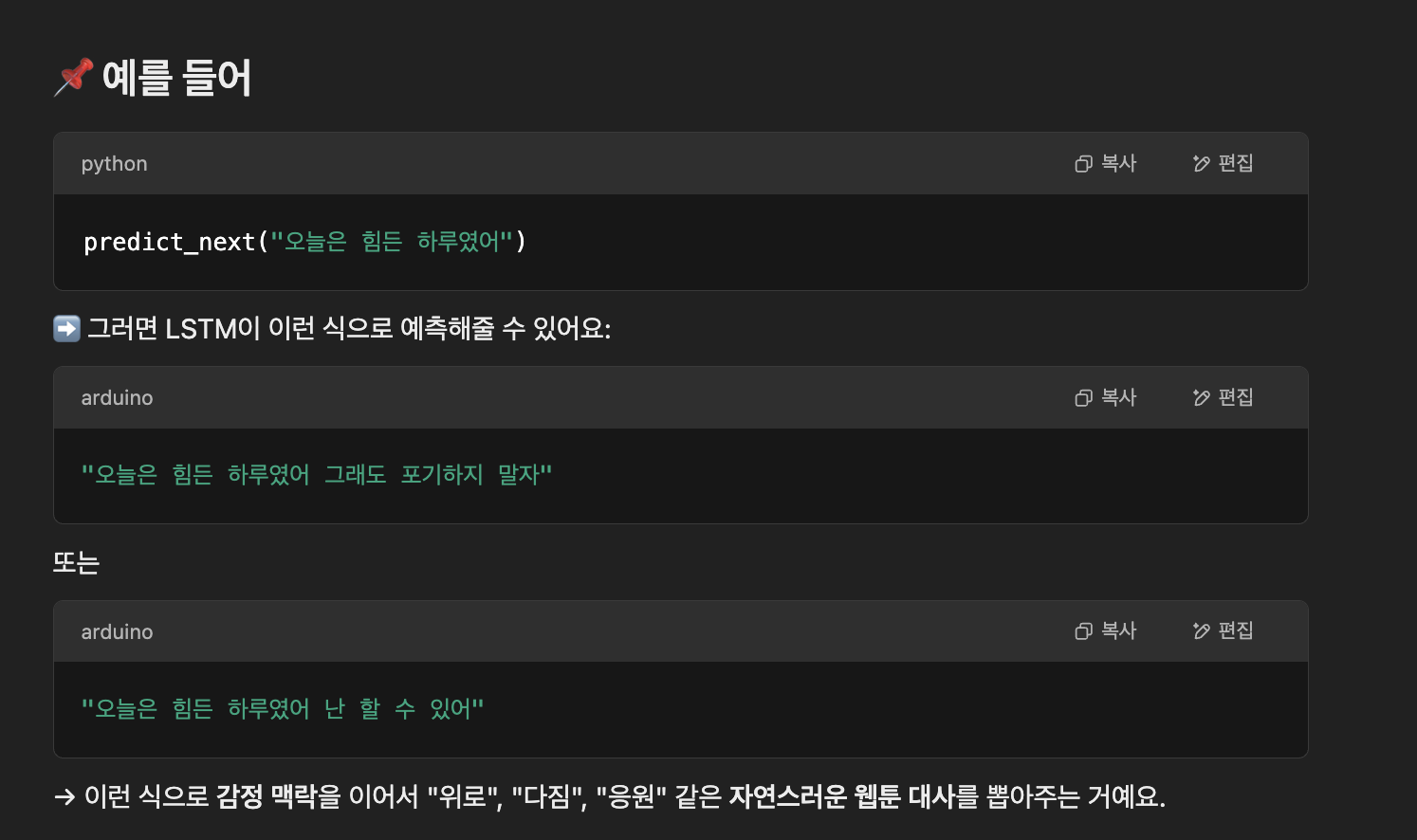
“내가 오늘 힘든 날이었어~”
이런 문장을 입력으로 주면,
LSTM은 비슷한 분위기, 감정, 흐름을 가진 문장을 자동으로 이어서 만들어줍니다.
지금 만든 LSTM 모델은 서로 대화하는 방식이 아니라,
“비슷한 분위기, 감정 흐름, 단어 패턴”을 이어주는 모델이에요.
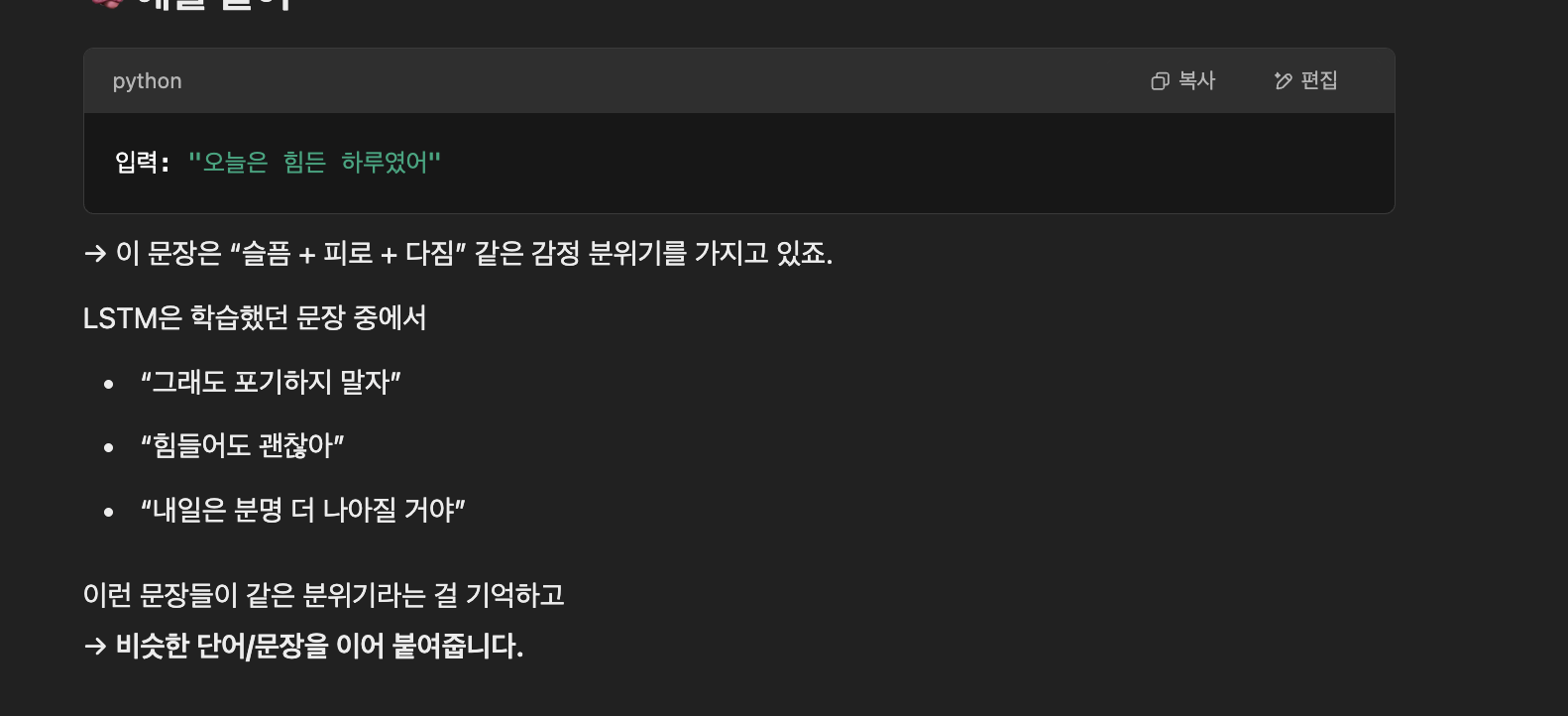
🎯 왜 이런 일이 가능하냐?
이유는 딱 하나:
✨ LSTM은 과거 문장을 기억하면서 다음 단어를 예측하는 능력이 있기 때문!
그래서 "오늘은 힘든 하루였어"라는 문장에서
→ "포기", "괜찮아", "계속 나아가자" 같은 감정적으로 이어질 단어들을 학습 데이터를 기반으로 뽑아주는 거예요.
지금 만든 LSTM은 “말을 주면 비슷한 말을 예측하는 애”고,
대화하는 AI는 “말을 주면 대답을 해주는 애”입니다!
🧠 GPT의 정체:
GPT = Generative Pretrained Transformer

🔥 GPT는 뭐가 특별할까?
✅ LSTM보다 훨씬 똑똑해요
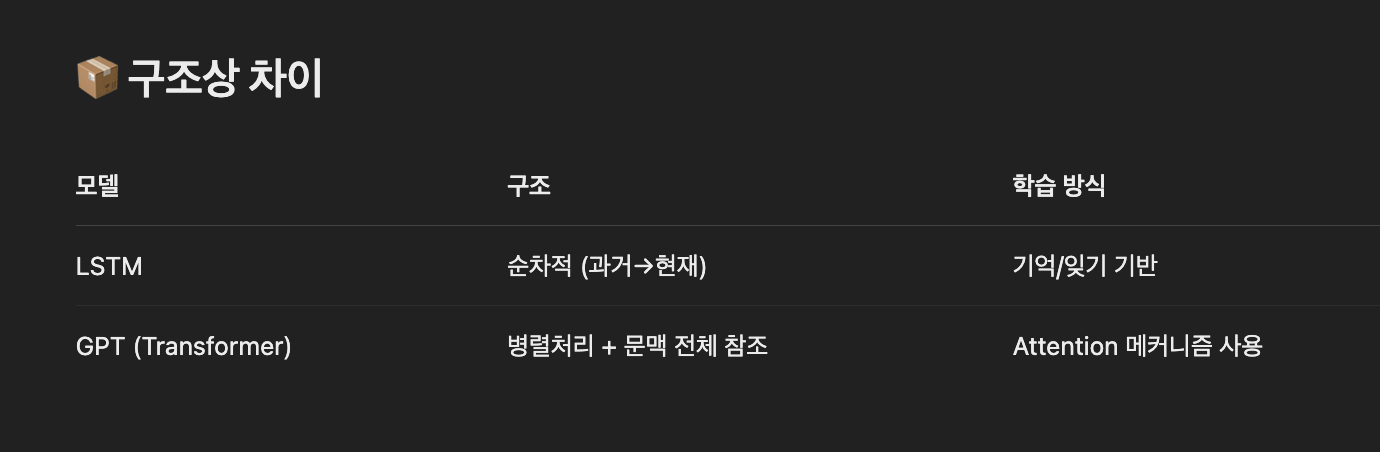
| 비교 | LSTM | GPT |
| 기억 방식 | 순차적으로 기억 (시간 흐름 따라) | 전체 문장을 한 번에 보고 문맥 파악 |
| 장점 | 문장 예측, 간단한 생성 | 대화 이해, 맥락 유지, 길고 복잡한 대사 가능 |
| 한계 | 긴 문장에 약함, 맥락 잊기 쉬움 | 수백 줄도 기억 가능, 논리적 흐름 잘 유지 |
🗣️ 그래서 GPT는 이렇게 행동해요
💬 너: "오늘 기분이 별로야..."
🤖 GPT: "무슨 일 있었어? 말해봐."
- 이건 단순히 비슷한 말을 찾은 게 아니라,
- 네가 왜 그런 말을 했는지 맥락을 이해하고,
- 그에 맞는 대답(응답)을 만들어낸 것이에요.
🔍 Attention? 뭐야 그건?
“이 단어는 문장에서 어떤 단어와 가장 관련 있을까?”
→ GPT는 문장 전체를 훑으면서 중요한 부분에 집중할 수 있어요.
(예: “그녀가 말했다”에서 "그녀"가 누구인지 파악)
💬 한 줄 요약
GPT는 Transformer라는 최신 구조를 써서,
단어의 흐름뿐 아니라 문맥과 의미를 깊이 이해할 수 있는
대화형 초거대 언어 모델이에요.
🎨 그럼 웹툰 생성에서는 어떻게 쓰이냐?
🎨 그럼 웹툰 생성에서는 어떻게 쓰이냐?
✅ 1. 웹툰 대사 생성, 줄거리 생성
웹툰에 나올 "대사", "스토리 흐름", "장면 설명" 을 자동으로 생성하는 데 LSTM 사용 가능
- 예시:
- 사용자가 "두 캐릭터가 다투는 장면"이라고 하면
→ LSTM이 그 상황에 맞는 대사를 자동으로 만들어줌 → 예: "왜 그렇게 말했어?", "미안해, 그럴 뜻은 아니었어..."
- 사용자가 "두 캐릭터가 다투는 장면"이라고 하면
- 또는 연속된 장면 설명을 기반으로 다음 대사/내용을 예측할 수도 있음
✅ 2. 시나리오 기반 이미지 생성 보조
대사 or 줄거리 → 이미지 생성 모델로 넘길 때
LSTM이 텍스트를 먼저 생성하고 →
그걸 기반으로 GAN이나 Diffusion 모델이 이미지를 그림
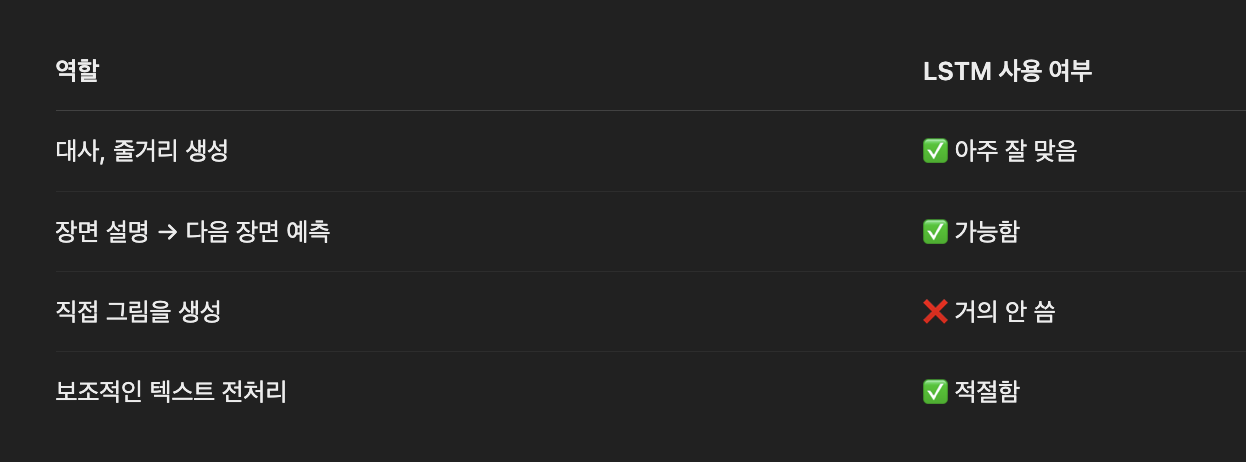
❌ 어디에 잘 안 쓰이냐?
✋ 이미지 자체를 직접 생성하는 데에는 거의 안 쓰입니다
- 이미지 생성은 주로 CNN, GAN, Transformer, Diffusion 같은 구조가 사용됨
- 이유:
- LSTM은 시퀀스 처리에 특화
- 이미지는 공간(2D 구조)이 중요 → CNN 계열이 더 적합
🧠 웹툰 생성 전체 구조 (LSTM 활용 예시)
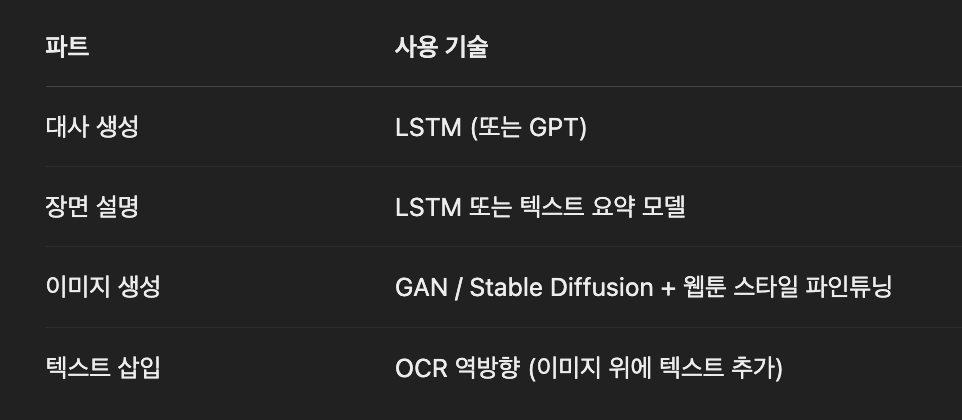
[사용자 입력]
→ “두 캐릭터가 싸우는 장면 만들어줘”
⬇
[1단계] LSTM 기반 스토리/대사 생성
→ “왜 그렇게 말했어?”
→ “미안해, 그럴 뜻은 아니었어…”
⬇
[2단계] 장면 설명 자동 생성 (ex. “A가 눈물 흘림”, “B가 고개 돌림”)
⬇
[3단계] 이미지 생성 모델 (GAN, Diffusion 등)
→ 위 설명을 기반으로 웹툰 스타일 컷 자동 생성
⬇
🖼️ 최종 결과:
- A가 우는 얼굴을 그린 웹툰 컷
- B가 돌아서 있는 장면 컷
- 아래에 자동 생성된 대사 삽입
- LSTM 대신 GPT-2/GPT-3.5/Claude 같은 LLM으로 대사 퀄리티를 올릴 수 있어요.
- Diffusion 기반 생성 모델에 웹툰 작가별 스타일을 반영해 개성 있는 그림 생성도 가능해요.
LSTM으로 웹툰 장면 대사 자동 생성기 만들기
- 입력: 상황 요약 (ex. “슬픈 이별 장면”)
- 출력: 두 캐릭터 간 대사 2~3줄 생성
- 보너스: HuggingFace에서 KoGPT, KoBART 같은 사전학습 모델로도 가능
🧪 [🔥 웹툰 대사 생성 LSTM 예제 코드]
# 1. 라이브러리 설치 (Colab에서는 주석 제거해서 실행)
# !pip install tensorflow
import numpy as np
import tensorflow as tf
from tensorflow.keras.models import Sequential
from tensorflow.keras.layers import LSTM, Dense, Embedding
from tensorflow.keras.preprocessing.text import Tokenizer
from tensorflow.keras.preprocessing.sequence import pad_sequences
# 2. 예제 대사
texts = [
"오늘은 정말 힘든 하루였어",
"그래도 포기하지 말자",
"내일은 분명 더 나아질 거야",
"난 할 수 있어",
"계속 나아가자",
"힘들어도 괜찮아",
"웃으면서 이겨내자"
]
# 3. 텍스트 토큰화
tokenizer = Tokenizer()
tokenizer.fit_on_texts(texts)
total_words = len(tokenizer.word_index) + 1
# 4. n-gram 시퀀스 생성
input_sequences = []
for line in texts:
token_list = tokenizer.texts_to_sequences([line])[0]
for i in range(1, len(token_list)):
n_gram_seq = token_list[:i+1]
input_sequences.append(n_gram_seq)
# 5. 시퀀스 패딩
max_seq_len = max(len(x) for x in input_sequences)
input_sequences = pad_sequences(input_sequences, maxlen=max_seq_len, padding='pre')
# 6. 입력(X) / 출력(y) 분리
X = input_sequences[:, :-1]
y = tf.keras.utils.to_categorical(input_sequences[:, -1], num_classes=total_words)
# 7. LSTM 모델 정의
model = Sequential()
model.add(Embedding(total_words, 10, input_length=max_seq_len-1))
model.add(LSTM(64))
model.add(Dense(total_words, activation='softmax'))
model.compile(loss='categorical_crossentropy', optimizer='adam', metrics=['accuracy'])
model.fit(X, y, epochs=200, verbose=0)
# 8. 다음 단어 예측 함수
def predict_next(text, num_words=5):
for _ in range(num_words):
token_list = tokenizer.texts_to_sequences([text])[0]
token_list = pad_sequences([token_list], maxlen=max_seq_len-1, padding='pre')
predicted_probs = model.predict(token_list, verbose=0)
predicted_index = np.argmax(predicted_probs)
output_word = ''
for word, index in tokenizer.word_index.items():
if index == predicted_index:
output_word = word
break
text += ' ' + output_word
return text
# 9. 테스트
print(predict_next("오늘은")) # → "오늘은 정말 힘든 하루였어" 와 유사한 문장 생성
🧠 이 코드는 어떻게 작동하냐면?
- 입력된 단어들(예: "오늘은") 을 기반으로
- LSTM이 기억을 활용해서 다음에 나올 단어를 예측하고
- 웹툰 대사처럼 자연스러운 문장을 이어서 생성합니다!
🧠 CNN이란?
이미지에서 특징(패턴)을 추출하는 데 특화된 신경망 구조
- 예를 들어 웹툰 이미지에서:
- 선(엣지), 색상, 눈 모양, 배경 등을 감지함
- 이미지 분류, 인식, 스타일 분류 등에서는 CNN 단독으로도 훌륭해요
일반적인 인공신경망 모델은 완전연결층으로 이루어져 있습니다.
완전연결층 특성상 1차원 데이터만 입력으로 받는다는 것입니다.
컬러 사진 데이터는 3차원 데이터이므로,
3차원 데이터를 완전연결층으로 구성된 신경망으로 학습시키려면
3차원의 데이터를 1차원으로 평면화시켜야 합니다.
이미지에 대한 공간 정보가 유실되어 특징을 잘 추출하지 못하면 학술에 비효율적일 수 있는데, CNN은 이러한 문제를 해결 모델
🔧 CNN이 실제로 어떻게 사용되냐면? - 웹툰 이미지 생성
🎨 그런데 웹툰 이미지를 생성한다면?
CNN만으로는 웹툰 이미지를 만들기 어렵지만,
GAN, VAE, Diffusion 등 생성 모델과 함께 쓸 때 CNN은 핵심 부품입니다!

CNN만으로는 "그림을 감지"할 수 있지만, "새 그림을 그리진 못해요."
그래서 생성 구조와 함께 사용됩니다.
🔧 CNN이 실제로 어떻게 사용되냐면?
✅ 1. GAN(Generative Adversarial Network)
웹툰 이미지 생성에 가장 많이 사용되는 구조
- 생성자(Generator): CNN(또는 Deconv)을 써서 이미지를 만듦
- 판별자(Discriminator): CNN을 써서 "이 그림이 진짜인가?" 판별
🖼 예:
"마네킹 얼굴 스타일의 웹툰을 생성"
→ Generator가 랜덤 노이즈나 조건 정보를 받아서 얼굴을 그림
→ CNN이 그걸 평가함
→ 학습 반복 → 퀄리티 좋은 이미지 생성
✅ 2. VAE (Variational Autoencoder)
- 입력 이미지를 CNN으로 압축(인코딩)
- 다시 CNN으로 복원(디코딩)
- 그 과정에서 새로운 이미지를 샘플링할 수 있음
✅ 3. 조건부 생성 (Conditional GAN / Text-to-Image)
- 대사, 장르, 감정 등 조건을 주고 웹툰 이미지 생성
- CNN으로 조건을 해석하거나 이미지 출력
합성곱 신경망(Convolutional Neural Network, CNN)
인간의 시각 처리 방식을 모방한 신경망
이미지 처리가 가능하도록 합성곱(Convolution) 연산을 도입하였습니다.
2016년에 공개된 알파고에도 CNN 기반의 딥러닝 모델이 이용되었을 정도로 CNN은 인공신경망 중에서 가장 발전된 형태

합성곱 신경망 구조

합성곱층(Convolutional Layer)
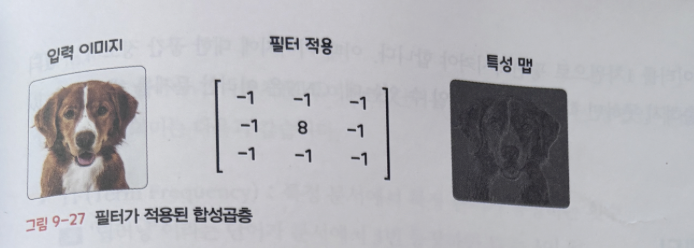
이미지를 분류하는 데 필요한 특징(Feature) 정보들을 추출하는 것입니다.
특징 정보는 어떻게 추출할 수 있을까요?
필터(Filter)란 이미지의 특징을 찾아내기 위한 파라미터이며, 커널(Kernel)이라고도 부릅니다.
필터는 하나 이상 사용할 수 있으며, 필터를 여러 개 사용하면 한번에 여러 특징을 추출할 수 있습니다.
합성곱층에 필터가 적용되면 -> 이미지의 특징들이 추출된 특성 맵 이라는 결과를 얻을 수 있습니다.
풀링층(Pooling Layer)

합성곱층의 출력 데이터(특성 맵)를 입력으로 받아서
출력 데이터인 활성화 맵(Activation Map)의 크기를 줄이거나 특정 데이터를 강조하는 용도로 사용됩니다.
풀링충 을 처리하는 방법
- 최대 풀링(Max Pooling)
- 평균 풀링(Average Pooling)
- 최소 풀링(Min Pooling)
같정사각 행렬의 특정 영역에서 최댓값을 찾거나 평균값 을 구하는 방식으로 동작합니다.
완전연결층(Fully-connected Layer)
합성곱층과 풀링층으로 추출한 특징을 분류하는 역할을 합니다.
CNN은 합성곱층에서 특징만 학습하기 때문에
DFN이나 RNN에 비해 학습해야 하는 가중 치의 수가 적어 학습 및 예측이 빠르다는 장점이 있습니다.
최근에는 CNN의 강력한 예측 성능과 계산상의 효율성을 바탕으로 이미지뿐만 아니라 시계열 데이터에도 적용해 보는 연구가 활발히 진 행되고 있습니다.
워드 임베딩(Word Embedding)
단어를 벡터로 표현하는 방법입니다.
즉, 기계가 사람의 언어 를 이해할 수 있도록 변환해 준다고 이해하면 됩니다.
GloVe, Blmo등 다양한 모델이 있으며, 성능이 우수하기 때문에 많이 사용되고 있습니다.
원-핫 인코딩(One-hot Encoding)

N개의 단어를 각각 N차원의 벡터로 표현하는 방식입니다.
단어가 포함되는 자리엔 1을 넣고 나머지 자리에는 0을 넣음
워드투벡터(Word2Vec)
비슷한 콘텍스트(context)에 등장하는 단어들은 유사한 의미를 지닌 다는 이론에 기반하여 단어를 벡터로 표현해 주는 기법입니다.
'주변 단어를 알면 특정 단어를 유추 할 수 있다'라는 원리를 기반으로 한 것으로,
대표적인 모델
- CBOW (Continuous Bag-Of-Words)
- Skip-gram
| CBOW (Continuous Bag-Of-Words) | Skip-gram |
| 전체 콘텍스트로부터 특정 단어를 예측하는 것 | 특정 단어로부터 전체 콘텍스트의 분포(확률) 를 예측하는 것 |
| 철수는 ------ 를 구매했다. | -------- 도서 ------------- |
TF-IDF
단어마다 가중치를 부여하여 단어를 벡터로 변환하는 방법입니다.
TF-IDF는 단어의 "빈도수 + 희귀성"을 동시에 고려해서,
문서 내에서 어떤 단어가 중요한지 판단하는 통계적 방법입니다!
TF-IDF = TF × IDF
→ 문서 안에서 자주 등장하면서, 다른 문서들에는 잘 안 나오는 단어에 높은 점수를 줌!

- TF(Term Frequency) : 특정 문서에서 특정 단어가 등장하는 횟수 에 '딥러닝'이라는 단어가 문서에서 3번 등장하면 TP는 3이 됨
- DF(Document Frequency) : 특정 단어가 등장한 문서의 수 에 '딥러닝'이라는 단어가 문서1과 문서2에서 언급되었다면 DP는 2가 됨
- IDF(Inverse Document Frequency) : DF에 반비례하는 수
TF-IDF의 경우, '은', '는', '이', 가'와 같은 조사는 등장 빈도수가 높기 때문에 IDP는 작은 값을 갖게 됩니다.
따라서 조사의 가중치는 낮습니다.
즉, TF-IDF를 통해 단어에 대한 중요도를 알 수 있습니다.
🎯 왜 필요한가요?
한국어에 있는 '은', '는', '이', '가' 같은 조사나 흔한 단어들은
어디에나 자주 나와서 의미가 적음
→ 그래서 이런 단어들의 IDF는 작아져서 가중치가 낮아짐
반면에,
"딥러닝", "클러스터링", "추천 알고리즘" 같은 전문 용어는
특정 주제의 문서에만 등장 → IDF가 크고 중요도가 높게 나옵니다.

- 단어 "딥러닝"은 A와 B에서 나옴 → DF = 2
- "나는", "은", "먹었다" 등은 모든 문서에서 나올 수도 있음 → DF가 크고 IDF가 작아짐
→ 결과적으로 "딥러닝"의 TF-IDF 점수는 높고, "나는" 같은 단어의 점수는 낮아요.

- 딥러닝이라는 단어의 노란색, 주황색 막대가 높으면:
- 문서 1, 2에서 딥러닝의 TF-IDF 점수가 높다는 뜻이에요.
- 즉, 이 문서들에서 딥러닝이 중요하게 사용됨.
- 나는이라는 단어는 모든 문서에 등장하기 때문에
- 모든 색의 막대가 낮거나 비슷함
- → 흔한 단어라 중요도가 낮다 (IDF가 낮음)
- 색상은 각각 문서를 구분하는 용도이고,
막대의 높이가 TF-IDF 점수입니다.
→ 높을수록 그 문서에서 그 단어가 중요하다는 뜻이에요!

Fasttext
부분 단어라는 개념을 도입하여 단어를 벡터로 변환하는 방식입니다.
FastText는 **페이스북 AI 연구팀(FAIR)**에서 개발한 워드 임베딩(Word Embedding) 기법입니다.
Fasttext는 단어를 벡터로 변환하기 위 해 부분 단어(Sub Words)라는 개념을 도입하였습니다.
Word2Vec처럼 단어를 벡터로 바꾸지만, 단어 내부의 형태소(부분 단어) 정보를 활용한다는 점이 특징이에요.

🍎 예시로 쉽게 이해해 보자
단어: "apple"
FastText는 이 단어를 통째로 벡터화하지 않고, 아래처럼 부분 단어(Subword) 로 나눕니다:
<ap, app, ppl, ple, le>, <apple> ← 3글자짜리 n-gram- < >는 단어의 시작과 끝을 표시하는 특수 토큰입니다.
- n-gram이라는 기술을 사용해서 연속된 3개의 글자 단위로 쪼갠 거예요.
👉 즉, "apple"은 이 여러 개의 Subword 벡터들의 평균값으로 최종 벡터를 만듭니다.
🔤 예시 단어: "사랑하다"
✅ 일반 Word2Vec은:
- "사랑하다"라는 단어를 하나의 벡터로 만듭니다.
- "사랑", "사랑하", "사랑한다"는 전혀 다른 벡터가 됨 → 관계를 이해 못 함.
✅ FastText는:
- "사랑하다"를 글자 단위로 쪼개서 부분 단어(Subword) 로 나눔
(예: 3-gram 기준)
<사, 사라, 사랑, 랑하, 하다, 다>- 그리고 각각의 조각을 벡터로 만들고, 그 평균을 "사랑하다"의 벡터로 사용해요.

📌 그래서 뭐가 좋은데?
- 단어의 형태를 반영할 수 있음
- 예: "run", "running", "runner" → 공통된 subword를 통해 비슷한 의미로 학습됨
- 희귀 단어(OOV: Out of Vocabulary) 처리에 강함
- Word2Vec은 처음 보는 단어는 아예 모름 → FastText는 subword 단위로 추정 가능
- 어미 변화나 복합어가 많은 언어(예: 한국어, 독일어 등)에 특히 유리함
💬 한 줄 요약
FastText는 단어 전체가 아니라 **단어 내부의 조각들(Subword, n-gram)**을 벡터로 만들고, 그것들을 평균 내어 최종 단어 벡터를 생성하는 방식입니다.
N-gram
문자열에서 N개의 연속된 요소를 추출하는 방법입니다.
예 를 들어, "Best books about AI"를 3-grams(트라이그램(Trigram)를 이용하여 부분 단어로 표 현하면 다음과 같습니다.
"Best books about AI" → " Best books about", " books about AI"
부분 단어를 사용하면 워드투벡터에서
모르는 단어(out of Vocabulary)' 문제를 해결할 수 있기 때문에 임베딩에서 많이 사용되는 모델 중 하나입니다.
모르는 단어(Out of Vocabulary) 문제
입력 단어(혹은 문장)가 데이터베이스에 없어서 처리를 못 하는 문제를 뜻합니다.
적대적 생성 신경망(Generative Adversarial Network, GAN)

두 개의 신경망 모델이 서로 경쟁하면서 더 나은 결과를 만들어 내는 강화학습입니다.
생성과 판별 두 개의 신경망 모델이 서로 경쟁하면서 더 나 은 결과를 만들어 내는 강화학습입니다.
특히 이미지 생성 분야에서 뛰어난 성능을 보이고 있습니다.
화가 반 고흐의 화풍을 모방하여 새로운 그림을 그리는 등 놀라운 결과물들 을 보여주고 있는데,
특히 2018년에는 GAN이 생성한 그림이 크리스티 미술품 경매에서 43만 달 러에 낙찰되기도 했습니다.
GAN은 어떤 방식으로 학습할까요?
GAN은 기존의 인공신경망과는 다르게 두 개의 인 공신경망이 서로 경쟁하며 학습을 진행합니다.
이 과정을 통해 두 모델의 성능은 꾸준히 향상됩니다
| 생성 모델(Generator Model) | 판별 모델 (Discriminator Model) |
| 주어진 데이터와 최대한 유사한 가짜 데이터를 생성 | 진짜 데이터와 가짜 데이터 중 어떤 것이 진짜 데이터인지를 판별합니다. |
| 위조지폐 범은 판별 모델을 속이기 위한 진짜 같은 위조지폐를 만들고 | 판별 모델은 위조지폐범이 만든 위조 지폐를 찾아내기 위해 서로 경쟁적으로 학습 |
🎨 웹툰 이미지 생성이란?
웹툰 이미지 생성은 "회귀"라기보단 "생성 모델(GAN 등)" 이지만,
내부에서는 수많은 픽셀 숫자를 예측하기 때문에 회귀적 요소를 포함하고 있어요!

예를 들어서:
"AI가 웹툰 캐릭터 얼굴을 생성한다"
"선이 깔끔하고 컬러가 조화로운 컷을 만든다"
이건 단순히 숫자 하나를 예측하는 게 아니라,
수천~수만 개의 픽셀값(R, G, B 채널)을 동시에 생성하는 작업이에요.
📌 이미지 생성은 어떤 문제?
→ 생성(Generative) 문제
특히 GAN(생성적 적대 신경망), VAE(변분 오토인코더) 같은 모델들이 많이 쓰입니다.
이들은 다음을 수행하죠:
- "이런 스타일의 캐릭터를 원해" → 그 조건에 맞는 이미지를 샘플링
- 완전히 새로운 이미지를 ‘그려냄’
🤔 그럼 회귀랑은 아무 상관없어?
아닙니다! 일부 과정은 회귀처럼 작동합니다.
- 이미지 생성도 결국은 각 픽셀 값(0~255 사이 숫자) 을 예측하는 것이기 때문에,
- 모델 내부에서는 회귀 모델처럼 픽셀 값 하나하나를 출력하는 구조가 포함됩니다!
예:
CNN 출력층에서 R, G, B 값을 [0~1]로 예측한 뒤 → 255를 곱해서 이미지 완성
이게 바로 회귀적 특성이에요.
🔥 Transformer
지금 우리가 쓰는 GPT, ChatGPT 같은 AI 모델들의 기반이 되는 핵심 기술입니다.
| 과거 모델 (RNN, LSTM) | Transformer |
| 순서대로 입력 처리 (느림) | 전체 문장을 병렬로 처리 (빠름) |
| 과거 정보만 기억 | 앞뒤 문맥 다 파악 |
| 긴 문장 처리 어려움 | 긴 문장도 정확하게 처리 |
Transformer는 특히 Attention 메커니즘을 통해
→ 문장 내에서 **“어떤 단어가 중요한지 스스로 판단해서 집중”**할 수 있게 만들었어요.
📚 계층 정리
🧠 인공지능 (AI)
└── 🧠 머신러닝 (ML)
└── 🔥 딥러닝 (Deep Learning)
└── 🧠 인공신경망 (ANN)
├── ✅ MLP (기초 신경망)
├── ✅ CNN (이미지)
├── ✅ RNN (시퀀스)
├── ✅ LSTM (장기 시퀀스)
└── 🌟 **Transformer (문맥 기반 초거대 모델)**
✅ Transformer도 딥러닝이다! 왜냐하면?
- 딥러닝이란? → **‘층이 많은 인공신경망’**을 이용한 학습 방식
- Transformer도 수십~수백 개의 층(layer)을 쌓아서 학습함 → 완전 딥러닝 맞음!
✅ Transformer도 인공신경망이다! 왜냐하면?
- 입력 → 가중치 → 활성화 함수 → 출력 구조 그대로 사용함
- 단지 기존 신경망(RNN, LSTM)과는 다르게 Attention 기반 구조를 사용함
퍼셉트론이 처음 발표될 당시에는 현재의 딥러닝과 비교도 안 될 정도로 기초적인 수준 임에도 불구하고 큰 화제가 되었습니다. 딥러닝이 상당한 발전을 이룬 지금, 어떤 자세를 가지고 인공지능의 발전을 지켜보면 좋을지 토론해 봅니다.
🔍 1. 기대와 현실을 구분하는 비판적 시각
- 딥러닝 기술은 놀랍게 발전했지만, 모든 문제에 만능 해결책은 아님을 인식해야 합니다.
- 예: 설명 가능성(XAI), 데이터 의존성, 에너지 비용 문제
- 기술적 한계를 직시하고, 그 너머를 고민하는 태도가 필요합니다.
“기술을 찬양하기보다, 기술이 풀지 못하는 문제에 질문을 던져야 한다.”
🧠 2. 기초에 대한 꾸준한 관심
- 퍼셉트론처럼 지금은 단순해 보이는 아이디어도 당시에는 혁신이었습니다.
지금도 기초 연구가 미래를 바꿀 수 있습니다.- 기초 수학, 통계, 알고리즘에 대한 공부는 언제나 유효합니다.
“현상의 이면을 이해하려는 태도는, 시대를 뛰어넘는 인공지능 연구자의 자질입니다.”
🔄 3. 기술 발전이 아닌 ‘문제 해결’에 초점 맞추기
- 모델의 성능 향상보다, 실제로 사람들에게 어떤 가치를 줄 수 있느냐가 중요합니다.
- 예: 의료 AI, 기후 분석, 교육용 챗봇 등 사회적 가치에 기여
- 기술이 ‘도구’라는 인식이 필요합니다. 도구는 목적이 아니라 수단이죠.
🤝 4. 윤리적 감수성과 책임 있는 개발
- AI가 현실에 영향을 미치는 지금, 공정성, 프라이버시, 책임성을 함께 고민해야 합니다.
- 예: 얼굴 인식의 편향, 자동화의 일자리 문제, 딥페이크 등
“기술을 통제하는 것은 기술이 아닌, 그것을 다루는 우리의 가치관입니다.”
🌱 5. 끊임없는 학습과 유연한 태도
- AI는 하루가 다르게 발전하는 영역이므로, 지속적인 학습과 열린 태도가 중요합니다.
- 최신 논문 읽기, 커뮤니티 참여, 프로젝트 실험 등
- 특정 기술에 집착하기보다, 문제와 상황에 맞는 최적의 접근법을 유연하게 선택해야 합니다.
🎯 결론
“퍼셉트론 하나로 세상을 바꿀 수 있다고 믿었던 그 시절처럼,
지금의 딥러닝 역시 열정은 가지되 맹신은 경계해야 한다.”
기술의 파도 위에서 균형 있게 서기 위해선, 비판적 사고 + 끊임없는 학습 + 윤리적 책임이 조화를 이뤄야 한다고 생각합니다.
요즘 학계에는 딥러닝 기술의 부흥기라고 해도 될 정도로 수많은 관련 논문이 쏟아져 나 오고 있습니다. 주제는 새로운 기술에 대한 것부터 기술을 이용한 효과의 증명까지 다양 합니다. 이러한 연구 성과들을 상황과 목적에 맞게 잘 활용할 수 있는 방안은 무엇이 있 을지 토론해 봅니다.
🔍 1. 논문 큐레이션 및 주제별 분류
- 딥러닝 관련 논문이 워낙 많기 때문에 주제별로 정리된 큐레이션 플랫폼을 적극 활용하거나, 내부적으로 자체 분류 시스템을 만드는 것이 좋습니다.
- 예: CV(컴퓨터비전), NLP(자연어처리), RL(강화학습) 등 분야별 정리
- 논문 읽기 스터디나 세미나에서 키워드 중심 정리
📚 2. 기술의 재현 및 벤치마크
- 논문에서 제안한 모델이나 방법론을 직접 구현하고 기존 문제에 적용해보는 실험이 필요합니다.
- GitHub 등에서 제공되는 코드를 활용
- 자체 벤치마크 데이터로 실험해보고, 실제 성능을 체감
🎯 3. 적용 가능성 평가
- 실용화 가능성을 검토하여 해당 기술이 우리 문제에 적합한지 판단합니다.
- 과적합 여부, 연산량, 데이터 요구량 등 실무 조건과의 간극 평가
- 연구의 목적이 현실적 문제 해결에 부합하는지 검토
🧠 4. 기술 융합 및 문제 맞춤화
- 여러 딥러닝 기술을 결합하거나 변형하여 자체 문제에 맞는 하이브리드 모델을 만들어보는 접근도 중요합니다.
- 예: Transformer + CNN, LLM + Knowledge Graph 등
- 논문 아이디어를 실무에 맞게 변형, 튜닝
🤝 5. 산학 협력 및 오픈 커뮤니티 참여
- 대학 및 연구기관과 협력하여 논문을 더 깊이 이해하거나 공동 프로젝트 진행
- HuggingFace, PapersWithCode, Arxiv Sanity 등 커뮤니티 플랫폼을 통해 트렌드 파악
📊 6. 내부 데이터/업무와의 매핑
- 내부 데이터를 기반으로 딥러닝 기술을 테스트해보고 업무에 바로 적용할 수 있는지 파일럿 프로젝트로 검증합니다.
- 예: 고객 이탈 예측에 최신 LSTM 논문 활용
- 챗봇에 최신 NLP 논문 반영 등
✨ 결론
딥러닝 논문은 '읽는 것'보다 '써먹는 것'이 훨씬 중요합니다.
논문을 단순히 소비하는 데서 그치지 않고, 문제 해결의 도구로 삼아 적극적으로 실험하고 평가하는 자세가 필요합니다.
'학습 기록 (Learning Logs) > Today I Learned' 카테고리의 다른 글
| 📘 8장. MLFQ (Multi-Level Feedback Queue) (0) | 2025.04.07 |
|---|---|
| 📘 7장. 스케줄링 (0) | 2025.04.07 |
| Done is better than perfect (0) | 2025.04.03 |
| 유튜브에서 자막 퍼오기 (0) | 2025.04.03 |
| 채팅 서버 (0) | 2025.04.01 |
