동영상 출처: https://www.youtube.com/watch?v=isj4sZhoxjk&t=16233s
15 주소 변환의 원리
프로세서, 주소공간
--- 동적 재배치
--- 베이스 레지스터, 바운드(limit)레지스터
--- mmu
--- 프로세스 구조체, 프로세스 제어블럭 PCB
---- 내부 단편화 발생, 비효율적
16-> 세그멘테이션
--- 물리 메모리 이용률을 높이고, 내부 단편화 방지
17 빈공간 관리
--- 분할, 병합
--- 개별 리스트, 슬랩 할당기, 객체 캐시
--- 버디 할당
메모리 보호
연속 메모리 할당
--- 외부 단편화 문제 발생 -> 해결방법: 페이징
18 페이징
--- 논리 세그먼트: 코드, 힙, 스택
--- 고정 크기 단위
--- 페이지, 페이지 프레임
--- 페이지 테이블, 역 페이지 테이블
----- protection bit, present bit, reference bit
19 페이징 테이블
--- TLB
--- 선형 페이지 테이블
--- 역 페이지 테이블
--- 페이지 테이블을 디스크로 스와핑
20 선형 페이지 테이블
--- 하이브리드
--- 멀티 레벨 페이지 테이블
21 물리 메모리 크기의 극복: 메커니즘
--- 가상 사용, 메모리 오버레이
--- 스왑 공간
--- presnet bit
--- 페이지 폴트
--- page replace policy
22 물리 메모리 크기의 극복: 정책
--- 캐시 관리
---- FIFO, 무작위 선택, LRU
---- Thrashing
15 주소 변환의 원리
● 프로세서와 주소 공간
프로세서는 항상 0번 주소부터 실행하려고 해
근데 모든 프로그램이 0번부터 실행하면 부딪히겠지?
→ 그래서 가상 주소 공간을 줘! 실제 메모리 주소는 OS가 바꿔줌.
● 동적 재배치 (Dynamic Relocation)
프로그램이 실행될 때마다 메모리 어디에 올릴지는 매번 다름
→ 그때그때 위치를 바꿔서 올림 (동적으로 재배치)
📌 예:
- 프로그램은 “0번 주소”에 있다고 생각하지만
- 실제 메모리에는 500번 주소에 올릴 수도 있어.
● MMU (Memory Management Unit)
위 과정을 자동으로 처리해주는 하드웨어
- 가상 주소 → 물리 주소 변환
- 베이스 + 가상 주소 = 물리 주소
- 바운드 체크도 같이 해줌
📌 CPU는 MMU 덕분에 “내가 0번부터 쓰는 줄 아는” 착각 속에 산다!
● 프로세스 구조체, PCB (Process Control Block)
운영체제가 각 프로세스를 관리하기 위한 구조체
- 여기 안에 “이 프로세스는 어디 메모리에 있음” 등의 정보가 담겨 있음
- 스케줄링, 문맥 전환 시에도 사용됨
● 내부 단편화 (Internal Fragmentation)
메모리를 고정된 크기로 나눠 쓸 때,
- 프로그램이 93KB인데 100KB 블록에 넣으면
- 남은 7KB가 쓸 수 없는 공간이 돼버림 → 비효율적!
15. 주소 변환의 원리



베이스 주소 : 15000번지
논리 주소: 100만큼 떨어져있다.
메모리 15100번지를 삭제함.
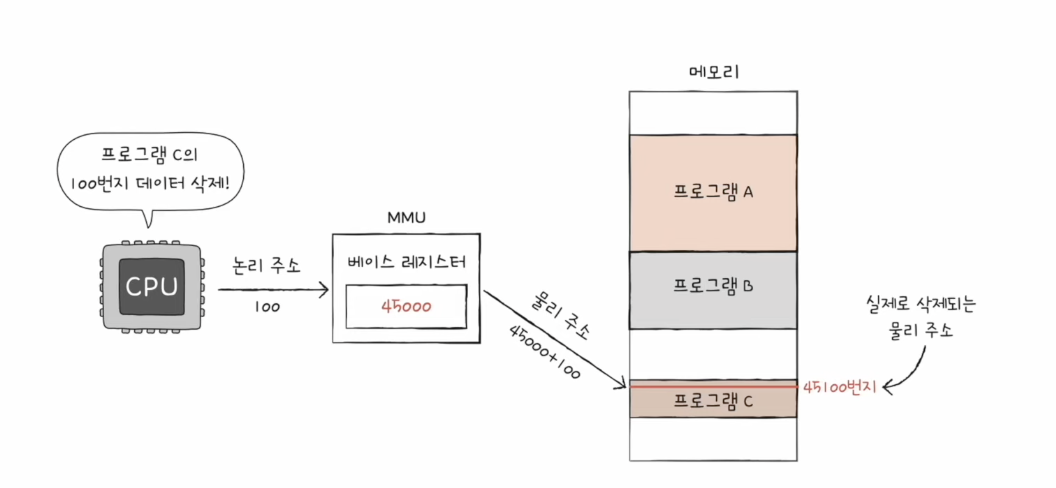
베이스 주소: 45000번지
논리 주소: 100 떨어짐
메모리 45100번지를 삭제함
16. 세그멘테이션 (Segmentation)
👉 프로그램을 의미 있는 조각(세그먼트) 단위로 나누는 주소 관리 방식
🔹 왜 생겼을까?
- 페이징은 고정 크기 페이지로 쪼개니까 내부 단편화 생김 😩
- 그래서 “논리적으로 나누고, 크기도 유동적으로 하자!” → 세그멘테이션
📚 쉽게 비유:
프로그램을 “책”이라고 하면,
세그멘테이션은 "서문, 목차, 1장, 2장..." 처럼 논리 단위로 나누는 것이야.
✅ 장점:
- 내부 단편화 방지
- 의미 있는 단위로 나뉘어 있어 관리가 쉬움
17. 빈 공간 관리 (메모리 할당 전략)
세그먼트/페이지가 반환되고 난 후 생기는 빈 공간을 어떻게 다시 활용할까?

🧩 1. 분할, 병합
- 메모리 공간을 필요에 따라 쪼개고(분할)
- 사용 후 다시 붙여서 큰 덩어리로 만듦(병합)
📌 비유:
냉장고 공간을 통째로 쓰다가 남는 칸을 나눠쓰고, 다시 붙여 쓰는 느낌
🧱 2. 개별 리스트 방식 (Free List)
크기별로 빈 공간 목록을 따로 관리
📌 예: malloc(8KB) 요청 → 8KB 리스트에서 하나 꺼내줌
👉 관리 편하고 빠름!

⚒️ 3. 슬랩 할당기 (Slab Allocator)
커널에서 자주 쓰는 **작은 객체(구조체)**에 최적화된 방식
- 미리 같은 객체를 묶어놓고 할당/해제함
📌 비유:
달걀판(슬랩)에 계란을 하나씩 넣고 빼는 느낌
📦 4. 객체 캐시 (Object Cache)
한 번 사용한 메모리를 다시 재사용하기 위해 캐시 형태로 보관
- 예를 들어, 100개 구조체를 썼다면, 해제해도 바로 버리지 않고 다시 활용!
🧠 5. 버디 시스템 (Buddy Allocator)
2의 거듭제곱 크기로 메모리를 나누고
- 요청 크기에 맞춰 가장 가까운 버디를 나눔
📌 예:
- 64KB 요청 → 128KB 블록을 64KB + 64KB로 나눔
- 반납하면 둘이 합쳐서 다시 128KB로 병합 가능!
👉 빠르고 정리하기 쉬움 (병합도 쉬움)
메모리 보호



메모장의 실제 물리 주소는 1000번지~ 1999번지까지임
베이스 주소: 1000번지
논리 주소: 1500
접근하려는 주소: 2500번지 --> 1000번지~ 1999번지 벗어남
결과: 인터넷 브라우저에 100을 저장함

물리 주소: 2000번지~ 2999번지 까지 가능함
베이스 주소: 2000번지
논리 주소: 1100
접근하려는 주소: 3100번지 ---> 범위 벗어남
연속 메모리 할당
프로세스에 연속적인 메모리 공간을 할당하면 문제가 발생한다.

프로세스는 메모리의 빈 공간에 할당 되어야한다.
빈공간이 여러개라면?

프로세스 3개, 빈공간 3개... 인 경우
| 최초 적합 | 최적 적합 | 최악 적합 |
| 빈 공간 발견 하면 바로 넣음 검색 최소화 빠른 할당 |
운영체제가 빈 공간을 모두 검색 후.. 가장 효율적인 공간에 할당 |
운영체제가 빈 공간을 모두 검색 후.. 가장 큰 공간에 할당 |
 |
 |
 |
연속 메모리 할당의 두가지 문제점
- 외부 단편화 발생
- 물리 메모리 보다 큰 프로세스 실행 불가

외부 단편화
티끌모아 태산
프로세스들이 실행되고, 종료되길 반복하면서, 메모리 사이에 빈 공간이 발생
프로세스를 빈공간에 할당하기 어려울 만큼, 작은 메모리 공간들로 인해서 메모리가 낭비되는 현상
외부 단편화가 발생하는 근본적인 문제 : 각기 다른 프로세스가 메모리에 연속적으로 할당되었기 때문이다.

| 최초 | 최적 |
 |
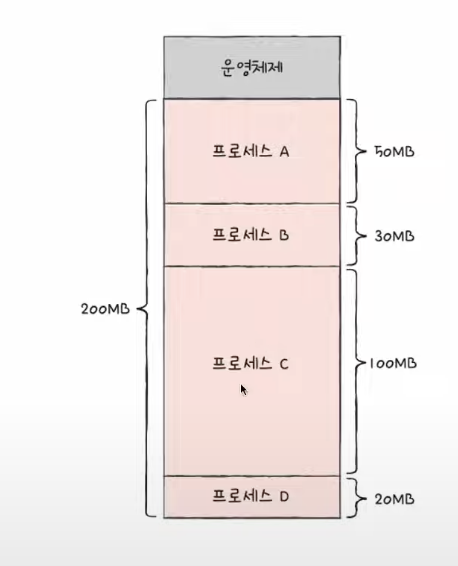 |
| 상황1 : B, D 프로세스 실행 끝 남은 공간은? 50MB 빈공간에 50MB를 넣을 수 있는가? NO!! 외부 단편화 |
외부 단편화 발생 |
 |
 |
외부 단편화 - 해결 방법
| 메모리 압축 메모리 조각 모음 |
 여기저기 흩어져 있는 빈 공간들을 하나로 모으는 방식 프로세서를 적당히 재배치시켜, 흩어져있는 작은 공간을 하나의 큰 공간으로 만듦 부작용이 있다. 합치는 과정에서, 재배치를 하는 과정에서 오버헤드를 만든다. 최소한의 오버헤드를 만드는 방법이 애매하다... |
| 가상화 메모리 기법 |
실행하고자 하는 프로그램을 일부만 메모리에 적재하여, 실제 물리 메모리 보다 더 큰 프로세스를 실행할 수 있게 하는 기술 |
| 가상화 메모리 기법 - 페이징 |
프로세스를 일정 크기로 자른다. 일정한 크기 10MB  메모리에 불연속적으로 할당 할 수 있게 한다. 이렇게 흩어져있으면 문제가 발생한다 |
| 가상화 메모리 기법 - 세그멘테이션 |
18. 페이징
가상 메모리 관리 기법
프로세스의 논리 주소 공간을 페이지 라는 일정한 크기로 자른다
메모리의 물리 주소 공간을 프레임이라는 페이지와 동일한 크기로 자른다
페이지를 프레임 할당
외부 단편화 발생하지 않음

페이징 문제 발생
cpu 입장에서 다음에 실행할 명령어 위치를 찾기 어려움
프로세스를 이루는 페이지가 어느 프레임에 적재되어있는지 cpu가 일일이 알기란 어렵다
프로세스가 메모리에 불연속적으로 배치되어있다면, cpu 입장에서는 순차적으로 실행할 수가 없다.
페이징 문제 해결 -> 페이지 테이블

페이징
물리 메모리보다, 큰 프로세스를 실행할 수 있지만, 물리 메모리의 크기는 한정되어있다.
페이징 문제 해결
1) 알고리즘: 페이지 교체 알고리즘
2) 프레임 할당
요구 페이징
- 처음부터 모든 페이지를 적재하지 않고 필요한 페이지만을 메모리에 적재하는 기법
- 요구되는 페이지만 적재하는 기법
- CPU가 특정 페이지에 접근하는 명령어를 실행한다.
- 해당 페이지가 현재 메모리에 있을 경우 (유효 비트가 1일 경우) CPU는 페이지가 적재된 프레임에 접근한다.
- 해당 페이지가 현재 메모리에 없을 경우(유효 비트가 0일 경우) 페이지 폴트가 발생한다.
- 페이지 폴트 처리 루틴은 해당 페이지를 메모리로 적재하고 유효 비트를 1로 설정한다.
- 다시 ①번을 수행한다.
페이지에서 스와핑
프로세서 단위가 아님(스왑 인, 스압 아웃)
페이지 단위로 사용(페이지 인, 페이지 아웃)
메모리에 적재될 필요없는 페이지들은 보조기억장치로 페이지 아웃
실행에 필요한 페이지들은 메모리로 페이지 인

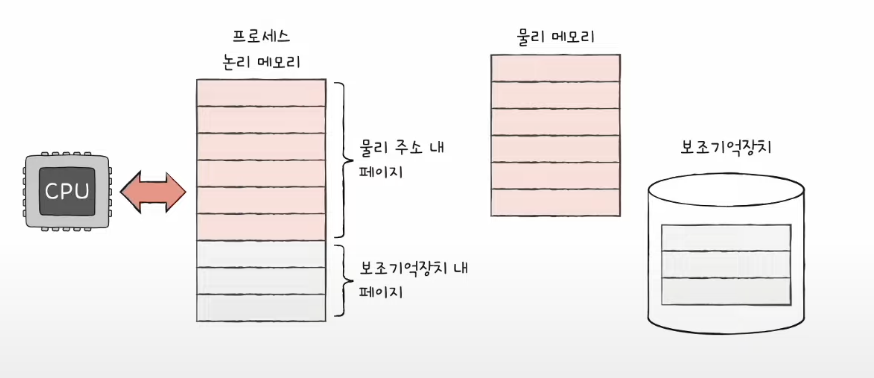
프로세스를 실행하기 위해, 모든 페이지가 메모리 적재될 필요가 없다.
== 물리 메모리보다 큰 프로세스를 실행시킬 수 있다.
19. 페이지 테이블(Page Table)
물리 주소: 실제 메모리 주소
논리 주소: cpu가 바라보는 주소
물리 주소에 불연속적으로 배치되더라도, 논리주소에는 연속적으로 배치되도록 하는 방법
페이지 번호와 프레임 번호를 짝지어주는 일종의 이정표

프로세스 마다, 페이지 테이블이 존재함
Page Table 장점:
1) 자원 공유
전통적인 관점
process 기본적으로 자원을 공유하지 않는다.== fork()
-> 부모 process가 적대된 별도의 공간에서 -> 자식 process가 통쨰로 복제 되어 적재됨
->자식 process 생성 시간 지연, 중복 메모리 -> 메모리 낭비

쓰기 복사
부모 process와 동일한 자식 process가 복제되어 생성되면 == fork() 호출
자식 process는 부모 process와 동일한 프레임을 가리킴(쓰기 작업이 없다면 이 상태를 유지)

부모와, 자식 중에서 하나라도 쓰기 작업을 하게 되면
해당 페이지는 별도의 공간으로 복제 -> process 생성 시간 절약, 메모리 절약

Page Table 단점: 내부 단편화
페이지 크기가 10KB, process 크기 108KB
2KB: 내부 단편화
하나의 페이지 크기보다 작은 크기로 발생

페이지 크기
getconf PAGESIZE

계층적 페이징 == 다단계 페이징
process table의 크기는 생각보다 작지 않다
process를 이루는 모든 page table entry를 메모리에 두는 것은 큰 낭비
process를 이루는 모든 page table entry를 항상 메모리에 유지 않을 방법을 찾아야함


outer page table은 메모리에 유지한다.
계층적 페이징을 이용하는 환경에서의 논리 주소


계층적 페이징은 3단계, 4단계.. 그 이상으로도 계층이 구성될 수 있다.
계층이 많아지게 되면, page fault exception이 발생했을 때 메모리를 참조해야하는 횟수가 그만큼 많아진다.
PTBR(Process Table Base Register)
process 마다 페이지 테이블이 존재
각 페이지 테이블은 CPU 내의 process table base register를 가리킨다
즉. 각 페이지 테이블의 주소를 저장하고 있음

근데 메모리에 페이지 테이블이 다 저장되어있는게 좋을까?
아니지!
당장 안쓰는데 메모리가 부족하겠지.
페이지 테이블이 메모리에 있으면?
메모리 접근 시간이 두 배로 증가
메모리에 접근하는 시간은 register, cache 보다 memory가 느리기 때문이다
1) 페이지 테이블 참조하기 위해 한 번
2) 페이지를 참조하기 위해 한 번

TLB(Translation Lookaside Buffer)
CPU 곁에 Page Table의 Cache Memory
Page Table의 일부를 가져와 저장


cache hit -> TLB에 논리 주소가 있다면 -> 메모리에 접근 1번
cache miss -> TLB에 논리 주소가 없다면 -> 메모리에 접근 2번
TLB에서 논리주소 -> 물리주소 변환 방법
특정 주소에 접근하려면 뭐가 필요함?
- 어떤 페이지(논리 주소), 프레임(물리 주소)에 접근하고 싶은지
- 접근하려는 주소가 페이지(논리 주소), 프레임(물리 주소)에서 얼마나 떨어져 있는지

- 페이지 번호 : 어떤 페이지(논리 주소), 프레임(물리 주소)에 접근하고 싶은지
- 변위 : 접근하려는 주소가 페이지(논리 주소), 프레임(물리 주소)에서 얼마나 떨어져 있는지


문제


Page Table Entry 페이지 테이블 엔트리
page table의 각각의 ROW
가지고 있는 정보: 페이지 번호, 프레임 번호.. etc
etc에 뭐가 들어있는지 살펴봅시다..

Valid bit
현재 해당 페이지에 접근 가능한지 여부

유효 비트가 0인 페이지에 접근하려고 하면?
페이지 폴트(page fault)라는 인터럽트 발생
페이지 폴트(page fault) : 내가 접근하려는 페이지가 메모리에 적재되어있지 않음
인터럽트 처리 과정
- CPU는 기존의 작업 내역을 백업합니다.
- 페이지 폴트 처리 루틴을 실행합니다.
- 페이지 처리 루틴은 원하는 페이지를 메모리로 가져온 뒤 유효 비트를 1로 변경해 줍니다.
- 페이지 폴트를 처리했다면 이제 CPU는 해당 페이지에 접근할 수 있음
보호 bit
페이지 보호 기능을 위해 존재하는 bit
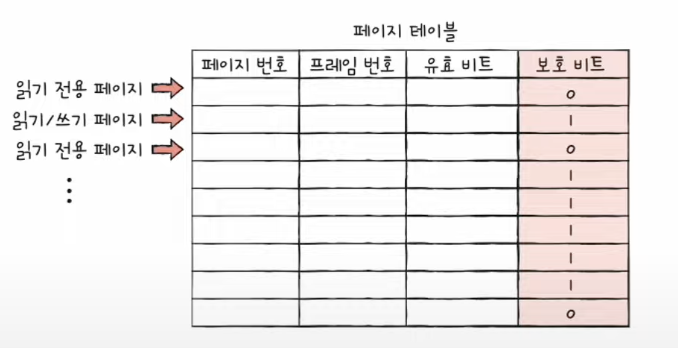

어떤 페이지는 읽기만 가능해야하거나 ----------------> read only
어떤 페이지는 읽기/쓰기 둘다 가능하거나
Referrence bit
CPU가 이 페이지에 접근한 적이 있는 지 여부
어떤 페이지가 메모리로 적재된 이후에 CPU에 한 번이라도 읽거나 쓴 페이지는 참조 비트가 1로 세팅된다.
어떤 페이지가 메모리에 적재된 이후에 CPU에서 한 번도 방문한 적이 없었으면 참조 비트가 0

Dirty bit (수정 bit)
CPU가 이 페이지에 데이터를 쓴 적이 있는지 여부
1: 한번이라도 변경된 적이 있는 페이지
0: 한번도 변경된 적이 없는 페이지

SWAPING과 관련이 있다.
이 페이지가 메모리에서 사라질 때, 보조기억장치에 쓰기 작업을 해야하는지, 할 필요가 없는 지를 판단하기 위해 존재함.

CPU가 페이지A를 읽기만 했다(이미 메모리에 올려놓음), 하지만 변경한 적이 없으면
메모리에 있는 내용 == 보조 기억 장치 내용 동일하다!!

메모리에서 페이지A에 1 == 수정되었으면 --> 보조기억장치에 변경된 내용으로 저장!
스와핑

지금 안쓰는 것을 정리하고 -> 스왑 아웃 -> 보조기억장치로 보내버렷!
당장 사용하는 것을 가져옴 -> 스왑인

왔다갔다 적재하면서 사용한다.
프로세스들이 요구하는 메모리 공간 크기 > 실제 메모리 크기 경우에 메모리를 동시에 실행시키게 한다.
스왑을 할 수있는 크기는 free로 확인이 가능하다.

주기억장치 == main memory




비교 출처: https://youtu.be/CPOcSGgSxiQ?si=0bW6RYuIEUDjzh7q
ram 출처: https://www.youtube.com/watch?v=HdqQqefo2lU
rom 출처: https://www.youtube.com/watch?v=1GREaNW21XM
| RAM (Random Access Memory) | Read-Only Memory (ROM), |
 |
 |
 |
        |
 |
 |
 |
 |
 |
 |
| 메모리에 있는 모든 단어에 접근하는데 걸리는 시간이 동일하다 | |
 |
 |
     |
   |
| 휘발성 장치 == volatile memory 사용자가 자유롭게 내용을 읽고 쓰고 지울 수 있는 기억장치 기억된 데이터를 읽을 수도 있고, 다른 데이터를 기억시킬 수도 있는 메모리 응용 프로그램, 운영체제 등을 불러와 CPU가 작업할 수 있도록 하는 공간 전원이 꺼지면 가지고 있던 데이터가 전부 사라짐 실행하고 있는 파일을 보조기억장치에 수시로 저장 |
비휘발성 장치 == non-volatile memory 읽기 전용 메모리 한번 기록한 정보가 전원 유지와 상관없이 (반)영구적으로 기억되며, 삭제, 수정이 불가능한 기억장치 오직 기억된 데이터를 읽기만 가능한 장치 장치에 존재하는 데이터는 컴퓨터의 전원이 꺼져도 사라지지 않고 그대로 유지 |
| java에서 volatile 키워드가 붙은 변수는 메인 메모리(Main Memory) 에 항상 저장 |


Cache

보조기억장치
| HDD (Hard Disk Driver) | SSD (Solid State Driver) |
 |
 |
19. 페이징 테이블 관련
페이징이란?
큰 프로그램을 작은 '페이지(Page)'라는 단위로 쪼개서 메모리에 올리는 방식이야. 그걸 어디에 올렸는지 기억해두는 게 페이지 테이블이야!
● TLB (Translation Lookaside Buffer)
페이지 테이블을 빠르게 접근하기 위한 캐시
- 우리가 메모리 주소를 자주 조회하니까, 최근에 접근한 페이지 주소를 캐시에 저장해두면 훨씬 빨라져!
- 마치 네가 자주 가는 사이트를 북마크 해두는 것처럼!
● 선형 페이지 테이블 (Linear Page Table)
페이지 번호가 커질수록 테이블도 커짐 (1:1 매핑)
- 그냥 줄줄이 주소를 저장하는 구조.
- 페이지가 많아지면 테이블도 너무 커져서 비효율적.
● 역 페이지 테이블 (Inverted Page Table)
프레임 중심의 테이블 (메모리에 누가 있는지를 기록)
- 전체 물리 메모리에 누가 올라와 있는지 적어두는 방식이야.
- 반대로 검색하니까 속도는 느릴 수 있지만 메모리 절약엔 좋아!
● 페이지 테이블을 디스크로 스와핑
메모리가 부족하면 페이지 테이블 일부를 디스크로 보냄
- 메모리에 전부 다 못 올려서 필요한 것만 올리고, 나머진 디스크에 잠시 보관
- 마치 너무 두꺼운 책이라 가방에 일부만 넣고 나머진 집에 두는 느낌!
20. 선형 페이지 테이블의 개선
● 하이브리드
TLB + 페이지 테이블의 조합
- 자주 쓰는 건 TLB에, 나머진 페이지 테이블에
- 성능과 메모리 사용을 적절히 조화시킨 구조
● 멀티 레벨 페이지 테이블 (다단계 페이지 테이블)
선형 테이블을 계층으로 나눠서 필요한 부분만 메모리에 올림
- 책의 목차처럼,
1권 → 1-1장, 1-2장, … 이렇게 나누는 것 - 메모리 절약에 효과적!
- 예: 2단계면 상위 테이블 → 하위 테이블 → 실제 주소
그림 출처: https://www.youtube.com/watch?v=Z4kSOv49GNc
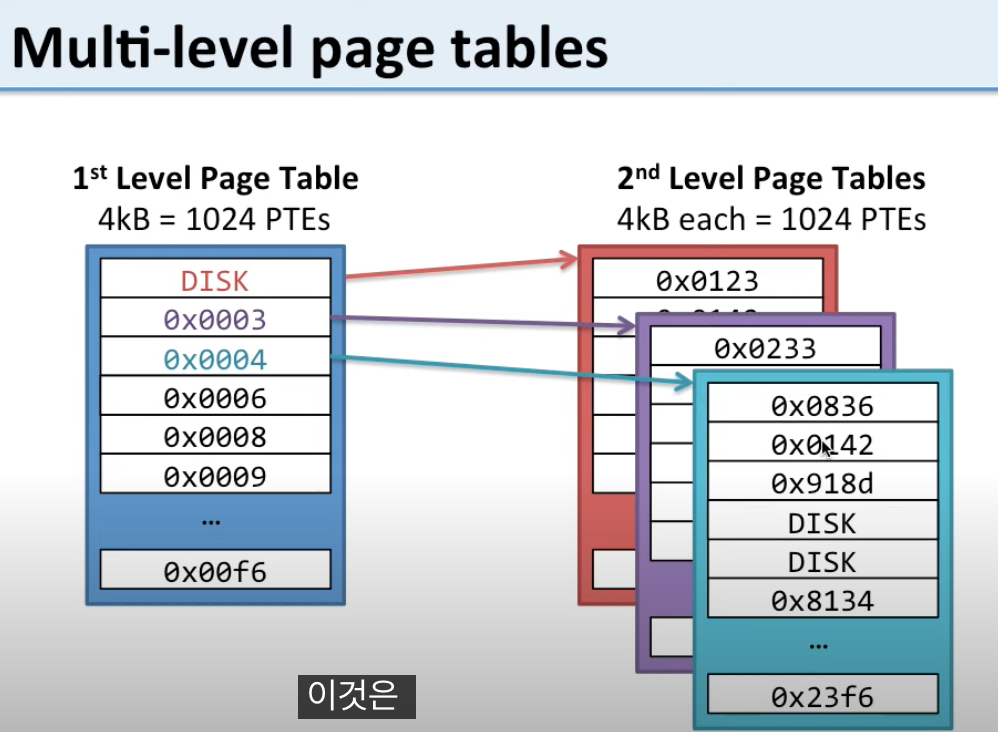





- 선형 → 단순하지만 크기 커짐
- 멀티레벨 → 크기를 줄이기 위해 계층화
- 역 페이지 → 메모리 기준으로 누구 있는지 기록
- TLB → 자주 쓰는 거 빠르게 접근
- 디스크 스와핑 → 메모리 부족 시 임시로 보냄
요즘 OS는 어떤걸 쓸까?
운영체제별 핵심 구조 비교
| OS | 페이지 구조 | TLB | 스와핑 방식 | 기타 특징 |
| Windows | 4단계 페이지 테이블 | 있음 | pagefile.sys | 유저 설정 가능한 스왑 크기 |
| macOS | 4단계 (ARM) | 있음 | SSD + 압축 메모리 | 매우 빠른 스왑 처리 (M1) |
| Linux | 4단계 (x86_64) | 있음 | swap 파일/파티션 사용 | huge pages 지원 |
1. Windows (윈도우)
- 멀티 레벨 페이지 테이블 (Multi-level Paging)
- x86/x64 아키텍처에서는 4단계 페이지 테이블 구조 사용 중 (예: PML4 → PDPT → PD → PT → Page)
- TLB (Translation Lookaside Buffer)
- 자주 접근하는 페이지 주소는 TLB에 캐싱하여 속도 향상
- 스와핑
- 사용하지 않는 페이지는 디스크로 pagefile.sys에 저장해서 메모리 확보
2. macOS (맥)
- macOS는 XNU 커널 기반이고, 역시 멀티 레벨 페이지 테이블 + TLB 사용
- 최신 M1/M2 칩 기반의 ARM 아키텍처는 ARMv8 구조의 4단계 페이징 구조 사용
- 페이지 캐시와 압축 메모리 등도 활용해서 효율을 극대화
- 디스크 스와핑도 가능 (메모리 압축 + SSD 스왑 영역 활용)
3. Linux
- 멀티 레벨 페이지 테이블
- x86_64 기준 4단계 구조 (PML4 → PDPT → PD → PT)
- ARM 기반에서는 macOS처럼 4~5단계까지도 가능
- TLB
- 하드웨어가 관리하고, 소프트웨어에서는 flush_tlb() 등으로 제어 가능
- 스와핑 (Swapping)
- 메모리가 부족하면 swap partition 또는 swap file로 디스크에 페이지 저장
- swapon, vmstat, top 등으로 확인 가능
- huge pages (HugeTLB)
- 성능 최적화를 위해 큰 페이지(예: 2MB, 1GB)를 사용하는 옵션도 존재
'학습 기록 (Learning Logs) > Today I Learned' 카테고리의 다른 글
| LLM (0) | 2025.04.17 |
|---|---|
| ObjectOptimisticLockingFailureException (0) | 2025.04.15 |
| 분산 시스템 장애 복구 (0) | 2025.04.14 |
| DB (0) | 2025.04.14 |
| Colab에서 Stable Diffusion 실행하기 (0) | 2025.04.12 |
